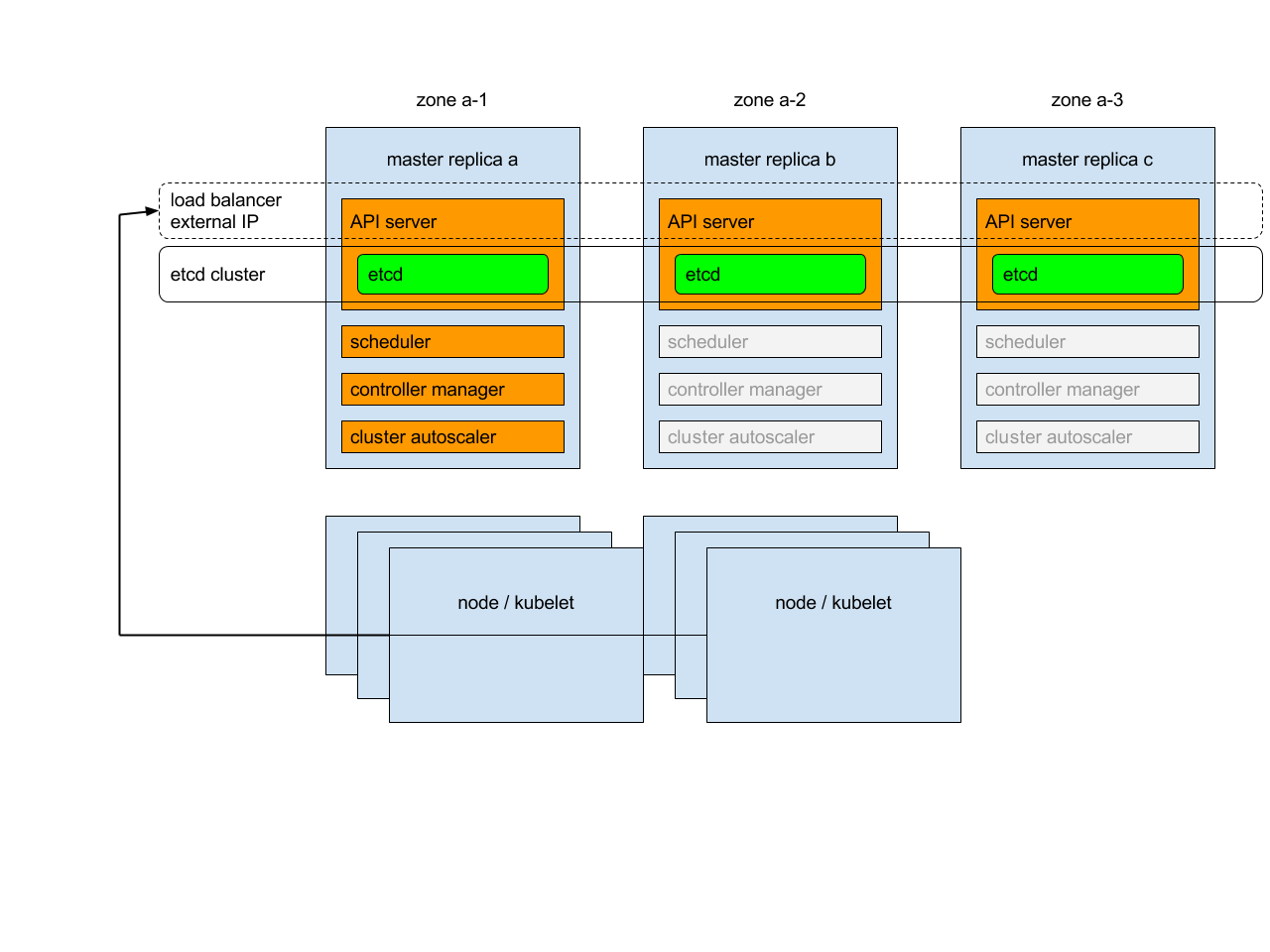
Bagian dokumentasi Kubernetes ini berisi halaman-halaman yang perlihatkan
bagaimana melakukan setiap tugas (task). Halaman tugas menunjukkan cara melakukan
satu hal saja, biasanya dengan memberikan urutan langkah pendek.
Antarmuka Pengguna Berbasis Web (Dashboard)
Melakukan deploy dan mengakses dashboard berbasis web untuk
membantu kamu mengelola dan memantau aplikasi yang dimasukkan ke dalam container
di Kubernetes.
Menggunakan Baris Perintah kubectl
Instalasi dan konfigurasi utilitas baris perintah kubectl yang digunakan untuk
mengelola secara langsung klaster Kubernetes.
Mengkonfigurasi Pod dan Container
Melakukan tugas konfigurasi yang umum untuk Pod dan Container.
Menjalankan Aplikasi
Melakukan tugas manajemen aplikasi secara umum, seperti rolling updates, memasukkan
informasi ke dalam Pod, dan penskalaan Pod secara horisontal.
Menjalankan Job
Menjalankan Job dengan menggunakan pemrosesan paralel.
Mengakses Aplikasi dalam Klaster
Mengkonfigurasi load balancing, port forwarding, atau membangun firewall
atau konfigurasi DNS untuk mengakses aplikasi dalam sebuah klaster.
Monitoring, Logging, dan Debugging
Mengatur monitoring (pemantauan) dan logging (pencatatan) untuk memecahkan
masalah klaster atau melakukan debug (pelacakan) aplikasi yang dikontainerisasi.
Mengakses API Kubernetes
Mempelajari berbagai metode untuk mengakses API Kubernetes secara langsung.
Menggunakan TLS
Mengkonfigurasi aplikasi kamu untuk percaya dan menggunakan klaster Certificate
Authority (CA).
Mengelola Klaster
Mempelajari tugas umum untuk mengelola klaster.
Mengelola Aplikasi yang Stateful
Melakukan tugas umum untuk mengelola aplikasi yang Stateful, termasuk
penskalaan, penghapusan, dan debugging StatefulSets.
Daemon Klaster
Melakukan tugas-tugas umum untuk mengelola DaemonSet, seperti melakukan rolling
updates.
Mengelola GPU
Mengkonfigurasi dan menjadwalkan GPU NVIDIA untuk digunakan sebagai sumber daya
oleh Node dalam sebuah klaster.
Mengelola HugePages
Mengkonfigurasi dan menjadwalkan HugePages sebagai sumber daya yang dapat
dijadwalkan dalam sebuah klaster.
Peralatan untuk melakukan instalasi Kubernetes dalam komputer kamu.
kubectl
Perangkat baris perintah Kubernetes, kubectl,
memungkinkan kamu untuk menjalankan perintah pada klaster Kubernetes.
Kamu dapat menggunakan kubectl untuk menerapkan aplikasi, memeriksa dan mengelola sumber daya klaster,
dan melihat log (catatan). Untuk informasi lebih lanjut termasuk daftar lengkap operasi kubectl, lihat
referensi dokumentasi kubectl.
kubectl dapat diinstal pada berbagai platform Linux, macOS dan Windows.
Pilihlah sistem operasi pilihan kamu di bawah ini.
kind memberikan kamu kemampuan untuk
menjalankan Kubernetes pada komputer lokal kamu. Perangkat ini membutuhkan
Docker yang sudah diinstal dan
terkonfigurasi.
Halaman Memulai Cepatkind
memperlihatkan kepada kamu tentang apa yang perlu kamu lakukan untuk kind
berjalan dan bekerja.
Seperti halnya dengan kind, minikube
merupakan perangkat yang memungkinkan kamu untuk menjalankan Kubernetes
secara lokal. minikube menjalankan sebuah klaster Kubernetes dengan
satu node saja dalam komputer pribadi (termasuk Windows, macOS dan Linux)
sehingga kamu dapat mencoba Kubernetes atau untuk pekerjaan pengembangan
sehari-hari.
Kamu bisa mengikuti petunjuk resmi
Memulai!minikube jika kamu ingin fokus agar perangkat ini terinstal.
Kamu dapat menggunakan kubeadm
untuk membuat dan mengatur klaster Kubernetes.
kubeadm menjalankan langkah-langkah yang diperlukan untuk mendapatkan klaster
dengan kelaikan dan keamanan minimum, aktif dan berjalan dengan cara yang mudah
bagi pengguna.
Instalasi kubeadm memperlihatkan tentang bagaimana melakukan instalasi kubeadm.
Setelah terinstal, kamu dapat menggunakannya untuk membuat klaster.
Kubectl adalah alat baris perintah (command line tool) Kubernetes yang digunakan untuk menjalankan berbagai perintah untuk klaster Kubernetes. Kamu dapat menggunakan kubectl untuk men-deploy aplikasi, mengatur sumber daya klaster, dan melihat log. Daftar operasi kubectl dapat dilihat di Ikhtisar kubectl.
Sebelum kamu memulai
Kamu harus menggunakan kubectl dengan perbedaan maksimal satu versi minor dengan klaster kamu. Misalnya, klien v1.2 masih dapat digunakan dengan master v1.1, v1.2, dan 1.3. Menggunakan versi terbaru kubectl dapat menghindari permasalahan yang tidak terduga.
Menginstal kubectl pada Linux
Menginstal program kubectl menggunakan curl pada Linux
Untuk mengunduh versi spesifik, ganti bagian curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt dengan versi yang diinginkan.
Misalnya, untuk mengunduh versi v1.24.0 di Linux, ketik:
Untuk mengunduh versi spesifik, ganti bagian curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt dengan versi yang diinginkan.
Misalnya, untuk mengunduh versi v1.24.0 pada macOS, ketik:
Tambahkan program yang sudah diunduh tersebut ke PATH kamu.
Pastikan instalasinya sudah berhasil dengan melakukan pengecekan versi:
kubectl version --client
Catatan:Docker Desktop untuk Windows sudah menambahkan versi kubectl-nya sendiri ke PATH. Jika kamu sudah menginstal Docker Desktop, kamu harus menambahkan entrinya ke PATH sebelum yang ditambahkan oleh penginstal (installer) Docker Desktop atau kamu dapat menghapus kubectl bawaan dari Docker Desktop.
Menginstal dengan Powershell dari PSGallery
Jika kamu menggunakan Windows dan manajer paket Powershell Gallery, kamu dapat menginstal dan melakukan pembaruan kubectl dengan Powershell.
Jalankan perintah berikut (jangan lupa untuk memasukkan DownloadLocation):
Pastikan instalasinya sudah berhasil dengan melakukan pengecekan versi:
kubectl version --client
Memeriksa konfigurasi kubectl
Agar kubectl dapat mengakses klaster Kubernetes, dibutuhkan sebuah berkas kubeconfig, yang akan otomatis dibuat ketika kamu membuat klaster baru menggunakan kube-up.sh atau setelah berhasil men-deploy klaster Minikube. Secara bawaan, konfigurasi kubectl disimpan di ~/.kube/config.
Kamu dapat memeriksa apakah konfigurasi kubectl sudah benar dengan mengambil keadaan klaster:
kubectl cluster-info
Jika kamu melihat respons berupa URL, maka konfigurasi klaster kubectl sudah benar.
Tetapi, jika kamu melihat pesan seperti di bawah, maka kubectl belum dikonfigurasi dengan benar atau tidak dapat terhubung ke klaster Kubernetes.
The connection to the server <server-name:port> was refused - did you specify the right host or port?
Selanjutnya, jika kamu ingin menjalankan klaster Kubernetes di laptop (lokal) kamu, kamu memerlukan sebuah perangkat seperti Minikube sebelum menjalankan ulang perintah yang ada di atas.
Jika kubectl cluster-info mengembalikan respons URL tetapi kamu masih belum dapat mengakses klaster, kamu bisa menggunakan perintah di bawah untuk memeriksa apakah klaster sudah dikonfigurasi dengan benar.
kubectl cluster-info dump
Konfigurasi kubectl opsional
Menyalakan penyelesaian otomatis untuk terminal
kubectl menyediakan fitur penyelesaian otomatis (auto complete) untuk Bash dan Zsh yang dapat memudahkanmu ketika mengetik di terminal.
Ikuti petunjuk di bawah untuk menyalakan penyelesaian otomatis untuk Bash dan Zsh.
Skrip penyelesaian (completion script) kubectl untuk Bash dapat dibuat dengan perintah kubectl completion bash. Masukkan skrip tersebut ke dalam terminal sebagai sumber untuk menyalakan penyelesaian otomatis dari kubectl.
Namun, skrip penyelesaian tersebut bergantung pada bash-completion, yang artinya kamu harus menginstal program tersebut terlebih dahulu (kamu dapat memeriksa apakah kamu sudah memiliki bash-completion dengan menjalankan perintah type _init_completion).
Menginstal bash-completion
bash-completion disediakan oleh banyak manajer paket (lihat di sini). Kamu dapat menginstalnya dengan menggunakan perintah apt-get install bash-completion atau yum install bash-completion, dsb.
Perintah di atas akan membuat skrip utama bash-completion di /usr/share/bash-completion/bash_completion. Terkadang kamu juga harus menambahkan skrip tersebut ke dalam berkas ~/.bashrc, tergantung manajer paket yang kamu pakai.
Untuk memastikannya, muat ulang terminalmu dan jalankan type _init_completion. Jika perintah tersebut berhasil, maka instalasi selesai. Jika tidak, tambahkan teks berikut ke dalam berkas ~/.bashrc:
source /usr/share/bash-completion/bash_completion
Muat ulang terminalmu dan pastikan bash-completion sudah berhasil diinstal dengan menjalankan type _init_completion.
Menyalakan penyelesaian otomatis kubectl
Sekarang kamu harus memastikan bahwa skrip penyelesaian untuk kubectl sudah dimasukkan sebagai sumber penyelesaian otomatis pada semua sesi terminal. Kamu dapat melakukannya dengan dua cara:
Masukkan skrip penyelesaian sebagai sumber di berkas ~/.bashrc:
Catatan: Semua sumber skrip penyelesaian bash-completion terdapat di /etc/bash_completion.d.
Kedua cara tersebut sama, kamu bisa memilih salah satunya. Setelah memuat ulang terminal, penyelesaian otomatis dari kubectl seharusnya sudah dapat bekerja.
Pendahuluan
Skrip penyelesaian (completion script) kubectl untuk Bash dapat dibuat dengan perintah kubectl completion bash. Masukkan skrip tersebut ke dalam terminal sebagai sumber untuk menyalakan penyelesaian otomatis dari kubectl.
Namun, skrip penyelesaian tersebut bergantung pada bash-completion, yang artinya kamu harus menginstal program tersebut terlebih dahulu.
Peringatan: Terdapat dua versi bash-completion, v1 dan v2. V1 untuk Bash 3.2 (bawaan dari macOs), dan v2 untuk Bash 4.1+. Skrip penyelesaian kubectltidak kompatibel dengan bash-completion v1 dan Bash 3.2. Dibutuhkan bash-completion v2 dan Bash 4.1+ agar skrip penyelesaian kubectl dapat bekerja dengan baik. Maka dari itu, kamu harus menginstal dan menggunakan Bash 4.1+ (panduan) untuk dapat menggunakan fitur penyelesaian otomatis dari kubectl. Ikuti panduan di bawah setelah kamu menginstal Bash 4.1+ (yaitu, Bash versi 4.1 atau lebih baru).
Pemutakhiran Bash
Panduan di bawah berasumsi kamu menggunakan Bash 4.1+. Kamu dapat memeriksa versi Bash dengan menjalankan:
echo$BASH_VERSION
Jika versinya sudah terlalu usang, kamu dapat menginstal/memutakhirkannya dengan menggunakan Homebrew:
brew install bash
Muat ulang terminalmu dan pastikan versi yang diharapkan sudah dipakai:
echo$BASH_VERSION$SHELL
Homebrew biasanya akan menginstalnya di /usr/local/bin/bash.
Menginstal bash-completion
Catatan: Seperti yang sudah disebutkan, panduan di bawah berasumsi kamu menggunakan Bash 4.1+, yang berarti kamu akan menginstal bash-completion v2 (penyelesaian otomatis dari kubectl tidak kompatibel dengan Bash 3.2 dan bash-completion v1).
Kamu dapat memeriksa apakah kamu sudah memiliki bash-completion v2 dengan perintah type _init_completion. Jika belum, kamu dapat menginstalnya dengan menggunakan Homebrew:
brew install bash-completion@2
Seperti yang disarankan pada keluaran perintah di atas, tambahkan teks berikut ke berkas ~/.bashrc:
Muat ulang terminalmu dan pastikan bash-completion v2 sudah terinstal dengan perintah type _init_completion.
Menyalakan penyelesaian otomatis kubectl
Sekarang kamu harus memastikan bahwa skrip penyelesaian untuk kubectl sudah dimasukkan sebagai sumber penyelesaian otomatis di semua sesi terminal. Kamu dapat melakukannya dengan beberapa cara:
Masukkan skrip penyelesaian sebagai sumber di berkas ~/.bashrc:
Jika kamu menggunakan alias untuk kubectl, kamu masih dapat menggunakan fitur penyelesaian otomatis dengan menjalankan perintah:
echo'alias k=kubectl' >>~/.bashrc
echo'complete -F __start_kubectl k' >>~/.bashrc
Jika kamu menginstal kubectl dengan Homebrew (seperti yang sudah dijelaskan di atas), maka skrip penyelesaian untuk kubectl sudah berada di /usr/local/etc/bash_completion.d/kubectl. Kamu tidak perlu melakukan apa-apa lagi.
Catatan: bash-completion v2 yang diinstal dengan Homebrew meletakkan semua berkas nya di direktori BASH_COMPLETION_COMPAT_DIR, itulah alasannya dua cara terakhir dapat bekerja.
Setelah memuat ulang terminal, penyelesaian otomatis dari kubectl seharusnya sudah dapat bekerja.
Skrip penyelesaian (completion script) kubectl untuk Zsh dapat dibuat dengan perintah kubectl completion zsh. Masukkan skrip tersebut ke dalam terminal sebagai sumber untuk menyalakan penyelesaian otomatis dari kubectl.
Tambahkan baris berikut di berkas ~/.zshrc untuk menyalakan penyelesaian otomatis dari kubectl:
source <(kubectl completion zsh)
Jika kamu menggunakan alias untuk kubectl, kamu masih dapat menggunakan fitur penyelesaian otomatis dengan menjalankan perintah:
echo'alias k=kubectl' >>~/.zshrc
echo'compdef __start_kubectl k' >>~/.zshrc
Setelah memuat ulang terminal, penyelesaian otomatis dari kubectl seharusnya sudah dapat bekerja.
Jika kamu mendapatkan pesan gagal seperti complete:13: command not found: compdef, maka tambahkan teks berikut ke awal berkas ~/.zshrc:
2 - Menjalankan Tugas-Tugas Otomatis dengan CronJob
Kamu dapat menggunakan CronJob untuk menjalankan Job yang dijadwalkan berbasis waktu. Job akan berjalan seperti pekerjaan-pekerjaan Cron di Linux atau sistem UNIX.
CronJob sangat berguna untuk membuat pekerjaan yang berjalan secara periodik dan berulang, misalnya menjalankan (backup) atau mengirim email.
CronJob juga dapat menjalankan pekerjaan individu pada waktu tertentu, misalnya jika kamu ingin menjadwalkan sebuah pekerjaan dengan periode aktivitas yang rendah.
CronJob memiliki keterbatasan dan kekhasan.
Misalnya, dalam keadaan tertentu, sebuah CronJob dapat membuat banyak Job.
Karena itu, Job haruslah idempotent.
Untuk informasi lanjut mengenai keterbatasan, lihat CronJob.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
CronJob membutuhkan sebuah berkas konfigurasi.
Ini adalah contoh dari berkas konfigurasi CronJob .spec yang akan mencetak waktu sekarang dan pesan "hello" setiap menit:
Kamu juga dapat menggunakan kubectl run untuk membuat sebuah CronJob tanpa menulis sebuah konfigurasi yang lengkap:
kubectl run hello --schedule="*/1 * * * *" --restart=OnFailure --image=busybox -- /bin/sh -c "date; echo Hello from the Kubernetes cluster"
Setelah membuat sebuah CronJob, untuk mengecek statusnya kamu dapat menggunakan perintah berikut:
kubectl get cronjob hello
Keluaran akan mirip dengan ini:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 <none> 10s
Seperti yang kamu lihat dari hasil perintah di atas, CronJob belum menjadwalkan atau menjalankan pekerjaan apa pun.
Waktu yang biasanya dibutuhkan untuk mengamati Job hingga Job tersebut dibuat akan membutuhkan sekitar satu menit:
kubectl get jobs --watch
Keluaran akan mirip dengan ini:
NAME COMPLETIONS DURATION AGE
hello-4111706356 0/1 0s
hello-4111706356 0/1 0s 0s
hello-4111706356 1/1 5s 5s
Sekarang kamu telah melihat satu Job berjalan yang dijadwalkan oleh "hello" CronJob.
Kamu dapat berhenti mengamati Job dan melihat CronJob lagi untuk melihat CronJob menjadwalkan sebuah Job:
kubectl get cronjob hello
Keluaran akan mirip dengan ini:
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 50s 75s
Kamu dapat melihat bahwa CronJob hello berhasil menjadwalkan sebuah Job pada waktu yang ditentukan dalam LAST SCHEDULE. Saat ini ada 0 Job yang aktif, berarti sebuah Job telah selesai atau gagal.
Sekarang, temukan Pod yang dibuat oleh jadwal Job terakhir dan melihat keluaran bawaan dari salah satu Pod.
Catatan: Nama Job dan nama Pod itu berbeda.
# Ganti "hello-4111706356" dengan nama Job di sistem kamupods=$(kubectl get pods --selector=job-name=hello-4111706356 --output=jsonpath={.items[*].metadata.name})
Menampilkan log sebuah Pod:
kubectl logs $pods
Keluaran akan mirip dengan ini:
Fri Feb 22 11:02:09 UTC 2019
Hello from the Kubernetes cluster
Menghapus sebuah CronJob
Ketika kamu tidak membutuhkan sebuah CronJob lagi, kamu dapat megnhapusnya dengan perintah kubectl delete cronjob <cronjob name>:
kubectl delete cronjob hello
Menghapus CronJob akan menghapus semua Job dan Pod yang telah terbuat dan menghentikanya dari pembuatan Job tambahan.
Kamu dapat membaca lebih lanjut tentang menghapus Job di garbage collection.
Sebuah konfigurasi CronJob juga membutuhkan sebuah bagian .spec.
Catatan: Semua modifikasi pada sebuah CronJob, terutama .spec, akan diterapkan pada proses berikut.
Penjadwalan
.spec.schedule adalah field yang wajib diisi dari sebuah .spec
Dibutuhkan sebuah format string Cron, misalnya 0 * * * * atau @hourly, sebagai jadwal Job untuk dibuat dan dieksekusi.
Format ini juga mencakup nilai langkah "Vixie cron". Seperti penjelasan di FreeBSD manual:
Nilai langkah dapat digunakan bersama dengan rentang. Sebuah rentang diikuti dengan
/<number> menentukan lompatan angka melalui rentang.
Misalnya, 0-23/2 dapat digunakan dalam jam untuk menentukan
perintah akan dieksekusi setiap jam (alternatif dalam bawaan v7 adalah
0,2,4,6,8,10,12,14,16,18,20,22). Langkah-langkah juga diizinkan setelah
tanda bintang, jadi jika kamu menginginkan "setiap dua jam", gunakan saja */2.
Catatan: Sebuah tanda tanya (?) dalam penjadwalan memiliki makna yang sama dengan tanda bintang *, yaitu, singkatan dari nilai apa pun yang tersedia untuk field tertentu.
Templat Job
.spec.JobTemplate adalah templat untuk sebuah Job, dan itu wajib.
Templat Job memiliki skema yang sama dengan Job, kecuali jika bersarang dan tidak memiliki sebuah apiVersion atau kind.
Untuk informasi lebih lanjut tentang menulis sebuah Job .spec lihat Menulis spesifikasi Job.
Starting Deadline
Field.spec.startingDeadlineSeconds adalah field opsional.
Field tersebut berarti batas waktu dalam satuan detik untuk memulai sebuah Job jika Job melewatkan waktu yang telah dijadwalkan karena alasan apapun.
Setelah mencapai batas waktu, CronJob tidak akan memulai sebuah Job.
Job yang tidak memenuhi batas waktu, dengan cara ini dianggap sebagai Job yang gagal.
Jika field ini tidak ditentukan, maka Job tidak memiliki batas waktu.
Controller CronJob menghitung berapa banyak jadwal yang terlewat untuk sebuah CronJob. jika lebih dari 100 jadwal yang terlewat, maka tidak ada lagi CronJob yang akan dijadwalkan. Ketika .spec.startingDeadlineSeconds tidak disetel, CronJob Controller menghitung jadwal yang terlewat dari status.lastScheduleTime hingga sekarang.
Misalnya, sebuah CronJob seharusnya berjalan setiap menit, status.lastScheduleTime CronJob adalah pukul 5:00am, tetapi sekarang pukul 07:00am. Itu berarti ada 120 jadwal yang terlewat, maka tidak ada lagi CronJob yang akan dijadwalkan.
Jika field.spec.startingDeadlineSeconds disetel (tidak kosong), CronJob Controller akah menghitung berapa banyak Job yang terlewat dari nilai .spec.startingDeadlineSeconds hingga sekarang.
Misalnya, jika disetel ke 200, CronJob Controller akan menghitung jadwal yang terlewat dalam 200 detik terakhir. Pada kasus ini, jika terdapat lebih dari 100 jadwal yang terlewat dalam 200 detik terakhir, maka tidak ada lagi CronJob yang akan dijadwalkan.
Kebijakan Concurrency
Field.spec.concurrencyPolicy juga opsional.
Field tersebut menentukan bagaimana memperlakukan eksekusi concurrent dari sebuah Job yang dibuat oleh CronJob.
Kamu dapat menetapkan hanya satu dari kebijakan concurrency:
Allow (bawaan): CronJob mengizinkan Job berjalan secara concurrent
Forbid : Job tidak mengizinkan Job berjalan secara concurrent; jika sudah saatnya untuk menjalankan Job baru dan Job sebelumnya belum selesai, maka CronJob akan melewatkan Job baru yang akan berjalan
Replace: Jika sudah saatnya untuk menjalankan Job baru dan Job sebelumnya belum selesai, maka CronJob akan mengganti Job yang sedang berjalan dengan Job baru.
Perhatikan bahwa kebijakan concurrency hanya berlaku untuk Job yang dibuat dengan CronJob yang sama.
Jika terdapat banyak CronJob, Job akan selalu diizinkan untuk berjalan secara concurrent.
Penangguhan
Field.spec.suspend juga opsional.
Jika field tersebut disetel true, semua eksekusi selanjutnya akan ditangguhkan.
Konfigurasi ini tidak dapat berlaku untuk eksekusi yang sudah dimulai.
Secara bawaan false.
Perhatian: Eksekusi yang ditangguhkan selama waktu yang dijadwalkan dihitung sebagai Job yang terlewat.
Ketika .spec.suspend diubah dari true ke false pada CronJob yang memiliki konfigurasi tanpa batas waktu, Job yang terlewat akan dijadwalkan segera.
Batas Riwayat Pekerjaan
Field.spec.successfulJobHistoryLimit dan .spec.failedJobHistoryLimit juga opsional.
Field tersebut menentukan berapa banyak Job yang sudah selesai dan gagal yang harus disimpan.
Secara bawaan, masing-masing field tersebut disetel 3 dan 1. Mensetel batas ke 0 untuk menjaga tidak ada Job yang sesuai setelah Job tersebut selesai.
3 - Mengatur Pod dan Kontainer
3.1 - Menetapkan Sumber Daya Memori untuk Container dan Pod
Laman ini menunjukkan bagaimana menetapkan permintaan dan batasan memori untuk Container.
Container dijamin memiliki memori sebanyak yang diminta,
tetapi tidak diperbolehkan untuk menggunakan memori melebihi batas.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Setiap Node pada klaster kamu harus memiliki memori setidaknya 300 MiB.
Beberapa langkah pada laman ini mengharuskan kamu menjalankan Service
metrics-server
pada klaster kamu. Jika kamu memiliki metrics-server
yang sudah berjalan, kamu dapat melewati langkah-langkah berikut ini.
Jika kamu menjalankan Minikube, jalankan perintah berikut untuk mengaktifkan
metrics-server:
minikube addons enable metrics-server
Untuk melihat apakah metrics-server sudah berjalan, atau penyedia lain dari API metrik sumber daya
(metrics.k8s.io), jalankan perintah berikut ini:
kubectl get apiservices
Jika API metrik sumber daya telah tersedia, keluarannya meliputi seperti
acuan pada metrics.k8s.io.
NAME
v1beta1.metrics.k8s.io
Membuat Namespace
Buat Namespace sehingga sumber daya yang kamu buat dalam latihan ini
terisolasi dari klaster kamu yang lain.
kubectl create namespace mem-example
Menentukan permintaan memori dan batasan memori
Untuk menentukan permintaan memori untuk Container, sertakan fieldresources:requests
pada manifes sumber daya dari Container. Untuk menentukan batasan memori, sertakan resources:limits.
Dalam latihan ini, kamu akan membuat Pod yang memiliki satu Container. Container memiliki permintaan memori
sebesar 100 MiB dan batasan memori sebesar 200 MiB. Berikut berkas konfigurasi
untuk Pod:
Bagian args dalam berkas konfigurasi memberikan argumen untuk Container pada saat dimulai.
Argumen"--vm-bytes", "150M" memberi tahu Container agar mencoba mengalokasikan memori sebesar 150 MiB.
Jalankan kubectl top untuk mengambil metrik dari Pod:
kubectl top pod memory-demo --namespace=mem-example
Keluarannya menunjukkan bahwa Pod menggunakan memori sekitar 162.900.000 byte, dimana
sekitar 150 MiB. Ini lebih besar dari permintaannya sebesar 100 MiB Pod, tetapi masih di dalam
batasan Pod sebesar 200 MiB.
NAME CPU(cores) MEMORY(bytes)
memory-demo <something> 162856960
Hapuslah Pod:
kubectl delete pod memory-demo --namespace=mem-example
Melebihi batasan memori dari Container
Container dapat melebihi permintaan memorinya jika Node memiliki memori yang tersedia. Tapi sebuah Container
tidak diperbolehkan untuk menggunakan lebih dari batasan memorinya. Jika Container mengalokasikan lebih banyak memori daripada
batasannya, Container menjadi kandidat untuk dihentikan. Jika Container terus berlanjut
mengkonsumsi memori melebihi batasnya, maka Container akan diakhiri. Jika Container dihentikan dan bisa
di mulai ulang, kubelet akan memulai ulang, sama seperti jenis kegagalan runtime yang lainnya.
Dalam latihan ini, kamu membuat Pod yang mencoba mengalokasikan lebih banyak memori dari batasannya.
Berikut adalah berkas konfigurasi untuk Pod yang memiliki satu Container dengan berkas
permintaan memori sebesar 50 MiB dan batasan memori sebesar 100 MiB:
Dalam bagian args dari berkas konfigurasi, kamu dapat melihat bahwa Container tersebut
akan mencoba mengalokasikan memori sebesar 250 MiB, yang jauh di atas batas yaitu 100 MiB.
Container dalam latihan ini dapat dimulai ulang, sehingga kubelet akan memulai ulangnya. Ulangi
perintah ini beberapa kali untuk melihat bahwa Container berulang kali dimatikan dan dimulai ulang:
kubectl get pod memory-demo-2 --namespace=mem-example
Keluarannya menunjukkan bahwa Container dimatikan, dimulai ulang, dimatikan lagi, dimulai ulang lagi, dan seterusnya:
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 0/1 OOMKilled 1 37s
kubectl get pod memory-demo-2 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-2 1/1 Running 2 40s
Lihat informasi mendetail tentang riwayat Pod:
kubectl describe pod memory-demo-2 --namespace=mem-example
Keluarannya menunjukkan bahwa Container dimulai dan gagal berulang kali:
... Normal Created Created container with id 66a3a20aa7980e61be4922780bf9d24d1a1d8b7395c09861225b0eba1b1f8511
... Warning BackOff Back-off restarting failed container
Lihat informasi mendetail tentang Node klaster Anda:
kubectl describe nodes
Keluarannya mencakup rekaman Container yang dimatikan karena kondisi kehabisan memori:
Warning OOMKilling Memory cgroup out of memory: Kill process 4481 (stress) score 1994 or sacrifice child
Hapus Pod kamu:
kubectl delete pod memory-demo-2 --namespace=mem-example
Menentukan permintaan memori yang terlalu besar untuk Node kamu
Permintaan dan batasan memori yang dikaitkan dengan Container, berguna untuk berpikir
apakah sebuah Pod yang memiliki permintaan dan batasan memori. Permintaan memori untuk Pod tersebut adalah
jumlah permintaan memori untuk semua Container dalam Pod. Begitu juga dengan batasan memori
untuk Pod adalah jumlah batasan memori dari semua Container di dalam Pod.
Penjadwalan Pod didasarkan pada permintaan. Sebuah Pod dijadwalkan untuk berjalan di sebuah Node hanya jika sebuah Node
memiliki cukup memori yang tersedia untuk memenuhi permintaan memori dari Pod tersebut.
Dalam latihan ini, kamu membuat Pod yang memiliki permintaan memori yang sangat besar sehingga melebihi
kapasitas dari Node mana pun dalam klaster kamu. Berikut adalah berkas konfigurasi untuk Pod yang memiliki
Container dengan permintaan memori 1000 GiB, yang kemungkinan besar melebihi kapasitas
dari setiap Node dalam klaster kamu.
kubectl get pod memory-demo-3 --namespace=mem-example
Keluarannya menunjukkan bahwa status Pod adalah PENDING. Artinya, Pod tidak dijadwalkan untuk berjalan di Node mana pun, dan Pod akan tetap dalam status PENDING tanpa batas waktu:
kubectl get pod memory-demo-3 --namespace=mem-example
NAME READY STATUS RESTARTS AGE
memory-demo-3 0/1 Pending 0 25s
Lihat informasi mendetail tentang Pod, termasuk event:
kubectl describe pod memory-demo-3 --namespace=mem-example
Keluarannya menunjukkan bahwa Container tidak dapat dijadwalkan karena memori yang tidak cukup pada Node:
Events:
... Reason Message
------ -------
... FailedScheduling No nodes are available that match all of the following predicates:: Insufficient memory (3).
Satuan Memori
Sumber daya memori diukur dalam satuan byte. Kamu dapat mengekspresikan memori sebagai bilangan bulat biasa atau
bilangan bulan fixed-point dengan salah satu akhiran ini: E, P, T, G, M, K, Ei, Pi, Ti, Gi, Mi, Ki.
Contoh berikut ini mewakili nilai yang kira-kira sama:
128974848, 129e6, 129M , 123Mi
Hapuslah Pod kamu:
kubectl delete pod memory-demo-3 --namespace=mem-example
Jika kamu tidak menentukan batasan memori
Jika kamu tidak menentukan batasan memori untuk sebuah Container, salah satu dari situasi berikut ini berlaku:
Container tidak memiliki batasan maksimum jumlah memori yang digunakannya. Container
dapat menggunakan semua memori yang tersedia dalam Node dimana Container itu berjalan yang pada gilirannya dapat memanggil penyetop OOM (out-of-memory).
Lebih lanjut, dalam kasus menghentikan OOM, Container tanpa batas sumber daya akan memiliki peluang lebih besar untuk dihentikan.
Container berjalan pada Namespace yang memiliki batasan bawaan memori, dan
Container secara otomatis menetapkan batasan bawaan. Administrator klaster dapat menggunakan
LimitRange
untuk menentukan batasan memori secara bawaan.
Motivasi untuk permintaan dan batasan memori
Dengan mengonfigurasi permintaan dan batasan memori untuk Container yang berjalan pada berkas
klaster, kamu dapat menggunakan sumber daya memori yang tersedia pada Node klaster kamu secara efisien.
Dengan menjaga permintaan memori pada Pod tetap rendah, kamu memberikan kesempatan yang baik untuk Pod tersebut
dijadwalkan. Dengan memiliki batas memori yang lebih besar dari permintaan memori, Anda mencapai dua hal:
Pod dapat memiliki aktivitas yang bersifat burst dengan memanfaatkan memori yang kebetulan tersedia.
Jumlah memori yang dapat digunakan Pod selama keadaan burst dibatasi pada jumlah yang wajar.
Membersihkan
Hapus Namespace kamu. Ini akan menghapus semua Pod yang kamu buat untuk tugas ini:
Laman ini menunjukkan bagaimana mengonfigurasi Pod agar ditempatkan pada kelas Quality of Service (QoS) tertentu.
Kubernetes menggunakan kelas QoS untuk membuat keputusan tentang
penjadwalan dan pengeluaran Pod.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Saat membuat Pod, Kubernetes menempatkan salah satu kelas QoS berikut untuknya:
Guaranteed
Burstable
BestEffort
Membuat sebuah Namespace
Buat sebuah Namespace sehingga sumber daya yang kamu buat dalam latihan ini
terisolasi dari klaster kamu yang lain.
kubectl create namespace qos-example
Membuat sebuah Pod yang mendapatkan penempatan kelas QoS Guaranteed
Agar sebuah Pod memiliki kelas QoS Guaranteed:
Setiap Container, termasuk Container pemulai, di dalam Pod harus memiliki batasan memori dan permintaan memori dengan nilai yang sama.
Setiap Container, termasuk Container pemulai, di dalam Pod harus memiliki batasan CPU dan permintaan CPU dengan nilai yang sama.
Berikut adalah berkas konfigurasi untuk sebuah Pod dengan satu Container. Container tersebut memiliki sebuah batasan memori dan sebuah
permintaan memori, keduanya sama dengan 200MiB. Container itu juga mempunyai batasan CPU dan permintaan CPU yang sama sebesar 700 milliCPU:
kubectl get pod qos-demo --namespace=qos-example --output=yaml
Keluaran dari perintah di atas menunjukkan Kubernetes memberikan kelas QoS Guaranteed pada Pod. Keluaran tersebut juga
membuktikan bahwa Container pada Pod memiliki permintaan memori yang sesuai dengan batasan memori dan permintaan CPU yang juga sesuai dengan batasan CPU yang dispesifikasikan.
Catatan: Jika sebuah Container hanya menspesifikasikan batasan memori tanpa menentukan permintaan memori, maka Kubernetes akan
secara otomatis menetapkan permintaan memori yang sesuai dengan batasan memori yang dicantumkan. Sama halnya jika sebuah Container menspesifikasikan batasan
CPU tanpa menentukan permintaan CPU, maka Kubernetes akan secara otomatis menetapkan permintaan CPU yang sesuai
dengan batasan CPU yang dicantumkan.
Hapuslah Pod:
kubectl delete pod qos-demo --namespace=qos-example
Membuat sebuah Pod yang mendapatkan penempatan kelas Qos Burstable
Sebuah Pod akan mendapatkan kelas QoS Burstable apabila:
Pod tidak memenuhi kriteria untuk kelas QoS Guaranteed.
Setidaknya ada satu Container di dalam Pod dengan permintaan memori atau CPU.
Berikut adalah berkas konfigurasi untuk Pod dengan satu Container. Container yang dimaksud memiliki batasan memori sebesar 200MiB
dan permintaan memori sebesar 100MiB.
kubectl delete pod qos-demo-2 --namespace=qos-example
Membuat sebuah Pod yang mendapatkan penempatan kelas QoS BestEffort
Agar Pod mendapatkan kelas QoS BestEffort, Container dalam pod tidak boleh
memiliki batasan atau permintaan memori atau CPU.
Berikut adalah berkas konfigurasi untuk Pod dengan satu Container. Container yang dimaksud tidak memiliki batasan atau permintaan memori atau CPU apapun.
kubectl delete pod qos-demo-3 --namespace=qos-example
Membuat sebuah Pod yang memiliki dua Container
Berikut adalah konfigurasi berkas untuk Pod yang memiliki dua Container. Satu Container menentukan permintaan memori sebesar 200MiB. Container yang lain tidak menentukan permintaan atau batasan apapun.
Perhatikan bahwa Pod ini memenuhi kriteria untuk kelas QoS Burstable. Maksudnya, Container tersebut tidak memenuhi
kriteria untuk kelas QoS Guaranteed, dan satu dari Container tersebut memiliki permintaan memori.
3.3 - Mengatur Pod untuk Menggunakan Volume sebagai Tempat Penyimpanan
Laman ini menjelaskan bagaimana cara mengatur sebuah Pod untuk menggunakan Volume sebagai tempat penyimpanan.
Filesystem dari sebuah Container hanya hidup selama Container itu juga hidup. Saat Container berakhir dan dimulai ulang, perubahan pada filesystem akan hilang. Untuk penyimpanan konsisten yang independen dari Container, kamu dapat menggunakan Volume. Hal ini penting terutama untuk aplikasi stateful, seperti key-value stores (contohnya Redis) dan database.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Pada latihan ini, kamu membuat sebuah Pod yang menjalankan sebuah Container. Pod ini memiliki sebuah Volume dengan tipe emptyDir
yang tetap bertahan, meski Container berakhir dan dimulai ulang. Berikut berkas konfigurasi untuk Pod:
Selain penyimpanan pada disk lokal yang di sediakan oleh emptyDir, Kubernetes
juga mendukung solusi penyimpanan network-attached, termasuk PD pada
GCE dan EBS dari EC2, yang cenderung lebih disukai untuk data sangat penting dan akan menangani urusan detil seperti mounting dan unmounting perangkat pada Node. Lihat
Volume untuk informasi detil.
3.4 - Mengatur Pod untuk Penyimpanan dengan PersistentVolume
Laman ini akan menjelaskan bagaimana kamu dapat mengatur sebuah Pod dengan menggunakan
PersistentVolumeClaim
untuk penyimpanan.
Berikut ringkasan prosesnya:
Kamu, sebagai seorang administrator klaster, membuat sebuah PersistentVolume yang didukung oleh penyimpanan
fisik. Kamu tidak mengaitkan volume dengan Pod apapun.
Kamu, sekarang mengambil peran sebagai seorang developer / pengguna klaster, membuat sebuah
PersistentVolumeClaim yang secara otomatis terikat dengan PersistentVolume yang sesuai.
Kamu membuat sebuah Pod yang menggunakan PersistentVolumeClaim di atas untuk penyimpanan.
Sebelum kamu memulai
Kamu membutuhkan sebuah klaster Kubernetes yang hanya memiliki satu Node, dan
kubectl
alat baris perintah yang sudah diatur untuk berkomunikasi dengan klaster kamu. Jika kamu
tidak memiliki sebuah klaster dengan Node tunggal, kamu dapat membuatnya dengan
Minikube.
Membuat sebuah berkas index.html di dalam Node kamu
Buka sebuah shell ke Node tunggal di klaster kamu. Bagaimana kamu membuka sebuah shell tergantung
dengan bagaimana kamu mengatur klaster kamu. Contoh, jika kamu menggunakan Minikube, kamu
dapat membuka sebuah shell ke Node kamu dengan memasukkan minikube ssh.
Di dalam shell kamu pada Node itu, buat sebuah direktori dengan nama /mnt/data:
# Asumsikan Node kamu menggunakan "sudo" untuk menjalankan perintah# sebagai superuser
sudo mkdir /mnt/data
Di dalam direktori /mnt/data, buat sebuah berkas dengan nama index.html:
# Disini kembali asumsikan bahwa Node kamu menggunakan "sudo" untuk menjalankan perintah# sebagai superuser
sudo sh -c "echo 'Hello from Kubernetes storage' > /mnt/data/index.html"
Catatan: Jika Node kamu menggunakan alat untuk mengakses superuser selain dengan sudo, kamu dapat
membuat ini bekerja jika mengganti sudo dengan nama dari alat lainnya.
Menguji bahwa berkas index.html ada:
cat /mnt/data/index.html
Keluaran akan seperti ini:
Hello from Kubernetes storage
Sekarang kamu dapat menutup shell di Node kamu.
Membuat sebuah PersistentVolume
Pada latihan ini, kamu akan membuat sebuah hostPath PersistentVolume. Kubernetes mendukung
hostPath untuk pengembangan dan pengujian di dalam klaster Node tunggal. Sebuah hostPath
PersistentVolume menggunakan berkas atau direktori di dalam Node untuk meniru penyimpanan terhubung jaringan (NAS, network-attached storage).
Di dalam klaster production, kamu tidak dapat menggunakan hostPath. Sebagai gantinya sebuah administrator klaster
akan menyediakan sumberdaya jaringan seperti Google Compute Engine persistent disk,
NFS share, atau sebuah Amazon Elastic Block Store volume. Administrator klaster juga dapat
menggunakan StorageClass
untuk mengatur
provisioning secara dinamis.
Berikut berkas konfigurasi untuk hostPath PersistentVolume:
Berkas konfigurasi tersebut menentukan bahwa volume berada di /mnt/data pada
klaster Node. Konfigurasi tersebut juga menentukan ukuran dari 10 gibibytes dan
mode akses ReadWriteOnce, yang berarti volume dapat di pasang sebagai
read-write oleh Node tunggal. Konfigurasi ini menggunakan nama dari StorageClassmanual untuk PersistentVolume, yang akan digunakan untuk mengikat
permintaan PeristentVolumeClaim ke PersistentVolume ini.
Keluaran menunjuk PersistentVolume memliki sebuah STATUS dari Available. Ini
berarti PersistentVolume belum terikat ke PersistentVolumeClaim.
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
task-pv-volume 10Gi RWO Retain Available manual 4s
Membuat sebuah PersistentVolumeClaim
Langkah selanjutnya adalah membuat sebuah PersistentVolumeClaim. Pod menggunakan PersistentVolumeClaim
untuk meminta penyimpanan fisik. Pada latihan ini, kamu akan membuat sebuah PersistentVolumeClaim
yang meminta sebuah volume minimal tiga gibibytes dengan mode akses read-write
setidaknya untuk satu Node.
Berikut berkas konfigurasi untuk PersistentVolumeClaim:
Setelah membuat sebuah PersistentVolumeClaim, Kubernetes control plane terlihat
untuk sebuah PersistentVolumeClaim yang memenuhi persyaratan claim's. Jika
control plane menemukan PersistentVolume yang cocok dengan StorageClass, maka
akan mengikat claim ke dalam volume tersebut.
Lihat kembali PersistentVolume:
kubectl get pv task-pv-volume
Sekarang keluaran menunjukan sebuah STATUS dari Bound.
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
task-pv-volume 10Gi RWO Retain Bound default/task-pv-claim manual 2m
Lihat PersistentVolumeClaim:
kubectl get pvc task-pv-claim
Keluaran menunjukan PersistentVolumeClaim terlah terikat dengan PersistentVolume,
task-pv-volume.
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
task-pv-claim Bound task-pv-volume 10Gi RWO manual 30s
Membuat sebuah Pod
Langkah selanjutnya adalah membuat sebuah Pod yang akan menggunakan PersistentVolumeClaim sebagai volume.
Perhatikan bahwa berkas konfigurasi Pod menentukan sebuah PersistentVolumeClaim, tetapi
tidak menentukan PeristentVolume. Dari sudut pandang Pod, claim adalah volume.
Mendapatkan sebuah shell ke Container yang sedang berjalan di Pod kamu:
kubectl exec -it task-pv-pod -- /bin/bash
Di dalam shell, pastikan bahwa nginx menyajikan berkas index.html dari dalam
hostPath volume:
# Pastikan kamu menjalankan 3 perintah ini di dalam shell root yang berasal dari# "kubectl exec" dari langkah sebelumnya
apt update
apt install curl
curl http://localhost/
Keluaran akan menunjukan sebuah teks yang telah kamu tulis di berkas index.html
di dalam hostPath volume:
Hello from Kubernetes storage
Jika kamu melihat pesan tersebut, kamu telah berhasil mengatur sebuah Pod
untuk menggunakan penyimpanan dari PersistentVolumeClaim.
Membersihkan
Hapus Pod, PersistentVolumeClaim dan PersistentVolume:
Jika kamu belum memiliki shell yang telah dibuka ke Node di klaster kamu,
buka shell baru dengan cara yang sama yang telah kamu lakukan sebelumnya.
Di dalam shell Node kamu, hapus berkas dan direktori yang telah kamu buat:
# Asumsikan Node kamu menggunakan "sudo" untuk menjalankan perintah# sebagai superuser
sudo rm /mnt/data/index.html
sudo rmdir /mnt/data
Sekarang kamu dapat menutup shell Node kamu.
Kontrol akses
Penyimpanan yang telah terkonfigurasi dengan group ID (GID) memungkinkan akses menulis hanya dari Pod yang menggunakan
GID yang sama. GID yang tidak cocok atau hilang akan menyebabkan kesalahan izin ditolak. Untuk mengurangi
kebutuhan koordinasi dengan pengguna, administrator dapat membuat anotasi sebuah PersistentVolume
dengan GID. Kemudian GID akan otomatis ditambahkan ke Pod yang menggunakan PersistentVolume.
Gunakan anotasi pv.beta.kubernetes.io/gid sebagai berikut:
Ketika sebuah Pod mengkonsumsi PersistentVolume yang memiliki anotasi GID, anotasi GID tersebut
akan diterapkan ke semua container di dalam Pod dengan cara yang sama yang ditentukan di dalam GID Pod security context.
Settiap GID, baik berasal dari anotasi PersistentVolume atau Pod, diterapkan pada proses pertama yang dijalankan
di setiap container.
Catatan: Ketika sebuah Pod mengkonsumsi PersistentVolume, GID yang terkait dengan PersistentVolume
tidak ada di dalam sumberdaya Pod itu sendiri.
3.5 - Mengonfigurasi Konteks Keamanan untuk Pod atau Container
Konteks keamanan (security context) menentukan wewenang (privilege) dan aturan kontrol akses untuk sebuah Pod
atau Container. Aturan konteks keamanan meliputi hal-hal berikut ini namun tidak terbatas pada hal-hal tersebut:
AppArmor: Menggunakan profil program untuk membatasi kemampuan dari masing-masing program.
Seccomp: Menyaring panggilan sistem (system calls) dari suatu proses.
AllowPrivilegeEscalation: Mengontrol apakah suatu proses dapat memperoleh lebih banyak wewenang daripada proses induknya. Pilihan ini mengontrol secara langsung apakah opsi no_new_privs diaktifkan pada proses dalam Container. AllowPrivilegeEscalation selalu aktif (true) ketika Container: 1) berjalan dengan wewenang ATAU 2) memiliki CAP_SYS_ADMIN.
readOnlyRootFilesystem: Menambatkan (mount) sistem berkas (file system) root dari sebuah Container hanya sebatas untuk dibaca saja (read-only).
Poin-poin di atas bukanlah sekumpulan lengkap dari aturan konteks keamanan - silakan lihat SecurityContext untuk daftar lengkapnya.
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Untuk menentukan aturan keamanan pada Pod, masukkan bagian securityContext
dalam spesifikasi Pod. Bagian securityContext adalah sebuah objek
PodSecurityContext.
Aturan keamanan yang kamu tetapkan untuk Pod akan berlaku untuk semua Container dalam Pod tersebut.
Berikut sebuah berkas konfigurasi untuk Pod yang memiliki volume securityContext dan emptyDir:
Dalam berkas konfigurasi ini, bagian runAsUser menentukan bahwa dalam setiap Container pada
Pod, semua proses dijalankan oleh ID pengguna 1000. Bagian runAsGroup menentukan grup utama dengan ID 3000 untuk
semua proses dalam setiap Container pada Pod. Jika bagian ini diabaikan, maka ID grup utama dari Container
akan berubah menjadi root(0). Berkas apa pun yang dibuat juga akan dimiliki oleh pengguna dengan ID 1000 dan grup dengan ID 3000 ketika runAsGroup ditentukan.
Karena fsGroup ditentukan, semua proses milik Container juga merupakan bagian dari grup tambahan dengan ID 2000.
Pemilik volume /data/demo dan berkas apa pun yang dibuat dalam volume tersebut adalah grup dengan ID 2000.
Periksa apakah Container dari Pod sedang berjalan:
kubectl get pod security-context-demo
Masuk ke shell dari Container yang sedang berjalan tersebut:
kubectl exec -it security-context-demo -- sh
Pada shell kamu, lihat daftar proses yang berjalan:
ps
Keluarannya menunjukkan bahwa proses dijalankan oleh pengguna dengan ID 1000, yang merupakan nilai dari bagian runAsUser:
PID USER TIME COMMAND
11000 0:00 sleep 1h
61000 0:00 sh
...
Pada shell kamu, pindah ke direktori /data, dan lihat isinya:
cd /data
ls -l
Keluarannya menunjukkan bahwa direktori /data/demo memiliki grup dengan ID 2000, yang merupakan
nilai dari bagian fsGroup.
drwxrwsrwx 2 root 20004096 Jun 6 20:08 demo
Pada shell kamu, pindah ke direktori /data/demo, dan buatlah sebuah berkas didalamnya:
cd demo
echo hello > testfile
Lihatlah daftar berkas dalam direktori /data/demo:
ls -l
Keluarannya menunjukkan bahwa testfile memiliki grup dengan ID 2000, dimana merupakan nilai dari bagian fsGroup.
-rw-r--r-- 1100020006 Jun 6 20:08 testfile
Jalankan perintah berikut ini:
$ id
uid=1000gid=3000groups=2000
Kamu akan melihat bahwa nilai gid adalah 3000, sama dengan bagian runAsGroup. Jika runAsGroup diabaikan maka nilai gid akan
tetap bernilai 0(root) dan proses akan dapat berinteraksi dengan berkas-berkas yang dimiliki oleh grup root(0) dan yang memiliki
izin grup untuk grup root(0).
Keluarlah dari shell kamu:
exit
Melakukan konfigurasi izin volume dan kebijakan perubahan kepemilikan untuk Pod
FEATURE STATE:Kubernetes v1.18 [alpha]
Secara bawaan, Kubernetes mengubah kepemilikan dan izin secara rekursif untuk konten masing-masing
volume untuk mencocokkan fsGroup yang ditentukan dalam securityContext dari Pod pada saat volume itu
ditambatkan (mounted). Untuk volume yang besar, memeriksa dan mengubah kepemilikan dan izin dapat memerlukan waktu yang sangat lama,
sehingga memperlambat proses menjalankan Pod. Kamu dapat menggunakan bagian fsGroupChangePolicy dalam sebuah securityContext
untuk mengontrol cara Kubernetes memeriksa dan mengelola kepemilikan dan izin
untuk sebuah volume.
fsGroupChangePolicy - fsGroupChangePolicy mendefinisikan perilaku untuk mengubah kepemilikan dan izin volume
sebelum diekspos di dalam sebuah Pod. Bagian ini hanya berlaku untuk tipe volume yang mendukung
fsGroup untuk mengontrol kepemilikan dan izin. Bagian ini memiliki dua nilai yang dapat dimasukkan:
OnRootMismatch: Hanya mengubah izin dan kepemilikan jika izin dan kepemilikan dari direktori root tidak sesuai dengan izin volume yang diharapkan. Hal ini dapat membantu mempersingkat waktu yang diperlukan untuk mengubah kepemilikan dan izin sebuah volume.
Always: Selalu mengubah izin dan kepemilikan volume ketika volume sudah ditambatkan.
Ini adalah fitur alpha. Untuk menggunakannya, silahkan aktifkan gerbang fiturConfigurableFSGroupPolicy untuk kube-api-server, kube-controller-manager, dan kubelet.
Catatan: Bagian ini tidak berpengaruh pada tipe volume yang bersifat sementara (ephemeral) seperti
secret,
configMap,
dan emptydir.
Mengatur konteks keamanan untuk Container
Untuk menentukan aturan keamanan untuk suatu Container, sertakan bagian securityContext
dalam manifes Container. Bagian securityContext adalah sebuah objek
SecurityContext.
Aturan keamanan yang kamu tentukan untuk Container hanya berlaku untuk
Container secara individu, dan aturan tersebut menimpa aturan yang dibuat pada tingkat Pod apabila
ada aturan yang tumpang tindih. Aturan pada Container mempengaruhi volume pada Pod.
Berikut berkas konfigurasi untuk Pod yang hanya memiliki satu Container. Keduanya, baik Pod
dan Container memiliki bagian securityContext sebagai berikut:
Masuk ke dalam shell Container yang sedang berjalan tersebut:
kubectl exec -it security-context-demo-2 -- sh
Pada shell kamu, lihat daftar proses yang sedang berjalan:
ps aux
Keluarannya menunjukkan bahwa proses dijalankan oleh user dengan ID 2000, yang merupakan
nilai dari runAsUser seperti yang telah ditentukan untuk Container tersebut. Nilai tersebut menimpa nilai ID 1000 yang
ditentukan untuk Pod-nya.
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
2000 1 0.0 0.0 4336 764 ? Ss 20:36 0:00 /bin/sh -c node server.js
2000 8 0.1 0.5 772124 22604 ? Sl 20:36 0:00 node server.js
...
Keluar dari shell anda:
exit
Mengatur Kapabilitas untuk Container
Dengan menggunakan Kapabilitas Linux (Linux Capabilities),
kamu dapat memberikan wewenang tertentu kepada suatu proses tanpa memberikan semua wewenang
dari pengguna root. Untuk menambah atau menghapus Kapabilitas Linux pada suatu Container, masukkan
bagian capabilities pada securityContext di manifes Container-nya.
Pertama-tama, mari melihat apa yang terjadi ketika kamu tidak menyertakan bagian capabilities.
Berikut ini adalah berkas konfigurasi yang tidak menambah atau mengurangi kemampuan apa pun dari Container:
Buatlah catatan untuk bitmap dari kapabilitas tersebut, dan keluarlah dari shell kamu:
exit
Berikutnya, jalankan Container yang sama seperti dengan Container sebelumnya, namun
Container ini memiliki kapabilitas tambahan yang sudah ditentukan.
Berikut ini adalah berkas konfigurasi untuk Pod yang hanya menjalankan satu Container. Konfigurasi
ini menambahkan kapabilitas CAP_NET_ADMIN dan CAP_SYS_TIME:
Bandingkan kemampuan dari kedua Containers tersebut:
00000000a80425fb
00000000aa0435fb
Dalam bitmap kapabilitas pada Container pertama, bit-12 dan ke-25 tidak diatur. Sedangkan dalam Container kedua,
bit ke-12 dan ke-25 diatur. Bit ke-12 adalah kapabilitas CAP_NET_ADMIN, dan bit-25 adalah kapabilitas CAP_SYS_TIME.
Lihatlah capability.h
untuk nilai dari konstanta kapabilitas-kapabilitas yang lainnya.
Catatan: Konstanta kapabilitas Linux memiliki format CAP_XXX. Tetapi ketika kamu memasukkan daftar kemampuan dalam manifes Container kamu, kamu harus menghilangkan bagian CAP_ dari konstantanya. Misalnya, untuk menambahkan CAP_SYS_TIME, masukkan SYS_TIME ke dalam daftar kapabilitas Container kamu.
Memberikan label SELinux pada sebuah Container
Untuk memberikan label SELinux pada sebuah Container, masukkan bagian seLinuxOptions pada
bagian securityContext dari manifes Pod atau Container kamu.
Bagian seLinuxOptions adalah sebuah objek SELinuxOptions.
Berikut ini adalah contoh yang menerapkan sebuah level dari SELinux:
Catatan: Untuk menetapkan label SELinux, modul keamanan SELinux harus dimuat terlebih dahulu pada sistem operasi dari hosnya.
Diskusi
Konteks keamanan untuk sebuah Pod berlaku juga untuk Container yang berada dalam Pod tersebut dan juga untuk
volume dari Pod tersebut jika ada. Terkhusus untuk fsGroup dan seLinuxOptions
akan diterapkan pada volume seperti berikut:
fsGroup: Volume yang mendukung manajemen kepemilikan (ownership) akan dimodifikasi agar dapat dimiliki
dan ditulis oleh ID group (GID) yang disebutkan dalam fsGroup. Lihatlah
Dokumen Desain untuk Manajemen Kepemilikan
untuk lebih lanjut.
seLinuxOptions: Volume yang mendukung pelabelan SELinux akan dilabel ulang agar dapat diakses
oleh label yang ditentukan pada seLinuxOptions. Biasanya kamu hanya
perlu mengatur bagian level. Dimana ini akan menetapkan label
Keamanan multi-kategori (Multi-Category Security) (MCS)
yang diberikan kepada semua Container dalam Pod serta Volume yang ada didalamnya.
Peringatan: Setelah kamu menentukan label MCS untuk Pod, maka semua Pod dengan label yang sama dapat mengakses Volume tersebut. Jika kamu membutuhkan perlindungan antar Pod, kamu harus menetapkan label MCS yang unik untuk setiap Pod.
Bersih-bersih (Clean Up)
Hapus Pod-Pod tersebut:
kubectl delete pod security-context-demo
kubectl delete pod security-context-demo-2
kubectl delete pod security-context-demo-3
kubectl delete pod security-context-demo-4
ServiceAccount menyediakan identitas untuk proses yang sedang berjalan dalam sebuah Pod.
Catatan: Dokumen ini digunakan sebagai pengenalan untuk pengguna terhadap ServiceAccount dan menjelaskan bagaimana perilaku ServiceAccount dalam konfigurasi klaster seperti yang direkomendasikan Kubernetes. Pengubahan perilaku yang bisa saja dilakukan administrator klaster terhadap klaster tidak menjadi bagian pembahasan dokumentasi ini.
Ketika kamu mengakses klaster (contohnya menggunakan kubectl), kamu terautentikasi oleh apiserver sebagai sebuah akun pengguna (untuk sekarang umumnya sebagai admin, kecuali jika administrator klustermu telah melakukan pengubahan). Berbagai proses yang ada di dalam kontainer dalam Pod juga dapat mengontak apiserver. Ketika itu terjadi, mereka akan diautentikasi sebagai sebuah ServiceAccount (contohnya sebagai default).
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Menggunakan Default ServiceAccount untuk Mengakses API server.
Ketika kamu membuat sebuah Pod, jika kamu tidak menentukan sebuah ServiceAccount, maka ia akan otomatis ditetapkan sebagai ServiceAccountdefault di Namespace yang sama. Jika kamu mendapatkan json atau yaml mentah untuk sebuah Pod yang telah kamu buat (contohnya menggunakan kubectl get pods/<podname> -o yaml), kamu akan melihat fieldspec.serviceAccountName yang telah secara otomatis ditentukan.
Kamu dapat mengakses API dari dalam Pod menggunakan kredensial ServiceAccount yang ditambahkan secara otomatis seperti yang dijelaskan dalam Mengakses Klaster.
Hak akses API dari ServiceAccount menyesuaikan dengan kebijakan dan plugin otorisasi yang sedang digunakan.
Di versi 1.6+, kamu dapat tidak memilih automounting kredensial API dari sebuah ServiceAccount dengan mengatur automountServiceAccountToken: false pada ServiceAccount:
Pengaturan dari spesifikasi Pod didahulukan dibanding ServiceAccount jika keduanya menentukan nilai dari automountServiceAccountToken.
Menggunakan Beberapa ServiceAccount.
Setiap Namespace memiliki sumber daya ServiceAccount standar default.
Kamu dapat melihatnya dan sumber daya serviceAccount lainnya di Namespace tersebut dengan perintah:
kubectl get serviceaccounts
Keluarannya akan serupa dengan:
NAME SECRETS AGE
default 1 1d
Kamu dapat membuat objek ServiceAccount tambahan seperti ini:
Untuk menggunakan ServiceAccount selain nilai standar, atur fieldspec.serviceAccountName dari Pod menjadi nama dari ServiceAccount yang hendak kamu gunakan.
Service account harus ada ketika Pod dibuat, jika tidak maka akan ditolak.
Kamu tidak dapat memperbarui ServiceAccount dari Pod yang telah dibuat.
Kamu dapat menghapus ServiceAccount dari contoh seperti ini:
kubectl delete serviceaccount/build-robot
Membuat token API ServiceAccount secara manual.
Asumsikan kita memiliki ServiceAccount dengan nama "build-robot" seperti yang disebukan di atas, dan kita membuat Secret secara manual.
Menggunakan editor pilihanmu (misalnya vi), buka berkas sa.yaml, hapus baris dengan key resourceVersion, tambahkan baris dengan imagePullSecrets: dan simpan.
Memverifikasi imagePullSecrets sudah ditambahkan ke spesifikasi Pod
Ketika Pod baru dibuat dalam Namespace yang sedang aktif dan menggunakan ServiceAccount, Pod baru akan memiliki fieldspec.imagePullSecrets yang ditentukan secara otomatis:
kubectl run nginx --image=nginx --restart=Never
kubectl get pod nginx -o=jsonpath='{.spec.imagePullSecrets[0].name}{"\n"}'
Keluarannya adalah:
myregistrykey
ServiceAccountTokenVolumeProjection
FEATURE STATE:Kubernetes v1.12 [beta]
Catatan:
ServiceAccountTokenVolumeProjection masih dalam tahap beta untuk versi 1.12 dan diaktifkan dengan memberikan flag berikut ini ke API server:
--service-account-issuer
--service-account-signing-key-file
--service-account-api-audiences
Kubelet juga dapat memproyeksikan token ServiceAccount ke Pod. Kamu dapat menentukan properti yang diinginkan dari token seperti target pengguna dan durasi validitas. Properti tersebut tidak dapat diubah pada token ServiceAccount standar. Token ServiceAccount juga akan menjadi tidak valid terhadap API ketika Pod atau ServiceAccount dihapus.
Perilaku ini diatur pada PodSpec menggunakan tipe ProjectedVolume yaitu ServiceAccountToken. Untuk memungkinkan Pod dengan token dengan pengguna bertipe "vault" dan durasi validitas selama dua jam, kamu harus mengubah bagian ini pada PodSpec:
Token yang mewakili Pod akan diminta dan disimpan kubelet, lalu kubelet akan membuat token yang dapat diakses oleh Pod pada file path yang ditentukan, dan melakukan refreshtoken ketika telah mendekati waktu berakhir. Token akan diganti oleh kubelet jika token telah melewati 80% dari total TTL, atau jika token telah melebihi waktu 24 jam.
Aplikasi bertanggung jawab untuk memuat ulang token ketika terjadi penggantian. Pemuatan ulang teratur (misalnya sekali setiap 5 menit) cukup untuk mencakup kebanyakan kasus.
ServiceAccountIssuerDiscovery
FEATURE STATE:Kubernetes v1.18 [alpha]
Fitur ServiceAccountIssuerDiscovery diaktifkan dengan mengaktifkan gerbang fiturServiceAccountIssuerDiscovery dan mengaktifkan fitur Service Account Token Volume Projection seperti yang telah dijelaskan di atas.
Catatan:
URL issuer harus sesuai dengan OIDC Discovery Spec. Pada implementasinya, hal ini berarti URL harus menggunakan skema https dan harus menyediakan konfigurasi penyedia OpenID pada {service-account-issuer}/.well-known/openid-configuration.
Jika URL tidak sesuai dengan aturan, endpointServiceAccountIssuerDiscovery tidak akan didaftarkan meskipun fitur telah diaktifkan.
Fitur Service Account Issuer Discovery memungkinkan federasi dari berbagai token ServiceAccount Kubernetes yang dibuat oleh sebuah klaster (penyedia identitas) dan sistem eksternal.
Ketika diaktifkan, server API Kubernetes menyediakan dokumen OpenID Provider Configuration pada /.well-known/openid-configuration dan JSON Web Key Set (JWKS) terkait pada /openid/v1/jwks. OpenID Provider Configuration terkadang disebut juga dengan sebutan discovery document.
Ketika diaktifkan, klaster juga dikonfigurasi dengan RBAC ClusterRole standar yaitu system:service-account-issuer-discovery. Role binding tidak disediakan secara default. Administrator dimungkinkan untuk, sebagai contoh, menentukan apakah peran akan disematkan ke system:authenticated atau system:unauthenticated tergantung terhadap kebutuhan keamanan dan sistem eksternal yang direncakanan untuk diintegrasikan.
Catatan: Respons yang disediakan pada /.well-known/openid-configuration dan/openid/v1/jwks dirancang untuk kompatibel dengan OIDC, tetapi tidak sepenuhnya sesuai dengan ketentuan OIDC. Dokumen tersebut hanya berisi parameter yang dibutuhkan untuk melakukan validasi terhadap token ServiceAccount Kubernetes.
Respons JWKS memuat kunci publik yang dapat digunakan oleh sistem eksternal untuk melakukan validasi token ServiceAccount Kubernetes. Awalnya sistem eksternal akan mengkueri OpenID Provider Configuration, dan selanjutnya dapat menggunakan fieldjwks_uri pada respons kueri untuk mendapatkan JWKS.
Pada banyak kasus, server API Kubernetes tidak tersedia di internet publik, namun endpoint publik yang menyediakan respons hasil cache dari server API dapat dibuat menjadi tersedia oleh pengguna atau penyedia servis. Pada kasus ini, dimungkinkan untuk mengganti jwks_uri pada OpenID Provider Configuration untuk diarahkan ke endpoint publik sebagai ganti alamat server API dengan memberikan flag--service-account-jwks-uri ke API server. serupa dengan URL issuer, URI JWKS diharuskan untuk menggunakan skema https.
Laman ini menunjukkan cara membuat Pod dengan menggunakan Secret untuk menarik image dari sebuah
register atau repositori pribadi untuk Docker.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Catatan: Jika kamu menggunakan tempat penyimpanan kredensial (credential) untuk Docker, maka kamu tidak akan melihat entri auth tetapi entri credsStore dengan nama tempat penyimpanan sebagai nilainya.
Membuat Secret berdasarkan kredensial Docker yang sudah ada
Klaster Kubernetes menggunakan Secret dari tipe docker-registry untuk melakukan autentikasi dengan
register Container untuk menarik image pribadi.
Jika kamu sudah menjalankan docker login, kamu dapat menyalin kredensial itu ke Kubernetes:
Jika kamu memerlukan lebih banyak kontrol (misalnya, untuk mengatur Namespace atau label baru pada Secret)
maka kamu dapat menyesuaikan Secret tersebut sebelum menyimpannya.
Pastikan untuk:
Mengatur nama dari pokok (item) data menjadi .dockerconfigjson
Melakukan enkode secara base64 dari Dockerfile (berkas Docker) dan memindahkan urutan huruf (string) tersebut, secara tidak terputus sebagai nilai untuk bidang data[".dockerconfigjson"]
Mengatur type menjadi kubernetes.io/dockerconfigjson
Jika kamu mendapat pesan kesalahan error: no objects passed to create, ini berarti pengkodean base64 dari urutan huruf tersebut tidak valid.
Jika kamu mendapat pesan kesalahan seperti Secret "myregistrykey" is invalid: data[.dockerconfigjson]: invalid value ..., ini berarti
enkode base64 dari urutan huruf dalam data tersebut sukses didekodekan, tetapi tidak bisa diuraikan menjadi berkas .docker/config.json.
Membuat Secret dengan memberikan kredensial pada baris perintah
<your-registry-server> merupakan FQDN dari register privat Docker kamu. (https://index.docker.io/v1/ untuk DockerHub)
<your-name> adalah nama pengguna Docker kamu.
<your-pword> adalah kata sandi Docker kamu.
<your-email> adalah alamat email Docker kamu.
Kamu telah berhasil mengatur kredensial untuk Docker kamu pada klaster sebagai sebuah Secret yang dipanggil dengan nama regcred.
Catatan: Mengetik Secret pada baris perintah dapat menyimpannya dalam riwayat (history) dari shell kamu tanpa perlindungan, dan
Secret tersebut mungkin juga terlihat oleh pengguna lain dalam PC kamu selama perintah kubectl sedang berjalan.
Menginspeksi Secret regcred
Untuk memahami isi Secret regcred yang baru saja kamu buat, mulailah dengan melihat Secret dalam format YAML:
Untuk menarik image dari register pribadi, Kubernetes memerlukan kredensial.
Bidang imagePullSecrets dalam berkas konfigurasi menentukan bahwa Kubernetes harus mendapatkan kredensial dari Secret yang bernama regcred.
Buatlah Pod yang menggunakan Secret kamu, dan verifikasi bahwa Pod tersebut berjalan:
kubectl apply -f my-private-reg-pod.yaml
kubectl get pod private-reg
3.8 - Mengatur Probe Liveness, Readiness dan Startup
Laman ini memperlihatkan bagaimana cara untuk mengatur probe liveness, readiness, dan
startup untuk Container.
Probe liveness digunakan oleh kubelet untuk mengetahui
kapan perlu mengulang kembali (restart) sebuah Container. Sebagai contoh, probe liveness
dapat mendeteksi deadlock, ketika aplikasi sedang berjalan tapi tidak dapat berfungsi dengan baik.
Mengulang Container dengan state tersebut dapat membantu ketersediaan aplikasi yang lebih baik
walaupun ada kekutu (bug).
Probe readiness digunakan oleh kubelet untuk mengetahui kapan sebuah Container telah siap untuk
menerima lalu lintas jaringan (traffic). Suatu Pod dianggap siap saat semua Container di dalamnya telah
siap. Sinyal ini berguna untuk mengontrol Pod-Pod mana yang digunakan sebagai backend dari Service.
Ketika Pod dalam kondisi tidak siap, Pod tersebut dihapus dari Service load balancer.
Probe startup digunakan oleh kubelet untuk mengetahui kapan sebuah aplikasi Container telah mulai berjalan.
Jika probe tersebut dinyalakan, probe akan menonaktifkan pemeriksaan liveness dan readiness sampai
berhasil, kamu harus memastikan probe tersebut tidak mengganggu startup dari aplikasi.
Mekanisme ini dapat digunakan untuk mengadopsi pemeriksaan liveness pada saat memulai Container yang lambat,
untuk menghindari Container dimatikan oleh kubelet sebelum Container mulai dan berjalan.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Kebanyakan aplikasi yang telah berjalan dalam waktu lama pada akhirnya akan
bertransisi ke state yang rusak (broken), dan tidak dapat pulih kecuali diulang kembali.
Kubernetes menyediakan probe liveness untuk mendeteksi dan memperbaiki situasi tersebut.
Pada latihan ini, kamu akan membuat Pod yang menjalankan Container dari image
k8s.gcr.io/busybox. Berikut ini adalah berkas konfigurasi untuk Pod tersebut:
Pada berkas konfigurasi di atas, kamu dapat melihat bahwa Pod memiliki satu Container.
FieldperiodSeconds menentukan bahwa kubelet harus melakukan probe liveness setiap 5 detik.
FieldinitialDelaySeconds memberitahu kubelet untuk menunggu 5 detik sebelum mengerjakan
probe yang pertama. Untuk mengerjakan probe, kubelet menjalankan perintah cat /tmp/healthy
pada Container tujuan. Jika perintah berhasil, kode 0 akan dikembalikan, dan kubelet menganggap
Container sedang dalam kondisi hidup (alive) dan sehat (healthy). Jika perintah mengembalikan
kode selain 0, maka kubelet akan mematikan Container dan mengulangnya kembali.
Saat dimulai, Container akan menjalankan perintah berikut:
Container memiliki berkas /tmp/healthy pada saat 30 detik pertama setelah dijalankan.
Kemudian, perintah cat /tmp/healthy mengembalikan kode sukses. Namun setelah 30 detik,
cat /tmp/healthy mengembalikan kode gagal.
Keluaran dari perintah tersebut memperlihatkan bahwa belum ada probe liveness yang gagal:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
24s 24s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "k8s.gcr.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "k8s.gcr.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
Setelah 35 detik, lihatlah lagi event Pod tersebut:
kubectl describe pod liveness-exec
Baris terakhir dari keluaran tersebut memperlihatkan pesan bahwa probe liveness
mengalami kegagalan, dan Container telah dimatikan dan dibuat ulang.
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37s 37s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "k8s.gcr.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "k8s.gcr.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Tunggu 30 detik lagi, dan verifikasi bahwa Container telah diulang kembali:
kubectl get pod liveness-exec
Keluaran perintah tersebut memperlihatkan bahwa jumlah RESTARTS telah meningkat:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
Mendefinisikan probe liveness dengan permintaan HTTP
Jenis kedua dari probe liveness menggunakan sebuah permintaan GET HTTP. Berikut ini
berkas konfigurasi untuk Pod yang menjalankan Container dari image k8s.gcr.io/liveness.
Pada berkas konfigurasi tersebut, kamu dapat melihat Pod memiliki sebuah Container.
FieldperiodSeconds menentukan bahwa kubelet harus mengerjakan probe liveness setiap 3 detik.
FieldinitialDelaySeconds memberitahu kubelet untuk menunggu 3 detik sebelum mengerjakan
probe yang pertama. Untuk mengerjakan probe tersebut, kubelet mengirimkan sebuah permintaan
GET HTTP ke server yang sedang berjalan di dalam Container dan mendengarkan (listen) pada porta 8080.
Jika handler path/healthz yang dimiliki server mengembalikan kode sukses, kubelet menganggap
Container sedang dalam kondisi hidup dan sehat. Jika handler mengembalikan kode gagal,
kubelet mematikan Container dan mengulangnya kembali.
Kode yang lebih besar atau sama dengan 200 dan kurang dari 400 mengindikasikan kesuksesan.
Kode selain ini mengindikasikan kegagalan.
Kamu dapat melihat kode program untuk server ini pada server.go.
Untuk 10 detik pertama setelah Container hidup (alive), handler/healthz mengembalikan
status 200. Setelah itu, handler mengembalikan status 500.
Pemeriksaan kesehatan (health check) dilakukan kubelet 3 detik setelah Container dimulai,
sehingga beberapa pemeriksaaan pertama akan berhasil. Namun setelah 10 detik,
pemeriksaan akan gagal, dan kubelet akan mematikan dan mengulang Container kembali.
Untuk mencoba pemeriksaan liveness HTTP, marilah membuat sebuah Pod:
Setelah 10 detik, lihatlah event Pod untuk memverifikasi bahwa probe liveness
telah gagal dan Container telah diulang kembali:
kubectl describe pod liveness-http
Untuk rilis sebelum v1.13 (termasuk v1.13), jika variabel lingkungan
http_proxy (atau HTTP_PROXY) telah diatur pada Node dimana Pod
berjalan, probe liveness HTTP akan menggunakan proksi tersebut.
Untuk rilis setelah v1.13, pengaturan variabel lingkungan pada proksi HTTP lokal
tidak mempengaruhi probe liveness HTTP.
Mendefinisikan probe liveness TCP
Jenis ketiga dari probe liveness menggunakaan sebuah soket TCP. Dengan konfigurasi ini,
kubelet akan mencoba untuk membuka soket pada Container kamu dengan porta tertentu.
Jika koneksi dapat terbentuk dengan sukses, maka Container dianggap dalam kondisi sehat.
Namun jika tidak berhasil terbentuk, maka Container dianggap gagal.
Seperti yang terlihat, konfigurasi untuk pemeriksaan TCP cukup mirip dengan
pemeriksaan HTTP. Contoh ini menggunakan probe readiness dan liveness.
Probe readiness yang pertama akan dikirimkan oleh kubelet, 5 detik setelah
Container mulai dijalankan. Container akan coba dihubungkan oleh kubelet dengan
goproxy pada porta 8080. Jika probe berhasil, maka Pod akan ditandai menjadi
ready. Pemeriksaan ini akan dilanjutkan oleh kubelet setiap 10 detik.
Selain probe readiness, probe liveness juga termasuk di dalam konfigurasi.
Probe liveness yang pertama akan dijalankan oleh kubelet, 15 detik setelah Container
mulai dijalankan. Sama seperti probe readiness, kubelet akan mencoba untuk
terhubung dengan Container goproxy pada porta 8080. Jika probe liveness gagal,
maka Container akan diulang kembali.
Untuk mencoba pemeriksaan liveness TCP, marilah membuat sebuah Pod:
Melindungi Container yang lambat untuk dimulai dengan probe startup
Terkadang kamu harus berurusan dengan aplikasi peninggalan (legacy) yang
memerlukan waktu tambahan untuk mulai berjalan pada saat pertama kali diinisialisasi.
Pada kasus ini, cukup rumit untuk mengatur parameter probe liveness tanpa
mengkompromikan respons yang cepat terhadap deadlock yang memotivasi digunakannya
probe_ tersebut. Triknya adalah mengatur _probe startup_ dengan perintah yang sama,
baik pemeriksaan HTTP ataupun TCP, dengan failureThreshold * periodSeconds yang
mencukupi untuk kemungkinan waktu memulai yang terburuk.
Berkat probe startup, aplikasi akan memiliki paling lambat 5 menit (30 * 10 = 300 detik)
untuk selesai memulai.
Ketika probe startup telah berhasil satu kali, maka probe liveness akan
mengambil alih untuk menyediakan respons cepat terhadap deadlock Container.
Jika probe startup tidak pernah berhasil, maka Container akan dimatikan setelah
300 detik dan perilakunya akan bergantung pada restartPolicy yang dimiliki Pod.
Mendefinisikan probe readiness
Terkadang aplikasi tidak dapat melayani lalu lintas jaringan sementara.
Contohnya, aplikasi mungkin perlu untuk memuat data besar atau berkas konfigurasi
saat dimulai, atau aplikasi bergantung pada layanan eksternal setelah dimulai.
Pada kasus-kasus ini, kamu tidak ingin mematikan aplikasi, tetapi kamu tidak
ingin juga mengirimkan permintaan ke aplikasi tersebut. Kubernetes menyediakan
probe readiness sebagai solusinya. Sebuah Pod dengan Container yang melaporkan
dirinya tidak siap, tidak akan menerima lalu lintas jaringan dari Kubernetes Service.
Catatan:Probe readiness dijalankan di dalam Container selama siklus hidupnya.
Probe readiness memiliki pengaturan yang mirip dengan probe liveness. Perbedaan
satu-satunya adalah kamu menggunakan fieldreadinessProbe, bukan fieldlivenessProbe.
Pengaturan untuk probe readiness untuk HTTP dan TCP juga sama persis dengan
pengaturan untuk probe liveness.
Probe readiness dan liveness dapat digunakan secara bersamaan untuk
Container yang sama. Apabila keduanya digunakan sekaligus, lalu lintas jaringan
tidak akan sampai ke Container yang belum siap, dan Container akan diulang kembali
(restart) saat mengalami kegagalan.
Mengatur Probe
Probe memiliki
beberapa field yang dapat digunakan untuk mengendalikan pemeriksaan liveness dan readiness
secara presisi.
initialDelaySeconds: Durasi dalam detik setelah Container dimulai,
sebelum probe liveness atau readiness diinisiasi. Nilai bawaannya adalah 0 detik. Nilai minimalnya adalah 0.
periodSeconds: Seberapa sering (dalam detik) probe dijalankan. Nilai bawaannya adalah 10 detik.
Nilai minimalnya adalah 0.
timeoutSeconds: Durasi dalam detik setelah probe mengalami timeout. Nilai bawaannya adalah 1 detik.
Nilai minimalnya adalah 0.
successThreshold: Jumlah minimal sukses yang berurutan untuk probe dianggap berhasil
setelah mengalami kegagalan. Nilai bawaannya adalah 1. Nilanya harus 1 untuk liveness.
Nilai minimalnya adalah 1.
failureThreshold: Ketika sebuah Pod dimulai dan probe mengalami kegagalan, Kubernetes
akan mencoba beberapa kali sesuai nilai failureThreshold sebelum menyerah. Menyerah dalam
kasus probe liveness berarti Container akan diulang kembali. Untuk probe readiness, menyerah
akan menandai Pod menjadi "tidak siap" (Unready). Nilai bawaannya adalah 3. Nilai minimalnya adalah 1.
Probe HTTP
memiliki field-field tambahan yang bisa diatur melalui httpGet:
host: Nama dari host yang akan terhubung, nilai bawaannya adalah IP dari Pod. Kamu mungkin
juga ingin mengatur "Host" pada httpHeaders.
scheme: Skema yang digunakan untuk terhubung pada host (HTTP atau HTTPS). Nilai bawaannya adalah HTTP.
path: Path untuk mengakses server HTTP.
httpHeaders: Header khusus yang diatur dalam permintaan HTTP. HTTP memperbolehkan header yang berulang.
port: Nama atau angka dari porta untuk mengakses Container. Angkanya harus ada di antara 1 sampai 65535.
Untuk sebuah probe HTTP, kubelet mengirimkan permintaan HTTP untuk path yang ditentukan
dan porta untuk mengerjakan pemeriksaan. Probe dikirimkan oleh kubelet untuk alamat IP Pod,
kecuali saat alamat digantikan oleh field opsional pada httpGet. Jika fieldscheme
diatur menjadi HTTPS, maka kubelet mengirimkan permintaan HTTPS dan melewati langkah verifikasi
sertifikat. Pada skenario kebanyakan, kamu tidak menginginkan fieldhost.
Berikut satu skenario yang memerlukan host. Misalkan Container mendengarkan permintaan
melalui 127.0.0.1 dan fieldhostNetwork pada Pod bernilai true. Kemudian host, melalui
httpGet, harus diatur menjadi 127.0.0.1. Jika Pod kamu bergantung pada host virtual, dimana
untuk kasus-kasus umum, kamu tidak perlu menggunakan host, tetapi perlu mengatur headerHost pada httpHeaders.
Untuk probe TCP, kubelet membuat koneksi probe pada Node, tidak pada Pod, yang berarti bahwa
kamu tidak menggunakan nama Service di dalam parameter host karena kubelet tidak bisa
me-resolve-nya.
3.9 - Menempatkan Pod pada Node Menggunakan Afinitas Pod
Dokumen ini menunjukkan cara menempatkan Pod Kubernetes pada sebuah Node menggunakan
Afinitas Node di dalam klaster Kubernetes.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Kubernetes servermu harus dalam versi yang sama atau lebih baru dari v1.10.
Untuk melihat versi, tekan kubectl version.
Menambahkan sebuah Label pada sebuah Node
Jabarkan Node-Node yang ada pada klaster kamu, bersamaan dengan label yang ada:
kubectl get nodes --show-labels
Keluaran dari perintah tersebut akan berupa:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
Pilihkan salah satu dari Node yang ada dan tambahkan label pada Node tersebut.
kubectl label nodes <nama-node-kamu> disktype=ssd
dimana <nama-node-kamu> merupakan nama dari Node yang kamu pilih.
Keluaran dari Node yang kamu pilih dan sudah memiliki label disktype=ssd:
kubectl get nodes --show-labels
Keluaran dari perintah tersebut akan berupa:
NAME STATUS ROLES AGE VERSION LABELS
worker0 Ready <none> 1d v1.13.0 ...,disktype=ssd,kubernetes.io/hostname=worker0
worker1 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker1
worker2 Ready <none> 1d v1.13.0 ...,kubernetes.io/hostname=worker2
Pada keluaran dari perintah di atas, kamu dapat melihat bahwa Node worker0
memiliki label disktype=ssd.
Menjadwalkan Pod menggunakan Afinitas Node
Konfigurasi ini menunjukkan sebuah Pod yang memiliki afinitas node requiredDuringSchedulingIgnoredDuringExecution, disktype: ssd.
Dengan kata lain, Pod hanya akan dijadwalkan hanya pada Node yang memiliki label disktype=ssd.
Verifikasi apakah Pod yang kamu pilih sudah dijalankan pada Node yang kamu pilih:
kubectl get pods --output=wide
Keluaran dari perintah tersebut akan berupa:
NAME READY STATUS RESTARTS AGE IP NODE
nginx 1/1 Running 0 13s 10.200.0.4 worker0
Jadwalkan Pod menggunakan Afinitas Node yang Dipilih
Konfigurasi ini memberikan deskripsi sebuah Pod yang memiliki afinitas Node preferredDuringSchedulingIgnoredDuringExecution,disktype: ssd.
Artinya Pod akan diutamakan dijalankan pada Node yang memiliki label disktype=ssd.
ConfigMap mengizinkan kamu untuk memisahkan artifak-artifak konfigurasi dari konten image untuk menjaga aplikasi yang dikontainerisasi tetap portabel. Artikel ini menyediakan sekumpulan contoh penerapan yang mendemonstrasikan bagaimana cara membuat ConfigMap dan mengatur Pod menggunakan data yang disimpan di dalam ConfigMap.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Kamu dapat menggunakan kubectl create configmap ataupun generator ConfigMap pada kustomization.yaml untuk membuat sebuah ConfigMap. Perlu diingat bahwa kubectl mulai mendukung kustomization.yaml sejak versi 1.14.
Membuat ConfigMap Menggunakan kubectl create configmap
di mana <map-name> merupakan nama yang ingin kamu berikan pada ConfigMap tersebut dan <data-source> adalah direktori, berkas, atau nilai harfiah yang digunakan sebagai sumber data.
Nama dari sebuah objek ConfigMap haruslah berupa
nama subdomain DNS yang sah.
Ketika kamu membuat ConfigMap dari sebuah berkas, secara bawaan, basename dari berkas tersebut akan menjadi kunci pada <data-source>, dan isi dari berkas tersebut akan menjadi nilai dari kunci tersebut.
Kamu dapat menggunakan kubectl describe atau
kubectl get untuk mengambil informasi
mengenai sebuah ConfigMap.
Membuat ConfigMap dari direktori
Kamu dapat menggunakan kubectl create configmap untuk membuat sebuah ConfigMap dari banyak berkas dalam sebuah direktori yang sama. Ketika kamu membuat sebuah ConfigMap dari sebuah direktori, kubectl akan mengidentifikasi berkas-berkas yang memiliki basename yang merupakan sebuah kunci yang sah pada direktori dan mengemas tiap berkas tersebut ke dalam sebuah ConfigMap baru. Seluruh entri direktori kecuali berkas reguler akan diabaikan (subdirektori, symlink, device, pipe, dsb).
Sebagai contoh:
# Membuat direktori lokal
mkdir -p configure-pod-container/configmap/
# Mengunduh berkas-berkas sampel ke dalam direktori `configure-pod-container/configmap/`
wget https://kubernetes.io/examples/configmap/game.properties -O configure-pod-cont1ainer/configmap/game.properties
wget https://kubernetes.io/examples/configmap/ui.properties -O configure-pod-container/configmap/ui.properties
# Membuat configmap
kubectl create configmap game-config --from-file=configure-pod-container/configmap/
Perintah di atas mengemas tiap berkas, dalam kasus ini, game.properties dan ui.properties dalam direktori configure-pod-container/configmap/ ke dalam ConfigMap dengan nama game-config. Kamu dapat menampilkan detail dari ConfigMap menggunakan perintah berikut:
Gunakan opsi --from-env-file untuk membuat sebuah ConfigMap dari sebuah env-file, sebagai contoh:
# Env-file berisi sebuah daftar variabel _environment_.# Ada aturan-aturan sintaks yang berlaku:# Tiap baris pada sebuah env file harus memiliki format VAR=VAL.# Baris yang diawali # (komentar) akan diabaikan.# Baris-baris kosong akan diabaikan.# Tidak ada penanganan spesial untuk tanda kutip (tanda kutip akan menjadi bagian dari nilai pada ConfigMap).# Mengunduh berkas-berkas sampel berikut ke dalam direktori `configure-pod-container/configmap/`
wget https://kubernetes.io/examples/configmap/game-env-file.properties -O configure-pod-container/configmap/game-env-file.properties
# Berkas env-file `game-env-file.properties` berisi sebagai berikut:
cat configure-pod-container/configmap/game-env-file.properties
enemies=aliens
lives=3allowed="true"# Komentar ini dan baris kosong di atasnya akan diabaikan.
Perhatian: Ketika memasukkan --from-env-file beberapa kali untuk membuat sebuah ConfigMap dari beberapa sumber data, hanya env-file terakhir yang akan digunakan.
Contoh perilaku memasukkan --from-env-file beberapa kali didemonstrasikan dengan:
# Mengunduh berkas-berkas sampel berikut ke dalam direktori `configure-pod-container/configmap/`
wget https://kubernetes.io/examples/configmap/ui-env-file.properties -O configure-pod-container/configmap/ui-env-file.properties
# Membuat configmap
kubectl create configmap config-multi-env-files \
--from-env-file=configure-pod-container/configmap/game-env-file.properties \
--from-env-file=configure-pod-container/configmap/ui-env-file.properties
akan menghasilkan ConfigMap sebagai berikut:
kubectl get configmap config-multi-env-files -o yaml
di mana <my-key-name> merupakan kunci yang ingin kamu gunakan pada ConfigMap dan <path-to-file> merupakan lokasi dari berkas sumber data yang akan menjadi nilai dari kunci tersebut.
Kamu dapat memasukkan beberapa pasang kunci-nilai. Tiap pasang yang dimasukkan pada command line direpresentasikan sebagai sebuah entri terpisah pada bagian data dari ConfigMap.
kubectl mendukung kustomization.yaml sejak versi 1.14.
Kamu juga dapat membuat ConfigMap dari generator lalu menggunakannya untuk membuat objek tersebut pada
peladen API. Generator
harus dituliskan pada kustomization.yaml dalam sebuah direktori.
Menghasilkan ConfigMap dari berkas
Sebagai contoh, untuk menghasilkan ConfigMap dari berkas configure-pod-container/configmap/game.properties
# Membuat berkas kustomization.yaml dengan ConfigMapGenerator
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: game-config-4
files:
- configure-pod-container/configmap/game.properties
EOF
Gunakan direktori kustomization untuk membuat objek ConfigMap.
kubectl apply -k .
configmap/game-config-4-m9dm2f92bt created
Kamu dapat melihat ConfigMap yang dihasilkan seperti berikut:
kubectl get configmap
NAME DATA AGE
game-config-4-m9dm2f92bt 1 37s
kubectl describe configmaps/game-config-4-m9dm2f92bt
Name: game-config-4-m9dm2f92bt
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","data":{"game.properties":"enemies=aliens\nlives=3\nenemies.cheat=true\nenemies.cheat.level=noGoodRotten\nsecret.code.p...
Data
====
game.properties:
----
enemies=aliens
lives=3
enemies.cheat=true
enemies.cheat.level=noGoodRotten
secret.code.passphrase=UUDDLRLRBABAS
secret.code.allowed=true
secret.code.lives=30
Events: <none>
Perlu diingat baha nama dari ConfigMap yang dihasilkan memiliki sufiks yang ditambahkan dengan melakukan hashing terhadap konten dari ConfigMap tersebut. Hal ini memastikan bahwa
sebuah ConfigMap baru akan dihasilkan setiap kali konten dimodifikasi.
Menentukan kunci yang akan digunakan ketika generating ConfigMap dari sebuah berkas
Kamu dapat menentukan kunci selain nama berkas untuk digunakan pada generator ConfigMap.
Sebagai contoh, untuk menghasilkan sebuah ConfigMap dari berkas configure-pod-container/configmap/game.properties
dengan kunci game-special-key
# Membuat berkas kustomization.yaml dengan ConfigMapGenerator
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: game-config-5
files:
- game-special-key=configure-pod-container/configmap/game.properties
EOF
Gunakan direktori kustomization untuk membuat objek ConfigMap.
kubectl apply -k .
configmap/game-config-5-m67dt67794 created
Menghasilkan ConfigMap dari Nilai-nilai Harfiah
Untuk menghasilkan ConfigMap dari nilai-nilai harfiah special.type=charm dan special.how=very,
kamu dapat menentukan generator ConfigMap pada kustomization.yaml sebagai berikut
# Membuat berkas kustomization.yaml dengan ConfigMapGenerator
cat <<EOF >./kustomization.yaml
configMapGenerator:
- name: special-config-2
literals:
- special.how=very
- special.type=charm
EOF
Gunakan direktori kustomization untuk membuat objek ConfigMap.
kubectl apply -k .
configmap/special-config-2-c92b5mmcf2 created
Menentukan variabel environment kontainer menggunakan data ConfigMap
Menentukan variabel environment kontainer dengan data dari sebuah ConfigMap
Menentukan sebuah variabel environment sebagai sepasang kunci-nilai pada ConfigMap:
apiVersion:v1kind:Podmetadata:name:dapi-test-podspec:containers:- name:test-containerimage:k8s.gcr.io/busyboxcommand:["/bin/sh","-c","env"]env:# Tentukan variabel environment- name:SPECIAL_LEVEL_KEYvalueFrom:configMapKeyRef:# ConfigMap berisi nilai yang ingin kamu berikan pada SPECIAL_LEVEL_KEYname:special-config# Tentukan kunci yang diasosiasikan dengan nilainyakey:special.howrestartPolicy:Never
Gunakan envFrom untuk menentukan seluruh data pada ConfigMap sebagai variabel environment kontainer. Kunci dari ConfigMap akan menjadi nama variabel environment di dalam Pod.
Sekarang, Pod keluaran pod meliputi variabel environmentSPECIAL_LEVEL=very dan SPECIAL_TYPE=charm.
Menggunakan variabel environment yang ditentukan ConfigMap pada perintah Pod
Kamu dapat menggunakan variabel environment yang ditentukan ConfigMap pada bagian command dari spesifikasi Pod menggunakan sintaks substitusi Kubernetes $(VAR_NAME).
menghasilkan keluaran pada kontainer test-container seperti berikut:
very charm
Menambahkan data ConfigMap pada Volume
Seperti yang sudah dijelaskan pada Membuat ConfigMap dari berkas, ketika kamu membuat ConfigMap menggunakan --from-file, nama dari berkas tersebut akan menjadi kunci yang disimpan pada bagian data dari ConfigMap. Isi berkas tersebut akan menjadi nilai dari kunci tersebut.
Contoh pada bagian ini merujuk pada ConfigMap bernama special-config, Seperti berikut.
Mengisi Volume dengan data yang disimpan Pada ConfigMap
Tambahkan nama ConfigMap di bawah bagian volumes pada spesifikasi Pod.
Hal ini akan menambahkan data ConfigMap pada direktori yang ditentukan oleh volumeMounts.mountPath (pada kasus ini, /etc/config).
Bagian command berisi daftar berkas pada direktori dengan nama-nama yang sesuai dengan kunci-kunci pada ConfigMap.
apiVersion:v1kind:Podmetadata:name:dapi-test-podspec:containers:- name:test-containerimage:k8s.gcr.io/busyboxcommand:["/bin/sh","-c","ls /etc/config/"]volumeMounts:- name:config-volumemountPath:/etc/configvolumes:- name:config-volumeconfigMap:# Berikan nama dari ConfigMap yang berisi berkas-berkas yang ingin kamu# tambahkan ke kontainername:special-configrestartPolicy:Never
Ketika Pod berjalan, perintah ls /etc/config/ akan menghasilkan keluaran di bawah:
SPECIAL_LEVEL
SPECIAL_TYPE
Perhatian: Jika ada beberapa berkas pada direktori /etc/config/, berkas-berkas tersebut akan dihapus.
Menambahkan data ConfigMap pada jalur tertentu pada Volume
Gunakan kolom path untuk menentukan jalur berkas yang diinginkan untuk butir tertentu pada ConfigMap (butir ConfigMap tertentu).
Pada kasus ini, butir SPECIAL_LEVEL akan akan dipasangkan sebagai config-volume pada /etc/config/keys.
Ketika Pod berjalan, perintah cat /etc/config/keys akan menghasilkan keluaran di bawah:
very
Perhatian: Seperti sebelumnya, semua berkas yang sebelumnya berada pada direktori /etc/config/ akan dihapus.
Memproyeksikan kunci ke jalur dan perizinan berkas tertentu
Kamu dapat memproyeksikan kunci ke jalur dan perizinan tertentu pada setiap
berkas. Panduan pengguna Secret menjelaskan mengenai sintaks-sintaksnya.
ConfigMap yang dipasang akan diperbarui secara otomatis
Ketika sebuah ConfigMap yang sudah dipasang pada sebuah volume diperbarui, kunci-kunci yang diproyeksikan akan turut diperbarui. Kubelet akan memeriksa apakah ConfigMap yang dipasang merupakan yang terbaru pada sinkronisasi berkala. Namun, ConfigMap menggunakan cache lokal berbasis ttl (time-to-live) miliknya untuk mendapatkan nilai dari ConfigMap saat ini. Hasilnya, keseluruhan penundaan dari saat ketika ConfigMap diperbarui sampai saat ketika kunci-kunci baru diproyeksikan ke pada Pod bisa selama periode sinkronisasi kubelet (secara bawaan selama 1 menit) + ttl dari cache ConfigMap (secara bawaan selama 1 menit) pada kubelet. Kamu dapat memicu pembaruan langsung dengan memperbarui salah satu dari anotasi Pod.
Catatan: Kontainer yang menggunakan ConfigMap sebagai volume subPath tidak akan menerima pembaruan ConfigMap.
Memahami ConfigMap dan Pod
Sumber daya API ConfigMap menyimpan data konfigurasi sebagai pasangan kunci-nilai. Data tersebut dapat dikonsumsi oleh Pod atau sebagai penyedia konfigurasi untuk komponen-komponen sistem seperti kontroler. ConfigMap mirip dengan Secret, tetapi ConfigMap dimaksudkan untuk mengolah tulisan yang tidak memiliki informasi yang sensitif. Baik pengguna maupun komponen sistem dapat menyimpan data konfigurasi pada ConfigMap.
Catatan: ConfigMap harus mereferensikan berkas-berkas properti, bukan menggantikannya. Anggaplah ConfigMap sebagai sesuatu yang merepresentasikan direktori /etc beserta isinya pada Linux. Sebagai contoh, jika kamu membuat sebuah Volume Kubernetes dari ConfigMap, tiap butir data pada ConfigMap direpresentasikan sebagai sebuah berkas pada volume.
Kolom data pada ConfigMap berisi data konfigurasi. Seperti pada contoh di bawah, hal ini bisa berupa sesuatu yang sederhana -- seperti properti individual yang ditentukan menggunakan --from-literal -- atau sesuatu yang kompleks -- seperti berkas konfigurasi atau blob JSON yang ditentukan dengan --from-file.
apiVersion:v1kind:ConfigMapmetadata:creationTimestamp:2016-02-18T19:14:38Zname:example-confignamespace:defaultdata:# contoh properti yang sederhana yang ditentukan menggunakan --from-literalexample.property.1:helloexample.property.2:world# contoh properti yang kompleks yang ditentukan menggunakan --from-fileexample.property.file:|- property.1=value-1
property.2=value-2
property.3=value-3
Batasan
Kamu harus membuat ConfigMap sebelum merujuknya pada spesifikasi Pod (kecuali kamu menandai ConfigMap sebagai "optional"). Jika kamu merujuk sebuah ConfigMap yang tidak ada, Pod tersebut tidak akan berjalan. Sama halnya, mereferensikan kunci yang tidak ada pada ConfigMap akan mencegah Pod untuk berjalan.
Jika kamu menggunakan envFrom untuk menentukan variabel environment dari ConfigMap, kunci-kunci yang dianggap tidak sah akan dilewat. Pod akan diizinkan untuk berjalan, tetapi nama-nama yang tidak sah akan direkam pada event log (InvalidVariableNames). Pesan log tersebut mencantumkan tiap kunci yang dilewat. Sebagai contoh:
kubectl get events
Keluaran akan tampil seperti berikut:
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames {kubelet, 127.0.0.1} Keys [1badkey, 2alsobad] from the EnvFrom configMap default/myconfig were skipped since they are considered invalid environment variable names.
ConfigMap berada pada Namespace tertentu. ConfigMap hanya dapat dirujuk oleh Pod yang berada pada Namespace yang sama.
Kamu tidak dapat menggunakan ConfigMap untuk Pod statis, karena Kubelet tidak mendukung hal ini.
3.11 - Pembagian Namespace Proses antar Container pada sebuah Pod
FEATURE STATE:Kubernetes v1.17 [stable]
Dokumen ini akan menjelaskan menkanisme konfigurasi pembagian namespace
process dalam sebuah Pod. Ketika pembagian namespace proses diaktifkan untuk sebuah Pod,
proses yang ada di dalam Container akan bersifat transparan pada semua Container
yang terdapat di dalam Pod tersebut.
Kamu dapat mengaktifkan fitur ini untuk melakukan konfigurasi kontainer yang saling terhubung,
misalnya saja kontainer sidecar yang bertugas dalam urusan log, atau untuk melakukan
proses pemecahan masalah (troubleshoot) image kontainer yang tidak memiliki utilitas debugging seperti shell.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Tempelkan kontainer shell dan jalankan perintah ps:
kubectl attach -it nginx -c shell
Jika kamu tidak melihat prompt perintah, kamu dapat menekan tombol enter:
/ # ps ax
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
14 101 0:00 nginx: worker process
15 root 0:00 sh
21 root 0:00 ps ax
Kamu dapat memberikan sinyal pada kontainer lain. Misalnya saja, mengirim sinyal SIGHUP pada
nginx untuk menjalankan ulang proses worker. Hal ini membutuhkan kapabilitas SYS_PTRACE.
/ # kill -HUP 8
/ # ps ax
PID USER TIME COMMAND
1 root 0:00 /pause
8 root 0:00 nginx: master process nginx -g daemon off;
15 root 0:00 sh
22 101 0:00 nginx: worker process
23 root 0:00 ps ax
Hal ini juga merupakan alasan mengapa kita dapat mengakses kontainer lain menggunakan
tautan (link) /proc/$pid/root.
/ # head /proc/8/root/etc/nginx/nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
Memahami Pembagian Namespace Process
Pod berbagi banyak sumber daya yang ada sehingga memungkinkan adanya pembagian namespace
proses. Beberapa image kontainer bisa jadi terisolasi dari kontainer lainnya,
meskipun begitu, memahami beberapa perbedaan berikut juga merupakan hal yang
penting untuk diketahui:
Proses kontainer tidak lagi memiliki PID 1. Beberapa image kontainer akan menolak
untuk dijalankan (contohnya, kontainer yang menggunakan systemd) atau menjalankan
perintah seperti kill -HUP 1 untuk memberikan sinyal pada proses kontainer. Di dalam Pod dengan
sebuah namespace process terbagi, sinyal kill -HUP 1 akan diberikan pada sandbox Pod.
(/pause pada contoh di atas.)
Proses-proses yang ada akan transparan pada kontainer lain di dalam Pod. Hal ini termasuk
informasi pada /proc, seperti kata sandi yang diberikan sebagai argumen atau environment variable.
Hal ini hanya dilindungi oleh perizinan reguler Unix.
Berkas sistem (filesystem) kontainer bersifat transparan pada kontainer lain di dalam Pod melalui link
/proc/$pid/root. Hal ini memungkinkan proses debugging menjadi lebih mudah, meskipun begitu hal ini
juga berarti kata kunci (secret) yang ada di dalam filesystem juga hanya dilindungi oleh perizinan filesystem saja.
3.12 - Membuat Pod Statis
Pod statis dikelola langsung oleh daemon kubelet pada suatu Node spesifik,
tanpa API server
mengobservasi mereka.
Tidak seperti Pod yang dikelola oleh control plane (contohnya,
Deployment);
kubelet akan memantau setiap Pod statis (dan menjalankan ulang jika
Pod mengalami kegagalan).
Pod statis selalu terikat pada satu Kubelet
di dalam Node spesifik.
Kubelet secara otomatis akan mengulang untuk membuat sebuah
Pod mirror
pada server API Kubernetes untuk setiap Pod statis.
Ini berarti Pod yang berjalan pada Node akan terlihat oleh API server,
namun tidak dapat mengontrol dari sana.
Catatan: Jika kamu menjalankan klaster Kubernetes dan menggunakan Pod statis
untuk menjalankan Pod pada setiap Node, kamu kemungkinan harus menggunakan
sebuah DaemonSet.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Laman ini mengasumsikan kamu menggunakan Docker
untuk menjalankan Pod, dan Node kamu berjalan menggunakan sistem operasi Fedora.
Instruksi untuk distribusi lain atau instalasi Kubernetes mungkin berbeda.
Manifes Pod statis pada berkas sistem (file system)
Manifes adalah standar definisi Pod dalam format JSON atau YAML pada suatu direktori.
Gunakan fieldstaticPodPath: <direktori> pada
berkas konfigurasi kubelet,
yang akan membaca direktori
secara berkala dan membuat atau menghapus Pod statis sesuai dengan berkas YAML/JSON
yang bertambah atau berkurang disana.
Catatan bahwa kubelet akan mengabaikan berkas yang diawali dengan titik (dot)
ketika memindai suatu direktori.
Sebagai contoh, ini cara untuk memulai server web sederhana sebagai Pod statis:
Pilih Node yang kamu pilih untuk menjalankan Pod statis. Dalam contoh ini adalah my-node1.
ssh my-node1
Pilih sebuah direktori, katakan /etc/kubelet.d dan letakkan berkas definisi Pod untuk web server disana, contohnya /etc/kubelet.d/static-web.yaml:
# Jalankan perintah ini pada Node tempat kubelet sedang berjalan
mkdir /etc/kubelet.d/
cat <<EOF >/etc/kubelet.d/static-web.yaml
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
EOF
Atur kubelet pada Node untuk menggunakan direktori ini dengan menjalankannya menggunakan argumen --pod-manifest-path=/etc/kubelet.d/. Pada Fedora, ubah berkas /etc/kubernetes/kubelet dengan menambahkan baris berikut:
Jalankan ulang kubelet. Pada Fedora, kamu dapat menjalankan:
# Jalankan perintah berikut pada Node tempat kubelet berjalan
systemctl restart kubelet
Manifes Pod statis pada Web
Berkas yang ditentukan pada argumen --manifest-url=<URL> akan diunduh oleh kubelet secara berkala
dan kubelet akan menginterpretasinya sebagai sebuah berkas JSON/YAML yang berisikan definisi Pod.
Mirip dengan cara kerja manifes pada filesystem,
kubelet akan mengambil manifes berdasarkan jadwal. Jika ada perubahan pada daftar
Pod statis, maka kubelet akan menerapkannya.
Untuk menggunakan cara ini:
Buat sebuah berkas YAML dan simpan pada suatu web server sehingga kamu pada memberikan URL tersebut pada kubelet.
Atur kubelet pada suatu Node untuk menggunakan manifes pada web ini dengan menjalankan menggunakan argumen --manifest-url=<url-manifes>. Pada Fedora, ubah pada /etc/kubernetes/kubelet untuk menambahkan baris ini:
Jalankan ulang kubelet. Pada Fedora, kamu dapat menjalankan:
# Jalankan perintah ini pada Node tempat kubelet berjalan
systemctl restart kubelet
Mengobservasi perilaku Pod statis
Ketika kubelet berjalan, secara otomatis akan menjalankan semua Pod statis yang terdefinisi.
Ketika kamu mendefinisikan Pod statis dan menjalankan ulang kubelet, Pod statis yang baru
akan dijalankan.
Kamu dapat melihat Container yang berjalan (termasuk Pod statis) dengan menjalankan (pada Node):
# Jalankan perintah ini pada Node tempat kubelet berjalan
docker ps
Keluarannya kira-kira seperti berikut:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f6d05272b57e nginx:latest "nginx" 8 minutes ago Up 8 minutes k8s_web.6f802af4_static-web-fk-node1_default_67e24ed9466ba55986d120c867395f3c_378e5f3c
Kamu dapat melihat Pod mirror tersebut pada API server:
kubectl get pods
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 2m
Catatan: Pastikan kubelet memiliki izin untuk membuat Pod mirror pada server API. Jika tidak,
pembuatannya akan ditolak oleh API server. Lihat
PodSecurityPolicy.
Label dari Pod statis
akan dibuat juga pada Pod mirror. Kamu dapat menggunakan label tersebut
seperti biasa menggunakan selector-selector,
atau yang lainnya.
Kamu dapat mencoba untuk menggunakan kubelet untuk menghapus Pod mirror tersebut pada API server,
namun kubelet tidak akan menghapus Pod statis:
kubectl delete pod static-web-my-node1
pod "static-web-my-node1" deleted
Kamu akan melihat bahwa Pod tersebut tetap berjalan:
kubectl get pods
NAME READY STATUS RESTARTS AGE
static-web-my-node1 1/1 Running 0 12s
Kembali ke Node tempat kubelet berjalan, kamu dapat mencoba menghentikan Container
Docker secara manual.
Kamu akan melihat, setelah beberapa saat, kubelet akan mengetahui dan akan menjalankan ulang Pod
secara otomatis:
# Jalankan perintah ini pada Node tempat kubelet berjalan
docker stop f6d05272b57e # ganti dengan ID pada Container-mu
sleep 20
docker ps
CONTAINER ID IMAGE COMMAND CREATED ...
5b920cbaf8b1 nginx:latest "nginx -g 'daemon of 2 seconds ago ...
Penambahan dan pengurangan secara dinamis pada Pod statis
Direktori konfigurasi (/etc/kubelet.d pada contoh kita) akan dipindai secara berkala oleh kubelet
untuk melakukan perubahan dan penambahan/pengurangan
Pod sesuai dengan penambahan/pengurangan berkas pada direktori tersebut.
# Ini mengasumsikan kamu menggunakan konfigurasi Pod statis pada _filesystem_# Jalankan perintah ini pada Node tempat kubelet berjalan#
mv /etc/kubelet.d/static-web.yaml /tmp
sleep 20
docker ps
# Kamu mendapatkan bahwa tidak ada Container nginx yang berjalan
mv /tmp/static-web.yaml /etc/kubelet.d/
sleep 20
docker ps
CONTAINER ID IMAGE COMMAND CREATED ...
e7a62e3427f1 nginx:latest "nginx -g 'daemon of 27 seconds ago
4 - Mengelola Sebuah Klaster
Pelajari tugas-tugas umum dalam pengelolaan sebuah klaster.
4.1 - Menggunakan Calico untuk NetworkPolicy
Laman ini menunjukkan beberapa cara cepat untuk membuat klaster Calico pada Kubernetes.
Sebelum kamu memulai
Putuskan apakah kamu ingin menggelar (deploy) sebuah klaster di cloud atau di lokal.
Membuat klaster Calico dengan menggunakan Google Kubernetes Engine (GKE)
4.2.1 - Mengatur Batas Minimum dan Maksimum Memori pada sebuah Namespace
Laman ini menunjukkan cara untuk mengatur nilai minimum dan maksimum memori yang digunakan oleh Container
yang berjalan pada sebuah Namespace. Kamu dapat menentukan nilai minimum dan maksimum memori pada objek
LimitRange. Jika sebuah Pod tidak memenuhi batasan yang ditentukan oleh LimitRange,
maka Pod tersebut tidak dapat dibuat pada Namespace tersebut.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
kubectl get limitrange mem-min-max-demo-lr --namespace=constraints-mem-example --output=yaml
Keluaran yang dihasilkan menunjukkan batasan minimum dan maksimum dari memori seperti yang diharapkan. Tetapi
perhatikan hal berikut, meskipun kamu tidak menentukan nilai bawaan pada berkas konfigurasi untuk
LimitRange, namun nilai tersebut akan dibuat secara otomatis.
Mulai sekarang setiap Container yang dibuat pada Namespace constraints-mem-example, Kubernetes
akan menjalankan langkah-langkah berikut:
Jika Container tersebut tidak menentukan permintaan dan limit memori, maka diberikan nilai permintaan
dan limit memori bawaan pada Container.
Memastikan Container memiliki permintaan memori yang lebih besar atau sama dengan 500 MiB.
Memastikan Container memiliki limit memori yang lebih kecil atau kurang dari 1 GiB.
Berikut berkas konfigurasi Pod yang memiliki satu Container. Manifes Container
menentukan permintaan memori 600 MiB dan limit memori 800 MiB. Nilai tersebut memenuhi
batasan minimum dan maksimum memori yang ditentukan oleh LimitRange.
kubectl get pod constraints-mem-demo --namespace=constraints-mem-example
Melihat informasi mendetail tentang Pod:
kubectl get pod constraints-mem-demo --output=yaml --namespace=constraints-mem-example
Keluaran yang dihasilkan menunjukkan Container memiliki permintaan memori 600 MiB dan limit memori
800 MiB. Nilai tersebut memenuhi batasan yang ditentukan oleh LimitRange.
kubectl delete pod constraints-mem-demo --namespace=constraints-mem-example
Mencoba membuat Pod yang melebihi batasan maksimum memori
Berikut berkas konfigurasi untuk sebuah Pod yang memiliki satu Container. Container tersebut menentukan
permintaan memori 800 MiB dan batas memori 1.5 GiB.
Keluaran yang dihasilkan menunjukkan Pod tidak dibuat, karena Container menentukan limit memori yang
terlalu besar:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-2.yaml":
pods "constraints-mem-demo-2" is forbidden: maximum memory usage per Container is 1Gi, but limit is 1536Mi.
Mencoba membuat Pod yang tidak memenuhi permintaan memori
Berikut berkas konfigurasi untuk sebuah Pod yang memiliki satu Container. Container tersebut menentukan
permintaan memori 100 MiB dan limit memori 800 MiB.
Keluaran yang dihasilkan menunjukkan Pod tidak dibuat, karena Container menentukan permintaan memori yang
terlalu kecil:
Error from server (Forbidden): error when creating "examples/admin/resource/memory-constraints-pod-3.yaml":
pods "constraints-mem-demo-3" is forbidden: minimum memory usage per Container is 500Mi, but request is 100Mi.
Membuat Pod yang tidak menentukan permintaan ataupun limit memori
Berikut berkas konfigurasi untuk sebuah Pod yang memiliki satu Container. Container tersebut tidak menentukan
permintaan memori dan juga limit memori.
kubectl get pod constraints-mem-demo-4 --namespace=constraints-mem-example --output=yaml
Keluaran yang dihasilkan menunjukkan Container pada Pod memiliki permintaan memori 1 GiB dan limit memori 1 GiB.
Bagaimana Container mendapatkan nilai tersebut?
Karena Containermu tidak menentukan permintaan dan limit memori, Container tersebut diberikan
permintaan dan limit memori bawaan
dari LimitRange.
Pada tahap ini, Containermu mungkin saja berjalan ataupun mungkin juga tidak berjalan. Ingat bahwa prasyarat
untuk tugas ini adalah Node harus memiliki setidaknya 1 GiB memori. Jika tiap Node hanya memiliki
1 GiB memori, maka tidak akan ada cukup memori untuk dialokasikan pada setiap Node untuk memenuhi permintaan 1 Gib memori. Jika ternyata kamu menggunakan Node dengan 2 GiB memori, maka kamu mungkin memiliki cukup ruang untuk memenuhi permintaan 1 GiB tersebut.
Menghapus Pod:
kubectl delete pod constraints-mem-demo-4 --namespace=constraints-mem-example
Pelaksanaan batasan minimum dan maksimum memori
Batasan maksimum dan minimum memori yang yang ditetapkan pada sebuah Namespace oleh LimitRange dilaksanakan
hanya ketika Pod dibuat atau diperbarui. Jika kamu mengubah LimitRange, hal tersebut tidak akan memengaruhi
Pods yang telah dibuat sebelumnya.
Motivasi untuk batasan minimum dan maksimum memori
Sebagai seorang administrator klaster, kamu mungkin ingin menetapkan pembatasan jumlah memori yang dapat digunakan oleh Pod.
Sebagai contoh:
Tiap Node dalam sebuah klaster memiliki 2 GB memori. Kamu tidak ingin menerima Pod yang meminta
lebih dari 2 GB memori, karena tidak ada Node pada klater yang dapat memenuhi permintaan tersebut.
Sebuah klaster digunakan bersama pada departemen produksi dan pengembangan.
Kamu ingin mengizinkan beban kerja (workload) pada produksi untuk menggunakan hingga 8 GB memori, tapi
kamu ingin beban kerja pada pengembangan cukup terbatas sampai dengan 512 MB saja. Kamu membuat Namespace terpisah
untuk produksi dan pengembangan, dan kamu menerapkan batasan memori pada tiap Namespace.
Laman ini menyediakan beberapa petunjuk untuk mendiagnosis masalah DNS.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
NAME READY STATUS RESTARTS AGE
dnsutils 1/1 Running 0 <some-time>
Setelah Pod tersebut berjalan, kamu dapat menjalankan perintah nslookup di lingkungan tersebut.
Jika kamu melihat hal seperti ini, maka DNS sudah berjalan dengan benar.
Verifikasi path pencarian dan nama server telah dibuat agar tampil seperti di bawah ini (perlu diperhatikan bahwa path pencarian dapat berbeda tergantung dari penyedia layanan cloud):
Gunakan perintah kubectl get pods untuk memverifikasi apakah Pod DNS sedang berjalan.
kubectl get pods --namespace=kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
...
coredns-7b96bf9f76-5hsxb 1/1 Running 0 1h
coredns-7b96bf9f76-mvmmt 1/1 Running 0 1h
...
Catatan: Nilai dari label k8s-app adalah kube-dns baik untuk CoreDNS maupun kube-dns.
Jika kamu melihat tidak ada Pod CoreDNS yang sedang berjalan atau Pod tersebut gagal/telah selesai, add-on DNS mungkin tidak dijalankan (deployed) secara bawaan di lingkunganmu saat ini dan kamu harus menjalankannya secara manual.
Periksa kesalahan pada Pod DNS
Gunakan perintah kubectl logs untuk melihat log dari Container DNS.
Periksa jika ada pesan mencurigakan atau tidak terduga dalam log.
Apakah layanan DNS berjalan?
Verifikasi apakah layanan DNS berjalan dengan menggunakan perintah kubectl get service.
kubectl get svc --namespace=kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
...
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 1h
...
Catatan: Nama layanan adalah kube-dns baik untuk CoreDNS maupun kube-dns.
Jika kamu telah membuat Service atau seharusnya Service telah dibuat secara bawaan namun ternyata tidak muncul, lihat
debugging Service untuk informasi lebih lanjut.
Apakah endpoint DNS telah ekspos?
Kamu dapat memverifikasikan apakah endpoint DNS telah diekspos dengan menggunakan perintah kubectl get endpoints.
kubectl get endpoints kube-dns --namespace=kube-system
NAME ENDPOINTS AGE
kube-dns 10.180.3.17:53,10.180.3.17:53 1h
Jika kamu tidak melihat endpoint, lihat bagian endpoint pada dokumentasi
debugging Service.
Untuk tambahan contoh Kubernetes DNS, lihat
contoh cluster-dns pada repositori Kubernetes GitHub.
Apakah kueri DNS diterima/diproses?
Kamu dapat memverifikasi apakah kueri telah diterima oleh CoreDNS dengan menambahkan plugin log pada konfigurasi CoreDNS (alias Corefile).
CoreDNS Corefile disimpan pada ConfigMap dengan nama coredns. Untuk mengeditnya, gunakan perintah:
kubectl -n kube-system edit configmap coredns
Lalu tambahkan log pada bagian Corefile seperti contoh berikut:
Setelah perubahan disimpan, perubahan dapat memakan waktu satu hingga dua menit untuk Kubernetes menyebarkan perubahan ini pada Pod CoreDNS.
Berikutnya, coba buat beberapa kueri dan lihat log pada bagian atas dari dokumen ini. Jika pod CoreDNS menerima kueri, kamu seharusnya akan melihatnya pada log.
Berikut ini contoh kueri yang terdapat di dalam log:
Beberapa distribusi Linux (contoh Ubuntu) menggunakan resolver DNS lokal secara bawaan (systemd-resolved).
Systemd-resolved memindahkan dan mengganti /etc/resolv.conf dengan berkas stub yang dapat menyebabkan forwarding loop yang fatal saat meresolusi nama pada server upstream. Ini dapat diatasi secara manual dengan menggunakan flag kubelet --resolv-conf
untuk mengarahkan ke resolv.conf yang benar (Pada systemd-resolved, ini berada di /run/systemd/resolve/resolv.conf).
kubeadm akan otomatis mendeteksi systemd-resolved, dan menyesuaikan flag kubelet sebagai mana mestinya.
Pemasangan Kubernetes tidak menggunakan berkas resolv.conf pada node untuk digunakan sebagai klaster DNS secara default, karena proses ini umumnya spesifik pada distribusi tertentu. Hal ini bisa jadi akan diimplementasi nantinya.
Libc Linux (alias glibc) secara bawaan memiliki batasan nameserver DNS sebanyak 3 rekaman (records). Selain itu, pada glibc versi yang lebih lama dari glibc-2.17-222 (versi terbaru lihat isu ini), jumlah rekaman DNS search dibatasi sejumlah 6 (lihat masalah sejak 2005 ini). Kubernetes membutuhkan 1 rekaman nameserver dan 3 rekaman search. Ini berarti jika instalasi lokal telah menggunakan 3 nameserver atau menggunakan lebih dari 3 search,sementara versi glibc kamu termasuk yang terkena dampak, beberapa dari pengaturan tersebut akan hilang. Untuk menyiasati batasan rekaman DNS nameserver, node dapat menjalankan dnsmasq,yang akan menyediakan nameserver lebih banyak. Kamu juga dapat menggunakan kubelet --resolv-confflag. Untuk menyiasati batasan rekaman search, pertimbangkan untuk memperbarui distribusi linux kamu atau memperbarui glibc ke versi yang tidak terdampak.
Jika kamu menggunakan Alpine versi 3.3 atau lebih lama sebagai dasar image kamu, DNS mungkin tidak dapat bekerja dengan benar disebabkan masalah dengan Alpine.
Masalah 30215 Kubernetes menyediakan informasi lebih detil tentang ini.
Laman ini menjelaskan cara mengonfigurasi DNS
Pod kamu dan menyesuaikan
proses resolusi DNS pada klaster kamu.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Klaster kamu harus menjalankan tambahan (add-on) CoreDNS terlebih dahulu.
Migrasi ke CoreDNS
menjelaskan tentang bagaimana menggunakan kubeadm untuk melakukan migrasi dari kube-dns.
Kubernetes servermu harus dalam versi yang sama atau lebih baru dari v1.12.
Untuk melihat versi, tekan kubectl version.
Pengenalan
DNS adalah Service bawaan dalam Kubernetes yang diluncurkan secara otomatis
melalui addon manageradd-on klaster.
Sejak Kubernetes v1.12, CoreDNS adalah server DNS yang direkomendasikan untuk menggantikan kube-dns. Jika klaster kamu
sebelumnya menggunakan kube-dns, maka kamu mungkin masih menggunakan kube-dns daripada CoreDNS.
Catatan: Baik Service CoreDNS dan kube-dns diberi nama kube-dns pada fieldmetadata.name.
Hal ini agar ada interoperabilitas yang lebih besar dengan beban kerja yang bergantung pada nama Service kube-dns lama untuk me-resolve alamat internal ke dalam klaster. Dengan menggunakan sebuah Service yang bernama kube-dns mengabstraksi detail implementasi yang dijalankan oleh penyedia DNS di belakang nama umum tersebut.
Jika kamu menjalankan CoreDNS sebagai sebuah Deployment, maka biasanya akan ditampilkan sebagai sebuah Service Kubernetes dengan alamat IP yang statis.
Kubelet meneruskan informasi DNS resolver ke setiap Container dengan argumen --cluster-dns=<dns-service-ip>.
Nama DNS juga membutuhkan domain. Kamu dapat mengonfigurasi domain lokal di kubelet
dengan argumen --cluster-domain=<default-local-domain>.
Server DNS mendukung forward lookup (record A dan AAAA), port lookup (record SRV), reverse lookup alamat IP (record PTR),
dan lain sebagainya. Untuk informasi lebih lanjut, lihatlah DNS untuk Service dan Pod.
Jika dnsPolicy dari Pod diatur menjadi default, itu berarti mewarisi konfigurasi resolusi nama
dari Node yang dijalankan Pod. Resolusi DNS pada Pod
harus berperilaku sama dengan Node tersebut.
Tapi lihat Isu-isu yang telah diketahui.
Jika kamu tidak menginginkan hal ini, atau jika kamu menginginkan konfigurasi DNS untuk Pod berbeda, kamu bisa
menggunakan argumen --resolv-conf pada kubelet. Atur argumen ini menjadi "" untuk mencegah Pod tidak
mewarisi konfigurasi DNS. Atur ke jalur (path) berkas yang tepat untuk berkas yang berbeda dengan
/etc/resolv.conf untuk menghindari mewarisi konfigurasi DNS.
CoreDNS
CoreDNS adalah server DNS otoritatif untuk kegunaan secara umum yang dapat berfungsi sebagai Service DNS untuk klaster, yang sesuai dengan spesifikasi dns.
Opsi ConfigMap pada CoreDNS
CoreDNS adalah server DNS yang modular dan mudah dipasang, dan setiap plugin dapat menambahkan fungsionalitas baru ke CoreDNS.
Fitur ini dapat dikonfigurasikan dengan menjaga berkas Corefile, yang merupakan
berkas konfigurasi dari CoreDNS. Sebagai administrator klaster, kamu dapat memodifikasi
ConfigMap untuk Corefile dari CoreDNS dengan mengubah cara perilaku pencarian Service DNS
pada klaster tersebut.
Di Kubernetes, CoreDNS diinstal dengan menggunakan konfigurasi Corefile bawaan sebagai berikut:
Konfigurasi Corefile meliputi plugin berikut ini dari CoreDNS:
errors: Kesalahan yang ditampilkan ke output standar (stdout)
health: Kesehatan dari CoreDNS dilaporkan pada http://localhost:8080/health. Dalam sintaks yang diperluas lameduck akan menangani proses tidak sehat agar menunggu selama 5 detik sebelum proses tersebut dimatikan.
ready: Endpoint HTTP pada port 8181 akan mengembalikan OK 200, ketika semua plugin yang dapat memberi sinyal kesiapan, telah memberikan sinyalnya.
kubernetes: CoreDNS akan menjawab pertanyaan (query) DNS berdasarkan IP Service dan Pod pada Kubernetes. Kamu dapat menemukan lebih detail tentang plugin itu dalam situs web CoreDNS. ttl memungkinkan kamu untuk mengatur TTL khusus untuk respon dari pertanyaan DNS. Standarnya adalah 5 detik. TTL minimum yang diizinkan adalah 0 detik, dan maksimum hanya dibatasi sampai 3600 detik. Mengatur TTL ke 0 akan mencegah record untuk di simpan sementara dalam cache.
Opsi pods insecure disediakan untuk kompatibilitas dengan Service kube-dns sebelumnya. Kamu dapat menggunakan opsi pods verified, yang mengembalikan record A hanya jika ada Pod pada Namespace yang sama untuk alamat IP yang sesuai. Opsi pods disabled dapat digunakan jika kamu tidak menggunakan record Pod.
prometheus: Metrik dari CoreDNS tersedia pada http://localhost:9153/metrics dalam format yang sesuai dengan Prometheus (dikenal juga sebagai OpenMetrics).
forward: Setiap pertanyaan yang tidak berada dalam domain klaster Kubernetes akan diteruskan ke resolver yang telah ditentukan dalam berkas (/etc/resolv.conf).
loop: Mendeteksi forwarding loop sederhana dan menghentikan proses CoreDNS jika loop ditemukan.
reload: Mengizinkan reload otomatis Corefile yang telah diubah. Setelah kamu mengubah konfigurasi ConfigMap, beri waktu sekitar dua menit agar perubahan yang kamu lakukan berlaku.
loadbalance: Ini adalah load balancer DNS secara round-robin yang mengacak urutan record A, AAAA, dan MX dalam setiap responnya.
Kamu dapat memodifikasi perilaku CoreDNS bawaan dengan memodifikasi ConfigMap.
Konfigurasi Stub-domain dan Nameserver Upstream dengan menggunakan CoreDNS
CoreDNS memiliki kemampuan untuk mengonfigurasi stubdomain dan nameserver upstream dengan menggunakan plugin forward.
Contoh
Jika operator klaster memiliki sebuah server domain Consul yang terletak di 10.150.0.1, dan semua nama Consul memiliki akhiran .consul.local. Untuk mengonfigurasinya di CoreDNS, administrator klaster membuat bait (stanza) berikut dalam ConfigMap CoreDNS.
Untuk memaksa secara eksplisit semua pencarian DNS non-cluster melalui nameserver khusus pada 172.16.0.1, arahkan forward ke nameserver bukan ke /etc/resolv.conf
forward . 172.16.0.1
ConfigMap terakhir bersama dengan konfigurasi Corefile bawaan terlihat seperti berikut:
Perangkat kubeadm mendukung terjemahan otomatis dari ConfigMap kube-dns
ke ConfigMap CoreDNS yang setara.
Catatan: Sementara ini kube-dns dapat menerima FQDN untuk stubdomain dan nameserver (mis: ns.foo.com), namun CoreDNS belum mendukung fitur ini.
Selama penerjemahan, semua nameserver FQDN akan dihilangkan dari konfigurasi CoreDNS.
Konfigurasi CoreDNS yang setara dengan kube-dns
CoreDNS mendukung fitur kube-dns dan banyak lagi lainnya.
ConfigMap dibuat agar kube-dns mendukung StubDomains dan upstreamNameservers untuk diterjemahkan ke pluginforward dalam CoreDNS.
Begitu pula dengan pluginFederations dalam kube-dns melakukan translasi untuk pluginfederation dalam CoreDNS.
Contoh
Contoh ConfigMap ini untuk kube-dns menentukan federasi, stub domain dan server upstream nameserver:
Untuk bermigrasi dari kube-dns ke CoreDNS,
artikel blog yang detail
tersedia untuk membantu pengguna mengadaptasi CoreDNS sebagai pengganti dari kube-dns.
Kamu juga dapat bermigrasi dengan menggunakan
skrip deploy CoreDNS yang resmi.
4.5 - Melakukan Reservasi Sumber Daya Komputasi untuk Daemon Sistem
Node Kubernetes dapat dijadwalkan sesuai dengan kapasitas. Secara bawaan, Pod dapat menggunakan
semua kapasitas yang tersedia pada sebuah Node. Ini merupakan masalah karena Node
sebenarnya menjalankan beberapa daemon sistem yang diperlukan oleh OS dan Kubernetes itu sendiri.
Jika sumber daya pada Node tidak direservasi untuk daemon-daemon tersebut, maka
Pod dan daemon akan berlomba-lomba menggunakan sumber daya yang tersedia, sehingga
menyebabkan starvation sumber daya pada Node.
Fitur bernama Allocatable pada Node diekspos oleh kubelet yang berfungsi untuk melakukan
reservasi sumber daya komputasi untuk daemon sistem. Kubernetes merekomendasikan admin
klaster untuk mengatur Allocatable pada Node berdasarkan tingkat kepadatan (density) beban kerja setiap Node.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Kubernetes servermu harus dalam versi yang sama atau lebih baru dari 1.8.
Untuk melihat versi, tekan kubectl version.
Kamu harus menjalankan Kubernetes server dengan versi 1.17 atau yang lebih baru
untuk menggunakan perintah baris kubelet dengan opsi --reserved-cpus untuk
menyetel daftar reservasi CPU secara eksplisit.
Allocatable atau sumber daya yang dialokasikan pada sebuah Node Kubernetes merupakan
jumlah sumber daya komputasi yang dapat digunakan oleh Pod. Penjadwal tidak
dapat melakukan penjadwalan melebihi Allocatable. Saat ini dukungan terhadap
CPU, memory dan ephemeral-storage tersedia.
Allocatable pada Node diekspos oleh objek API v1.Node dan merupakan
bagian dari baris perintah kubectl describe node.
Sumber daya dapat direservasi untuk dua kategori daemon sistem melalui kubelet.
Mengaktifkan QoS dan tingkatan cgroup dari Pod
Untuk menerapkan batasan Allocatable pada Node, kamu harus mengaktifkan
hierarki cgroup yang baru melalui flag--cgroups-per-qos. Secara bawaan, flag ini
telah aktif. Saat aktif, kubelet akan memasukkan semua Pod pengguna di bawah
sebuah hierarki cgroup yang dikelola oleh kubelet.
Mengonfigurasi driver cgroup
Manipulasi terhadap hierarki cgroup pada hos melalui driver cgroup didukung oleh kubelet.
Driver dikonfigurasi melalui flag--cgroup-driver.
Nilai yang didukung adalah sebagai berikut:
cgroupfs merupakan driver bawaan yang melakukan manipulasi secara langsung
terhadap filesystem cgroup pada hos untuk mengelola sandbox cgroup.
systemd merupakan driver alternatif yang mengelola sandbox cgroup menggunakan
bagian dari sumber daya yang didukung oleh sistem init yang digunakan.
Tergantung dari konfigurasi runtime Container yang digunakan,
operator dapat memilih driver cgroup tertentu untuk memastikan perilaku sistem yang tepat.
Misalnya, jika operator menggunakan driver cgroup systemd yang disediakan oleh
runtime docker, maka kubelet harus diatur untuk menggunakan driver cgroup systemd.
Kube Reserved
Flag Kubelet: --kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000]
Flag Kubelet: --kube-reserved-cgroup=
kube-reserved berfungsi untuk mengambil informasi sumber daya reservasi
untuk daemon sistem Kubernetes, seperti kubelet, runtime Container, detektor masalah pada Node, dsb.
kube-reserved tidak berfungsi untuk mereservasi sumber daya untuk daemon sistem yang berjalan
sebagai Pod. kube-reserved merupakan fungsi dari kepadatan Pod pada Node.
Selain dari cpu, memory, dan ephemeral-storage,pid juga dapat
diatur untuk mereservasi jumlah ID proses untuk daemon sistem Kubernetes.
Secara opsional, kamu dapat memaksa daemon sistem melalui setelan kube-reserved.
Ini dilakukan dengan menspesifikasikan parent cgroup sebagai nilai dari flag--kube-reserved-cgroup pada kubelet.
Kami merekomendasikan daemon sistem Kubernetes untuk ditempatkan pada
tingkatan cgroup yang tertinggi (contohnya, runtime.slice pada mesin systemd).
Secara ideal, setiap daemon sistem sebaiknya dijalankan pada child cgroup
di bawah parent ini. Lihat dokumentasi
untuk mengetahui rekomendasi hierarki cgroup secara detail.
Catatan: kubelet tidak membuat--kube-reserved-cgroup jika cgroup
yang diberikan tidak ada pada sistem. Jika cgroup yang tidak valid diberikan,
maka kubelet akan mengalami kegagalan.
System Reserved
Flag Kubelet: --system-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi][,][pid=1000]
Flag Kubelet: --system-reserved-cgroup=
system-reserved berfungsi untuk mengetahui reservasi sumber daya untuk
daemon sistem pada OS, seperti sshd, udev, dan lainnya. system-reserved sebaiknya
mereservasi memori untuk kernel juga, karena memori kernel tidak termasuk dalam
hitungan kalkulasi Pod pada Kubernetes. Kami juga merekomendasikan reservasi sumber daya
untuk sesi (session) login pengguna (contohnya, user.slice di dalam dunia systemd).
Melakukan Reservasi Daftar CPU secara Eksplisit
FEATURE STATE:Kubernetes v1.17 [stable]
Flag Kubelet: --reserved-cpus=0-3
reserved-cpus berfungsi untuk mendefinisikan cpuset secara eksplisit untuk
daemon sistem OS dan daemon sistem Kubernetes. reserved-cpus dimaksudkan untuk
sistem-sistem yang tidak mendefinisikan tingkatan cgroup tertinggi secara terpisah untuk
daemon sistem OS dan daemon sistem Kubernetes yang berkaitan dengan sumber daya cpuset.
Jika kubelet tidak memiliki--system-reserved-cgroup dan --kube-reserved-cgroup,
cpuset akan diberikan secara eksplisit oleh reserved-cpus, yang akan menimpa definisi
yang diberikan oleh opsi --kube-reserved dan --system-reserved.
Opsi ini dirancang secara spesifik untuk kasus-kasus Telco/NFV, di mana interrupt atau timer
yang tidak terkontrol bisa memengaruhi performa dari beban kerja. Kamu dapat menggunakan
opsi untuk untuk mendefinisikan cpuset secara eksplisit untuk daemon sistem/Kubernetes dan
interrupt/timer, sehingga CPU sisanya dalam sistem akan digunakan untuk beban kerja saja,
dengan dampak yang sedikit terhadap interrupt/timer yang tidak terkontrol. Untuk
memindahkan daemon sistem, daemon Kubernetes serta interrrupt/timer Kubernetes supaya
menggunakan cpuset yang eksplisit didefinisikan oleh opsi ini, sebaiknya digunakan mekanisme lain di luar Kubernetes. Contohnya: pada Centos, kamu dapat melakukan ini dengan menggunakan
toolset yang sudah disetel.
Batas Pengusiran (Eviction Threshold)
Flag Kubelet: --eviction-hard=[memory.available<500Mi]
Tekanan memori pada tingkatan Node menyebabkan sistem OOM (Out Of Memory) yang
berdampak pada Node secara keseluruhan dan semua Pod yang dijalankan di dalamnya.
Node dapat berubah menjadi offline sementara sampai memori berhasil diklaim kembali.
Untuk menghindari sistem OOM, atau mengurangi kemungkinan terjadinya OOM, kubelet
menyediakan fungsi untuk pengelolaan saat Kehabisan Sumber Daya (Out of Resource).
Pengusiran dapat dilakukan hanya untuk kasus kehabisan memory dan ephemeral-storage. Dengan mereservasi
sebagian memori melalui flag--eviction-hard, kubelet akan berusaha untuk "mengusir" (evict)
Pod ketika ketersediaan memori pada Node jatuh di bawah nilai yang telah direservasi.
Dalam bahasa sederhana, jika daemon sistem tidak ada pada Node, maka Pod tidak dapat menggunakan
memori melebihi nilai yang ditentukan oleh flag--eviction-hard. Karena alasan ini,
sumber daya yang direservasi untuk pengusiran tidak tersedia untuk Pod.
Memaksakan Allocatable pada Node
Flag Kubelet: --enforce-node-allocatable=pods[,][system-reserved][,][kube-reserved]
Penjadwal menganggap Allocatable sebagai kapasitas yang tersedia untuk digunakan oleh Pod.
Secara bawaan, kubelet memaksakan Allocatable untuk semua Pod. Pemaksaan dilakukan
dengan cara "mengusir" Pod-Pod ketika penggunaan sumber daya Pod secara keseluruhan telah
melewati nilai Allocatable. Lihat bagian ini
untuk mengetahui kebijakan pengusiran secara detail. Pemaksaan ini dikendalikan dengan
cara memberikan nilai Pod melalui flag--enforce-node-allocatable pada kubelet.
Secara opsional, kubelet dapat diatur untuk memaksakan kube-reserved dan
system-reserved dengan memberikan nilai melalui flag tersebut. Sebagai catatan,
jika kamu mengatur kube-reserved, maka kamu juga harus mengatur --kube-reserved-cgroup. Begitu pula
jika kamu mengatur system-reserved, maka kamu juga harus mengatur --system-reserved-cgroup.
Panduan Umum
Daemon sistem dilayani mirip seperti Pod Guaranteed yang terjamin sumber dayanya.
Daemon sistem dapat melakukan burst di dalam jangkauan cgroup. Perilaku ini
dikelola sebagai bagian dari penggelaran (deployment) Kubernetes. Sebagai contoh,
kubelet harus memiliki cgroup sendiri dan membagikan sumber daya kube-reserved dengan
runtime Container. Namun begitu, kubelet tidak dapat melakukan burst dan menggunakan
semua sumber daya yang tersedia pada Node jika kube-reserved telah dipaksakan pada sistem.
Kamu harus berhati-hati ekstra ketika memaksakan reservasi system-reserved karena dapat
menyebabkan layanan sistem yang terpenting mengalami CPU starvation, OOM killed, atau tidak
dapat melakukan fork pada Node. Kami menyarankan untuk memaksakan system-reserved hanya
jika pengguna telah melakukan profiling sebaik mungkin pada Node mereka untuk
mendapatkan estimasi yang akurat dan percaya diri terhadap kemampuan mereka untuk
memulihkan sistem ketika ada grup yang terkena OOM killed.
Untuk memulai, paksakan Allocatable pada Pod.
Ketika monitoring dan alerting telah cukup dilakukan untuk memonitor daemon
dari sistem Kubernetes, usahakan untuk memaksakan kube-reserved berdasarkan penggunakan heuristik.
Jika benar-benar diperlukan, paksakan system-reserved secara bertahap.
Sumber daya yang diperlukan oleh daemon sistem Kubernetes dapat tumbuh seiring waktu dengan
adanya penambahan fitur-fitur baru. Proyek Kubernetes akan berusaha untuk menurunkan penggunaan sumber daya
dari daemon sistem Node, tetapi belum menjadi prioritas untuk saat ini.
Kamu dapat berekspektasi bahwa fitur kapasitas Allocatable ini akan dihapus pada versi yang akan datang.
Contoh Skenario
Berikut ini merupakan contoh yang menggambarkan komputasi Allocatable pada Node:
Node memiliki 16 CPU, memori sebesar 32Gi, dan penyimpanan sebesar 100Gi.
--kube-reserved diatur menjadi cpu=1,memory=2Gi,ephemeral-storage=1Gi
--system-reserved diatur menjadi cpu=500m,memory=1Gi,ephemeral-storage=1Gi
--eviction-hard diatur menjadi memory.available<500Mi,nodefs.available<10%
Dalam skenario ini, Allocatable akan menjadi 14.5 CPU, memori 28.5Gi, dan penyimpanan
lokal 88Gi.
Penjadwal memastikan bahwa semua Pod yang berjalan pada Node ini secara total tidak meminta memori melebihi
28.5Gi dan tidak menggunakan penyimpanan lokal melebihi 88Gi.
Pengusiran Pod akan dilakukan kubelet ketika penggunaan memori keseluruhan oleh Pod telah melebihi 28.5Gi,
atau jika penggunaan penyimpanan keseluruhan telah melebihi 88Gi. Jika semua proses pada Node mengonsumsi
CPU sebanyak-banyaknya, Pod-Pod tidak dapat mengonsumsi lebih dari 14.5 CPU.
Jika kube-reserved dan/atau system-reserved tidak dipaksakan dan daemon sistem
melebihi reservasi mereka, maka kubelet akan mengusir Pod ketika penggunaan memori pada Node
melebihi 31.5Gi atau penggunaan penyimpanan melebihi 90Gi.
4.6 - Membagi sebuah Klaster dengan Namespace
Laman ini menunjukkan bagaimana cara melihat, menggunakan dan menghapus namespaces. Laman ini juga menunjukkan bagaimana cara menggunakan Namespace Kubernetes namespaces untuk membagi klaster kamu.
Untuk melihat Namespace yang ada saat ini pada sebuah klaster anda bisa menggunakan:
kubectl get namespaces
NAME STATUS AGE
default Active 11d
kube-system Active 11d
kube-public Active 11d
Kubernetes mulai dengan tiga Namespace pertama:
default Namespace bawaan untuk objek-objek yang belum terkait dengan Namespace lain
kube-system Namespace untuk objek-objek yang dibuat oleh sistem Kubernetes
kube-public Namespace ini dibuat secara otomatis dan dapat dibaca oleh seluruh pengguna (termasuk yang tidak terotentikasi). Namespace ini sering dicadangkan untuk kepentingan klaster, untuk kasus dimana beberapa sumber daya seharusnya dapat terlihat dan dapat terlihat secara publik di seluruh klaster. Aspek publik pada Namespace ini hanya sebuah konvensi bukan suatu kebutuhan.
Kamu bisa mendapat ringkasan Namespace tertentu dengan menggunakan:
kubectl get namespaces <name>
Atau kamu bisa mendapatkan informasi detail menggunakan:
kubectl describe namespaces <name>
Name: default
Labels: <none>
Annotations: <none>
Status: Active
No resource quota.
Resource Limits
Type Resource Min Max Default
---- -------- --- --- ---
Container cpu - - 100m
Sebagai catatan, detail diatas menunjukkan baik kuota sumber daya (jika ada) dan juga jangkauan batas sumber daya.
Kuota sumber daya melacak penggunaan total sumber daya didalam Namespace dan mengijinkan operator-operator klaster mendefinisikan batas atas penggunaan sumber daya yang dapat di gunakan sebuah Namespace.
Jangkauan batas mendefinisikan pertimbangan min/maks jumlah sumber daya yang dapat di gunakan oleh sebuah entitas dalam sebuah Namespace.
Nama Namespace kamu harus merupakan
Label DNS yang valid.
Ada kolom opsional finalizers, yang memungkinkan observables untuk membersihkan sumber daya ketika Namespace dihapus. Ingat bahwa jika kamu memberikan finalizer yang tidak ada, Namespace akan dibuat tapi akan berhenti pada status Terminating jika pengguna mencoba untuk menghapusnya.
Informasi lebih lanjut mengenai finalizers bisa dibaca pada dokumentasi desain dari Namespace.
Peringatan: Ini akan menghapus semua hal yang ada dalam Namespace!
Proses penghapusan ini asinkron, jadi untuk beberapa waktu kamu akan melihat Namespace dalam status Terminating.
Membagi klaster kamu menggunakan Namespace Kubernetes
Pahami Namespace bawaan
Secara bawaan, sebuah klaster Kubernetes akan membuat Namespace bawaan ketika menyediakan klaster untuk menampung Pod, Service, dan Deployment yang digunakan oleh klaster.
Dengan asumsi kamu memiliki klaster baru, kamu bisa mengecek Namespace yang tersedia dengan melakukan hal berikut:
kubectl get namespaces
NAME STATUS AGE
default Active 13m
Membuat Namespace baru
Untuk latihan ini, kita akan membuat dua Namespace Kubernetes tambahan untuk menyimpan konten kita
Dalam sebuah skenario dimana sebuah organisasi menggunakan klaster Kubernetes yang digunakan bersama untuk penggunaan pengembangan dan produksi:
Tim pengembang ingin mengelola ruang di dalam klaster dimana mereka bisa melihat daftar Pod, Service, dan Deployment yang digunakan untuk membangun dan menjalankan apliksi mereka. Di ruang ini sumber daya akan datang dan pergi, dan pembatasan yang tidak ketat mengenai siapa yang bisa atau tidak bisa memodifikasi sumber daya untuk mendukung pengembangan secara gesit (agile).
Tim operasi ingin mengelola ruang didalam klaster dimana mereka bisa memaksakan prosedur ketat mengenai siapa yang bisa atau tidak bisa melakukan manipulasi pada kumpulan Pod, Layanan, dan Deployment yang berjalan pada situs produksi.
Satu pola yang bisa diikuti organisasi ini adalah dengan membagi klaster Kubernetes menjadi dua Namespace: development dan production
Mari kita buat dua Namespace untuk menyimpan hasil kerja kita.
Kita baru aja membuat sebuah Deployment yang memiliki ukuran replika dua yang menjalankan Pod dengan nama snowflake dengan sebuah Container dasar yang hanya melayani hostname.
kubectl get deployment -n=development
NAME READY UP-TO-DATE AVAILABLE AGE
snowflake 2/2 2 2 2m
kubectl get pods -l app=snowflake -n=development
NAME READY STATUS RESTARTS AGE
snowflake-3968820950-9dgr8 1/1 Running 0 2m
snowflake-3968820950-vgc4n 1/1 Running 0 2m
Dan ini merupakan sesuatu yang bagus, dimana pengembang bisa melakukan hal yang ingin mereka lakukan tanpa harus khawatir hal itu akan mempengaruhi konten pada namespace production.
Mari kita pindah ke Namespace production dan menujukkan bagaimana sumber daya di satu Namespace disembunyikan dari yang lain
Namespace production seharusnya kosong, dan perintah berikut ini seharusnya tidak menghasilkan apapun.
kubectl get deployment -n=production
kubectl get pods -n=production
Production Namespace ingin menjalankan cattle, mari kita buat beberapa Pod cattle.
NAME READY UP-TO-DATE AVAILABLE AGE
cattle 5/5 5 5 10s
kubectl get pods -l app=cattle -n=production
NAME READY STATUS RESTARTS AGE
cattle-2263376956-41xy6 1/1 Running 0 34s
cattle-2263376956-kw466 1/1 Running 0 34s
cattle-2263376956-n4v97 1/1 Running 0 34s
cattle-2263376956-p5p3i 1/1 Running 0 34s
cattle-2263376956-sxpth 1/1 Running 0 34s
Sampai sini, seharusnya sudah jelas bahwa sumber daya yang dibuat pengguna pada sebuah Namespace disembunyikan dari Namespace lainnya.
Seiring dengan evolusi dukungan kebijakan di Kubernetes, kami akan memperluas skenario ini untuk menunjukkan bagaimana kamu bisa menyediakan aturan otorisasi yang berbeda untuk tiap Namespace.
Memahami motivasi penggunaan Namespace
Sebuah klaster tunggal umumnya bisa memenuhi kebutuhan pengguna yang berbeda atau kelompok pengguna (itulah sebabnya disebut 'komunitas pengguna').
Namespace Kubernetes membantu proyek-proyek, tim-tim dan pelanggan yang berbeda untuk berbagi klaster Kubernetes.
Sebuah mekanisme untuk memasang otorisasi dan kebijakan untuk bagian dari klaster.
Penggunaan Namespace berbeda merupakan hal opsional.
Tiap komunitas pengguna ingin bisa bekerja secara terisolasi dari komunitas lainnya.
Tiap komunitas pengguna memiliki hal berikut sendiri:
sumber daya (Pod, Service, ReplicationController, dll.)
kebijakan (siapa yang bisa atau tidak bisa melakukan hal tertentu dalam komunitasnya)
batasan (komunitas ini diberi kuota sekian, dll.)
Seorang operator klaster dapat membuat sebuah Namespace untuk tiap komunitas user yang unik.
Namespace tersebut memberikan cakupan yang unik untuk:
penamaan sumber daya (untuk menghindari benturan penamaan dasar)
pendelegasian otoritas pengelolaan untuk pengguna yang dapat dipercaya
kemampuan untuk membatasi konsumsi sumber daya komunitas
Contoh penggunaan mencakup
Sebagai operator klaster, aku ingin mendukung beberapa komunitas pengguna dalam sebuah klaster.
Sebagai operator klaster, aku ingin mendelegasikan otoritas untuk mempartisi klaster ke pengguna terpercaya di komunitasnya.
Sebagai operator klaster, aku ingin membatasi jumlah sumber daya yang bisa dikonsumsi komunitas dalam rangka membatasi dampak ke komunitas lain yang menggunakan klaster yang sama.
Sebagai pengguna klaster, aku ingin berinteraksi dengan sumber daya yang berkaitan dengan komunitas pengguna saya secara terisolasi dari apa yang dilakukan komunitas lain di klaster yang sama.
Memahami Namespace dan DNS
Ketika kamu membuat sebuah Service, akan terbentuk entri DNS untuk Service tersebut.
Entri DNS ini dalam bentuk <service-name>.<namespace-name>.svc.cluster.local, yang berarti jika sebuah Container hanya menggunakan <service-name> maka dia akan me-resolve ke layanan yang lokal dalam Namespace yang sama. Ini berguna untuk menggunakan konfigurasi yang sama pada Namespace yang berbeda seperti Development, Staging dan Production. Jika kami ingin menjangkau antar Namespace, kamu harus menggunakan fully qualified domain name (FQDN).
4.7 - Mengatur Control Plane Kubernetes dengan Ketersediaan Tinggi (High-Availability)
FEATURE STATE:Kubernetes v1.5 [alpha]
Kamu dapat mereplikasi control plane Kubernetes dalam skrip kube-up atau kube-down untuk Google Compute Engine (GCE).
Dokumen ini menjelaskan cara menggunakan skrip kube-up/down untuk mengelola control plane dengan ketersedian tinggi atau high_availability (HA) dan bagaimana control plane HA diimplementasikan untuk digunakan dalam GCE.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Untuk membuat klaster yang kompatibel dengan HA, kamu harus mengatur tanda ini pada skrip kube-up:
MULTIZONE=true - untuk mencegah penghapusan replika control plane kubelet dari zona yang berbeda dengan zona bawaan server.
Ini diperlukan jika kamu ingin menjalankan replika control plane pada zona berbeda, dimana hal ini disarankan.
ENABLE_ETCD_QUORUM_READ=true - untuk memastikan bahwa pembacaan dari semua server API akan mengembalikan data terbaru.
Jika true, bacaan akan diarahkan ke replika pemimpin dari etcd.
Menetapkan nilai ini menjadi true bersifat opsional: pembacaan akan lebih dapat diandalkan tetapi juga akan menjadi lebih lambat.
Sebagai pilihan, kamu dapat menentukan zona GCE tempat dimana replika control plane pertama akan dibuat.
Atur tanda berikut:
KUBE_GCE_ZONE=zone - zona tempat di mana replika control plane pertama akan berjalan.
Berikut ini contoh perintah untuk mengatur klaster yang kompatibel dengan HA pada zona GCE europe-west1-b:
Perhatikan bahwa perintah di atas digunakan untuk membuat klaster dengan sebuah control plane;
Namun, kamu bisa menambahkan replika control plane baru ke klaster dengan perintah berikutnya.
Menambahkan replika control plane yang baru
Setelah kamu membuat klaster yang kompatibel dengan HA, kamu bisa menambahkan replika control plane ke sana.
Kamu bisa menambahkan replika control plane dengan menggunakan skrip kube-up dengan tanda berikut ini:
KUBE_REPLICATE_EXISTING_MASTER=true - untuk membuat replika dari control plane yang sudah ada.
KUBE_GCE_ZONE=zone - zona di mana replika control plane itu berjalan.
Region ini harus sama dengan region dari zona replika yang lain.
Kamu tidak perlu mengatur tanda MULTIZONE atau ENABLE_ETCD_QUORUM_READS,
karena tanda itu diturunkan pada saat kamu memulai klaster yang kompatible dengan HA.
Berikut ini contoh perintah untuk mereplikasi control plane pada klaster sebelumnya yang kompatibel dengan HA:
Kamu dapat menghapus replika control plane dari klaster HA dengan menggunakan skrip kube-down dengan tanda berikut:
KUBE_DELETE_NODES=false - untuk mencegah penghapusan kubelet.
KUBE_GCE_ZONE=zone - zona di mana replika control plane akan dihapus.
KUBE_REPLICA_NAME=replica_name - (opsional) nama replika control plane yang akan dihapus.
Jika kosong: replika mana saja dari zona yang diberikan akan dihapus.
Berikut ini contoh perintah untuk menghapus replika control plane dari klaster HA yang sudah ada sebelumnya:
Jika salah satu replika control plane di klaster HA kamu gagal,
praktek terbaik adalah menghapus replika dari klaster kamu dan menambahkan replika baru pada zona yang sama.
Berikut ini contoh perintah yang menunjukkan proses tersebut:
Praktek terbaik untuk mereplikasi control plane untuk klaster HA
Usahakan untuk menempatkan replika control plane pada zona yang berbeda. Pada saat terjadi kegagalan zona, semua control plane yang ditempatkan dalam zona tersebut akan gagal pula.
Untuk bertahan dari kegagalan pada sebuah zona, tempatkan juga Node pada beberapa zona yang lain
(Lihatlah multi-zona untuk lebih detail).
Jangan gunakan klaster dengan dua replika control plane. Konsensus pada klaster dengan dua replika membutuhkan kedua replika tersebut berjalan pada saat mengubah keadaan yang persisten.
Akibatnya, kedua replika tersebut diperlukan dan kegagalan salah satu replika mana pun mengubah klaster dalam status kegagalan mayoritas.
Dengan demikian klaster dengan dua replika lebih buruk, dalam hal HA, daripada klaster dengan replika tunggal.
Ketika kamu menambahkan sebuah replika control plane, status klaster (etcd) disalin ke sebuah instance baru.
Jika klaster itu besar, mungkin butuh waktu yang lama untuk menduplikasi keadaannya.
Operasi ini dapat dipercepat dengan memigrasi direktori data etcd, seperti yang dijelaskan di sini
(Kami sedang mempertimbangkan untuk menambahkan dukungan untuk migrasi direktori data etcd di masa mendatang).
Catatan implementasi
Ikhtisar
Setiap replika control plane akan menjalankan komponen berikut dalam mode berikut:
instance etcd: semua instance akan dikelompokkan bersama menggunakan konsensus;
server API : setiap server akan berbicara dengan lokal etcd - semua server API pada cluster akan tersedia;
pengontrol (controller), penjadwal (scheduler), dan scaler klaster automatis: akan menggunakan mekanisme sewa - dimana hanya satu instance dari masing-masing mereka yang akan aktif dalam klaster;
manajer tambahan (add-on): setiap manajer akan bekerja secara independen untuk mencoba menjaga tambahan dalam sinkronisasi.
Selain itu, akan ada penyeimbang beban (load balancer) di depan server API yang akan mengarahkan lalu lintas eksternal dan internal menuju mereka.
Penyeimbang Beban
Saat memulai replika control plane kedua, penyeimbang beban yang berisi dua replika akan dibuat
dan alamat IP dari replika pertama akan dipromosikan ke alamat IP penyeimbang beban.
Demikian pula, setelah penghapusan replika control plane kedua yang dimulai dari paling akhir, penyeimbang beban akan dihapus dan alamat IP-nya akan diberikan ke replika terakhir yang ada.
Mohon perhatikan bahwa pembuatan dan penghapusan penyeimbang beban adalah operasi yang rumit dan mungkin perlu beberapa waktu (~20 menit) untuk dipropagasikan.
Service control plane & kubelet
Daripada sistem mencoba untuk menjaga daftar terbaru dari apiserver Kubernetes yang ada dalam Service Kubernetes,
sistem akan mengarahkan semua lalu lintas ke IP eksternal:
dalam klaster dengan satu control plane, IP diarahkan ke control plane tunggal.
dalam klaster dengan multiple control plane, IP diarahkan ke penyeimbang beban yang ada di depan control plane.
Demikian pula, IP eksternal akan digunakan oleh kubelet untuk berkomunikasi dengan control plane.
Sertifikat control plane
Kubernetes menghasilkan sertifikat TLS control plane untuk IP publik eksternal dan IP lokal untuk setiap replika.
Tidak ada sertifikat untuk IP publik sementara (ephemeral) dari replika;
Untuk mengakses replika melalui IP publik sementara, kamu harus melewatkan verifikasi TLS.
Pengklasteran etcd
Untuk mengizinkan pengelompokkan etcd, porta yang diperlukan untuk berkomunikasi antara instance etcd akan dibuka (untuk komunikasi dalam klaster).
Untuk membuat penyebaran itu aman, komunikasi antara instance etcd diotorisasi menggunakan SSL.
4.8 - Menggunakan sysctl dalam Sebuah Klaster Kubernetes
FEATURE STATE:Kubernetes v1.12 [beta]
Dokumen ini menjelaskan tentang cara mengonfigurasi dan menggunakan parameter kernel dalam sebuah
klaster Kubernetes dengan menggunakan antarmuka sysctl.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Dalam Linux, antarmuka sysctl memungkinkan administrator untuk memodifikasi kernel
parameter pada runtime. Parameter tersedia melalui sistem file virtual dari proses /proc/sys/.
Parameter mencakup berbagai subsistem seperti:
Untuk mendapatkan daftar semua parameter, kamu bisa menjalankan perintah:
sudo sysctl -a
Mengaktifkan Sysctl Unsafe
Sysctl dikelompokkan menjadi sysctl safe dan sysctl unsafe. Sebagai tambahan untuk
pengaturan Namespace yang benar, sebuah sysctl safe harus diisolasikan dengan benar diantara Pod dalam Node yang sama.
Hal ini berarti mengatur sysctl safe dalam satu Pod:
tidak boleh mempengaruhi Pod lain dalam Node
tidak boleh membahayakan kesehatan dari Node
tidak mengizinkan untuk mendapatkan sumber daya CPU atau memori di luar batas sumber daya dari sebuah Pod.
Sejauh ini, sebagian besar sysctl yang diatur sebagai Namespace belum tentu dianggap sysctl safe.
Sysctl berikut ini didukung dalam kelompok safe:
Contoh net.ipv4.tcp_syncookies bukan merupakan Namespace pada kernel Linux versi 4.4 atau lebih rendah.
Daftar ini akan terus dikembangkan dalam versi Kubernetes berikutnya ketika kubelet
mendukung mekanisme isolasi yang lebih baik.
Semua sysctl safe diaktifkan secara bawaan.
Semua sysctl unsafe dinon-aktifkan secara bawaan dan harus diizinkan secara manual oleh
administrator klaster untuk setiap Node. Pod dengan sysctl unsafe yang dinon-aktifkan akan dijadwalkan,
tetapi akan gagal untuk dijalankan.
Dengan mengingat peringatan di atas, administrator klaster dapat mengizinkan sysctl unsafe tertentu
untuk situasi yang sangat spesial seperti pada saat kinerja tinggi atau
penyetelan aplikasi secara real-time. Unsafe syctl diaktifkan Node demi Node melalui
flag pada kubelet; sebagai contoh:
Hanya sysctl yang diatur sebagai Namespace dapat diaktifkan dengan cara ini.
Mnegatur Sysctl untuk Pod
Sejumlah sysctl adalah diatur sebagai Namespace dalam Kernel Linux hari ini. Ini berarti
mereka dapat diatur secara independen untuk setiap Pod dalam sebuah Node. Hanya sysctl dengan Namespace
yang dapat dikonfigurasi melalui Pod securityContext dalam Kubernetes.
Sysctl berikut dikenal sebagai Namespace. Daftar ini dapat berubah
pada versi kernel Linux yang akan datang.
kernel.shm*,
kernel.msg*,
kernel.sem,
fs.mqueue.*,
Parameter dibawah net.* dapat diatur sebagai Namespace dari container networking
Namun, ada beberapa perkecualian (seperti
net.netfilter.nf_conntrack_max dan net.netfilter.nf_conntrack_expect_max
yang dapat diatur dalam Namespace container networking padahal bukan merupakan Namespace).
Sysctl tanpa Namespace disebut dengan sysctl node-level. Jika kamu perlu mengatur
mereka, kamu harus secara manual mengonfigurasi mereka pada sistem operasi setiap Node, atau dengan
menggunakan DaemonSet melalui Container yang berwenang.
Gunakan securityContext dari Pod untuk mengonfigurasi sysctl Namespace. securityContext
berlaku untuk semua Container dalam Pod yang sama.
Contoh ini menggunakan securityContext dari Pod untuk mengatur sebuah sysctl safekernel.shm_rmid_forced, dan dua buah sysctl unsafenet.core.somaxconn dan
kernel.msgmax. Tidak ada perbedaan antara sysctl safe dan sysctl unsafe dalam
spesifikasi tersebut.
Peringatan: Hanya modifikasi parameter sysctl setelah kamu memahami efeknya, untuk menghindari
gangguan pada kestabilan sistem operasi kamu.
Peringatan: Karena sifat alami dari sysctl unsafe, penggunaan sysctl unsafe
merupakan resiko kamu sendiri dan dapat menyebabkan masalah parah seperti perilaku yang salah
pada Container, kekurangan sumber daya, atau kerusakan total dari Node.
Merupakan sebuah praktik yang baik untuk mempertimbangkan Node dengan pengaturan sysctl khusus sebagai
Node yang tercemar (tainted) dalam sebuah cluster, dan hanya menjadwalkan Pod yang membutuhkan pengaturan sysctl.
Sangat disarankan untuk menggunakan Kubernetes fitur taints and toleration untuk mengimplementasikannya.
Pod dengan sysctl unsafe akan gagal diluncurkan pada sembarang Node yang belum
mengaktifkan kedua sysctl unsafe secara eksplisit. Seperti halnya sysctl node-level sangat
disarankan untuk menggunakan fitur taints and toleration atau
pencemaran dalam Node
untuk Pod dalam Node yang tepat.
PodSecurityPolicy
Kamu selanjutnya dapat mengontrol sysctl mana saja yang dapat diatur dalam Pod dengan menentukan daftar
sysctl atau pola (pattern) sysctl dalam forbiddenSysctls dan/atau fieldallowedUnsafeSysctls dari PodSecurityPolicy. Pola sysctl diakhiri
dengan karakter *, seperti kernel.*. Karakter * saja akan mencakup
semua sysctl.
Secara bawaan, semua sysctl safe diizinkan.
Kedua forbiddenSysctls dan allowedUnsafeSysctls merupakan daftar dari nama sysctl
atau pola sysctl yang polos (yang diakhiri dengan karakter *). Karakter * saja berarti sesuai dengan semua sysctl.
FieldforbiddenSysctls tidak memasukkan sysctl tertentu. Kamu dapat melarang
kombinasi sysctl safe dan sysctl unsafe dalam daftar tersebut. Untuk melarang pengaturan
sysctl, hanya gunakan * saja.
Jika kamu menyebutkan sysctl unsafe pada fieldallowedUnsafeSysctls dan
tidak ada pada fieldforbiddenSysctls, maka sysctl dapat digunakan pada Pod
dengan menggunakan PodSecurityPolicy ini. Untuk mengizinkan semua sysctl unsafe diatur dalam
PodSecurityPolicy, gunakan karakter * saja.
Jangan mengonfigurasi kedua field ini sampai tumpang tindih, dimana
sysctl yang diberikan akan diperbolehkan dan dilarang sekaligus.
Peringatan: Jika kamu mengizinkan sysctl unsafe melalui fieldallowUnsafeSysctls
pada PodSecurityPolicy, Pod apa pun yang menggunakan sysctl seperti itu akan gagal dimulai
jika sysctl unsafe tidak diperbolehkan dalam flag kubelet --allowed-unsafe-sysctls
pada Node tersebut.
Ini merupakan contoh sysctl unsafe yang diawali dengan kernel.msg yang diperbolehkan dan
sysctl kernel.shm_rmid_forced yang dilarang.
4.9 - Mengoperasikan klaster etcd untuk Kubernetes
etcd adalah penyimpanan key value konsisten yang digunakan sebagai penyimpanan data klaster Kubernetes.
Selalu perhatikan mekanisme untuk mem-backup data etcd pada klaster Kubernetes kamu. Untuk informasi lebih lanjut tentang etcd, lihat dokumentasi etcd.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Jalankan etcd sebagai klaster dimana anggotanya berjumlah ganjil.
Etcd adalah sistem terdistribusi berbasis leader. Pastikan leader secara berkala mengirimkan heartbeat dengan tepat waktu ke semua pengikutnya untuk menjaga kestabilan klaster.
Pastikan tidak terjadi kekurangan sumber daya.
Kinerja dan stabilitas dari klaster sensitif terhadap jaringan dan IO disk. Kekurangan sumber daya apa pun dapat menyebabkan timeout dari heartbeat, yang menyebabkan ketidakstabilan klaster. Etcd yang tidak stabil mengindikasikan bahwa tidak ada leader yang terpilih. Dalam keadaan seperti itu, sebuah klaster tidak dapat membuat perubahan apa pun ke kondisi saat ini, yang menyebabkan tidak ada Pod baru yang dapat dijadwalkan.
Menjaga kestabilan klaster etcd sangat penting untuk stabilitas klaster Kubernetes. Karenanya, jalankan klaster etcd pada mesin khusus atau lingkungan terisolasi untuk persyaratan sumber daya terjamin.
Versi minimum yang disarankan untuk etcd yang dijalankan dalam lingkungan produksi adalah 3.2.10+.
Persyaratan sumber daya
Mengoperasikan etcd dengan sumber daya terbatas hanya cocok untuk tujuan pengujian. Untuk peluncuran dalam lingkungan produksi, diperlukan konfigurasi perangkat keras lanjutan. Sebelum meluncurkan etcd dalam produksi, lihat dokumentasi referensi persyaratan sumber daya.
Memulai Klaster etcd
Bagian ini mencakup bagaimana memulai klaster etcd dalam Node tunggal dan Node multipel.
Klaster etcd dalam Node tunggal
Gunakan Klaster etcd Node tunggal hanya untuk tujuan pengujian
Start server API Kubernetes dengan flag--etcd-servers=$PRIVATE_IP:2379.
Ganti PRIVATE_IP dengan IP klien etcd kamu.
Klaster etcd dengan Node multipel
Untuk daya tahan dan ketersediaan tinggi, jalankan etcd sebagai klaster dengan Node multipel dalam lingkungan produksi dan cadangkan secara berkala. Sebuah klaster dengan lima anggota direkomendasikan dalam lingkungan produksi. Untuk informasi lebih lanjut, lihat Dokumentasi FAQ.
Mengkonfigurasi klaster etcd baik dengan informasi anggota statis atau dengan penemuan dinamis. Untuk informasi lebih lanjut tentang pengklasteran, lihat Dokumentasi pengklasteran etcd.
Sebagai contoh, tinjau sebuah klaster etcd dengan lima anggota yang berjalan dengan URL klien berikut: http://$IP1:2379, http://$IP2:2379, http://$IP3:2379, http://$IP4:2379, dan http://$IP5:2379. Untuk memulai server API Kubernetes:
Start server Kubernetes API dengan flag --etcd-servers=$IP1:2379, $IP2:2379, $IP3:2379, $IP4:2379, $IP5:2379.
Ganti IP dengan alamat IP klien kamu.
Klaster etcd dengan Node multipel dengan load balancer
Untuk menjalankan penyeimbangan beban (load balancing) untuk klaster etcd:
Siapkan sebuah klaster etcd.
Konfigurasikan sebuah load balancer di depan klaster etcd.
Sebagai contoh, anggap saja alamat load balancer adalah $LB.
Mulai Server API Kubernetes dengan flag--etcd-servers=$LB:2379.
Mengamankan klaster etcd
Akses ke etcd setara dengan izin root pada klaster sehingga idealnya hanya server API yang memiliki akses ke etcd. Dengan pertimbangan sensitivitas data, disarankan untuk memberikan izin hanya kepada Node-Node yang membutuhkan akses ke klaster etcd.
Untuk mengamankan etcd, tetapkan aturan firewall atau gunakan fitur keamanan yang disediakan oleh etcd. Fitur keamanan etcd tergantung pada Infrastruktur Kunci Publik / Public Key Infrastructure (PKI) x509. Untuk memulai, buat saluran komunikasi yang aman dengan menghasilkan pasangan kunci dan sertifikat. Sebagai contoh, gunakan pasangan kunci peer.key dan peer.cert untuk mengamankan komunikasi antara anggota etcd, dan client.key dan client.cert untuk mengamankan komunikasi antara etcd dan kliennya. Lihat contoh skrip yang disediakan oleh proyek etcd untuk menghasilkan pasangan kunci dan berkas CA untuk otentikasi klien.
Mengamankan komunikasi
Untuk mengonfigurasi etcd dengan secure peer communication, tentukan flag--peer-key-file=peer.key dan --peer-cert-file=peer.cert, dan gunakan https sebagai skema URL.
Demikian pula, untuk mengonfigurasi etcd dengan secure client communication, tentukan flag--key-file=k8sclient.key dan --cert-file=k8sclient.cert, dan gunakan https sebagai skema URL.
Membatasi akses klaster etcd
Setelah konfigurasi komunikasi aman, batasi akses klaster etcd hanya ke server API Kubernetes. Gunakan otentikasi TLS untuk melakukannya.
Sebagai contoh, anggap pasangan kunci k8sclient.key dan k8sclient.cert dipercaya oleh CA etcd.ca. Ketika etcd dikonfigurasi dengan --client-cert-auth bersama dengan TLS, etcd memverifikasi sertifikat dari klien dengan menggunakan CA dari sistem atau CA yang dilewati oleh flag--trusted-ca-file. Menentukan flag--client-cert-auth=true dan --trusted-ca-file=etcd.ca akan membatasi akses kepada klien yang mempunyai sertifikat k8sclient.cert.
Setelah etcd dikonfigurasi dengan benar, hanya klien dengan sertifikat yang valid dapat mengaksesnya. Untuk memberikan akses kepada server Kubernetes API, konfigurasikan dengan flag--etcd-certfile=k8sclient.cert,--etcd-keyfile=k8sclient.key dan --etcd-cafile=ca.cert.
Catatan: Otentikasi etcd saat ini tidak didukung oleh Kubernetes. Untuk informasi lebih lanjut, lihat masalah terkait Mendukung Auth Dasar untuk Etcd v2.
Mengganti anggota etcd yang gagal
Etcd klaster mencapai ketersediaan tinggi dengan mentolerir kegagalan dari sebagian kecil anggota. Namun, untuk meningkatkan kesehatan keseluruhan dari klaster, segera ganti anggota yang gagal. Ketika banyak anggota yang gagal, gantilah satu per satu. Mengganti anggota yang gagal melibatkan dua langkah: menghapus anggota yang gagal dan menambahkan anggota baru.
Meskipun etcd menyimpan ID anggota unik secara internal, disarankan untuk menggunakan nama unik untuk setiap anggota untuk menghindari kesalahan manusia. Sebagai contoh, sebuah klaster etcd dengan tiga anggota. Jadikan URL-nya, member1=http://10.0.0.1, member2=http://10.0.0.2, and member3=http://10.0.0.3. Ketika member1 gagal, ganti dengan member4=http://10.0.0.4.
Dapatkan ID anggota yang gagal dari member1:
etcdctl --endpoints=http://10.0.0.2,http://10.0.0.3 member list
Semua objek Kubernetes disimpan dalam etcd. Mencadangkan secara berkala data klaster etcd penting untuk memulihkan klaster Kubernetes di bawah skenario bencana, seperti kehilangan semua Node control plane. Berkas snapshot berisi semua status Kubernetes dan informasi penting. Untuk menjaga data Kubernetes yang sensitif aman, enkripsi berkas snapshot.
Mencadangkan klaster etcd dapat dilakukan dengan dua cara: snapshot etcd bawaan dan snapshot volume.
Snapshot bawaan
Fitur snapshot didukung oleh etcd secara bawaan, jadi mencadangkan klaster etcd lebih mudah. Snapshot dapat diambil dari anggota langsung dengan command etcdctl snapshot save atau dengan menyalin member/snap/db berkas dari etcd direktori data yang saat ini tidak digunakan oleh proses etcd. Mengambil snapshot biasanya tidak akan mempengaruhi kinerja anggota.
Di bawah ini adalah contoh untuk mengambil snapshot dari keyspace yang dilayani oleh $ENDPOINT ke berkas snapshotdb:
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshotdb
# keluar 0# memverifikasi hasil snapshotETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshotdb
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| fe01cf57 | 10 | 7 | 2.1 MB |
+----------+----------+------------+------------+
Snapshot volume
Jika etcd berjalan pada volume penyimpanan yang mendukung cadangan, seperti Amazon Elastic Block Store, buat cadangan data etcd dengan mengambil snapshot dari volume penyimpanan.
Memperbesar skala dari klaster etcd
Peningkatan skala klaster etcd meningkatkan ketersediaan dengan menukarnya untuk kinerja. Penyekalaan tidak akan meningkatkan kinerja atau kemampuan klaster. Aturan umum adalah untuk tidak melakukan penyekalaan naik atau turun untuk klaster etcd. Jangan mengonfigurasi grup penyekalaan otomatis untuk klaster etcd. Sangat disarankan untuk selalu menjalankan klaster etcd statis dengan lima anggota untuk klaster produksi Kubernetes untuk setiap skala yang didukung secara resmi.
Penyekalaan yang wajar adalah untuk meningkatkan klaster dengan tiga anggota menjadi dengan lima anggota, ketika dibutuhkan lebih banyak keandalan. Lihat Dokumentasi Rekonfigurasi etcd untuk informasi tentang cara menambahkan anggota ke klaster yang ada.
Memulihkan klaster etcd
Etcd mendukung pemulihan dari snapshot yang diambil dari proses etcd dari versi major.minor. Memulihkan versi dari versi patch lain dari etcd juga didukung. Operasi pemulihan digunakan untuk memulihkan data klaster yang gagal.
Sebelum memulai operasi pemulihan, berkas snapshot harus ada. Ini bisa berupa berkas snapshot dari operasi pencadangan sebelumnya, atau dari sisa direktori data. Untuk informasi dan contoh lebih lanjut tentang memulihkan klaster dari berkas snapshot, lihat dokumentasi pemulihan bencana etcd.
Jika akses URL dari klaster yang dipulihkan berubah dari klaster sebelumnya, maka server API Kubernetes harus dikonfigurasi ulang sesuai dengan URL tersebut. Pada kasus ini, start kembali server API Kubernetes dengan flag--etcd-servers=$NEW_ETCD_CLUSTER bukan flag--etcd-servers=$OLD_ETCD_CLUSTER. Ganti $NEW_ETCD_CLUSTER dan $OLD_ETCD_CLUSTER dengan alamat IP masing-masing. Jika load balancer digunakan di depan klaster etcd, kamu mungkin hanya perlu memperbarui load balancer sebagai gantinya.
Jika mayoritas anggota etcd telah gagal secara permanen, klaster etcd dianggap gagal. Dalam skenario ini, Kubernetes tidak dapat membuat perubahan apa pun ke kondisi saat ini. Meskipun Pod terjadwal mungkin terus berjalan, tidak ada Pod baru yang bisa dijadwalkan. Dalam kasus seperti itu, pulihkan klaster etcd dan kemungkinan juga untuk mengonfigurasi ulang server API Kubernetes untuk memperbaiki masalah ini.
Memutakhirkan dan memutar balikan klaster etcd
Pada Kubernetes v1.13.0, etcd2 tidak lagi didukung sebagai backend penyimpanan untuk klaster Kubernetes baru atau yang sudah ada. Timeline untuk dukungan Kubernetes untuk etcd2 dan etcd3 adalah sebagai berikut:
Kubernetes v1.0: hanya etcd2
Kubernetes v1.5.1: dukungan etcd3 ditambahkan, standar klaster baru yang dibuat masih ke etcd2
Kubernetes v1.6.0: standar klaster baru yang dibuat dengan kube-up.sh adalah etcd3,
dan kube-apiserver standarnya ke etcd3
Kubernetes v1.13.0: backend penyimpanan etcd2 dihapus, kube-apiserver akan
menolak untuk start dengan --storage-backend=etcd2, dengan pesan
etcd2 is no longer a supported storage backend
Sebelum memutakhirkan v1.12.x kube-apiserver menggunakan --storage-backend=etcd2 ke
v1.13.x, data etcd v2 harus dimigrasikan ke backend penyimpanan v3 dan
permintaan kube-apiserver harus diubah untuk menggunakan --storage-backend=etcd3.
Proses untuk bermigrasi dari etcd2 ke etcd3 sangat tergantung pada bagaimana
klaster etcd diluncurkan dan dikonfigurasi, serta bagaimana klaster Kubernetes diluncurkan dan dikonfigurasi. Kami menyarankan kamu berkonsultasi dengan dokumentasi penyedia kluster kamu untuk melihat apakah ada solusi yang telah ditentukan.
Masalah umum: penyeimbang klien etcd dengan secure endpoint
Klien etcd v3, dirilis pada etcd v3.3.13 atau sebelumnya, memiliki critical bug yang mempengaruhi kube-apiserver dan penyebaran HA. Pemindahan kegagalan (failover) penyeimbang klien etcd tidak bekerja dengan baik dengan secure endpoint. Sebagai hasilnya, server etcd boleh gagal atau terputus sesaat dari kube-apiserver. Hal ini mempengaruhi peluncuran HA dari kube-apiserver.
Perbaikan dibuat di etcd v3.4 (dan di-backport ke v3.3.14 atau yang lebih baru): klien baru sekarang membuat bundel kredensial sendiri untuk menetapkan target otoritas dengan benar dalam fungsi dial.
Paradigma deklaratif dan imperatif untuk berinteraksi dengan API Kubernetes.
5.1 - Pengelolaan Objek Kubernetes secara Deklaratif dengan Menggunakan Berkas Konfigurasi
Objek-objek Kubernetes dapat dibuat, diperbarui, dan dihapus dengan menjalankan perintah kubectl apply terhadap file-file konfigurasi objek yang disimpan dalam sebuah direktori secara rekursif sesuai dengan kebutuhan. Perintah kubectl diff bisa digunakan untuk menampilkan pratinjau tentang perubahan apa saja yang akan dibuat oleh perintah kubectil apply.
Kelebihan dan kekurangan
Perintah kubectl memungkinkan tiga cara untuk mengelola objek:
Perintah imperatif
Konfigurasi objek imperatif
Konfigurasi objek deklaratif
Lihat Pengelolaan Objek Kubernetes untuk menyimak diskusi mengenai kelebihan dan kekurangan dari tiap cara pengelolaan objek.
Sebelum kamu mulai
Konfigurasi objek secara deklaratif membutuhkan pemahaman yang baik
tentang definisi dan konfigurasi objek-objek Kubernetes. Jika belum pernah, kamu disarankan untuk membaca terlebih dulu dokumen-dokumen berikut:
Berikut adalah beberapa defnisi dari istilah-istilah yang digunakan
dalam dokumen ini:
objek berkas konfigurasi / berkas konfigurasi: Sebuah file yang
mendefinisikan konfigurasi untuk sebuah objek Kubernetes. Dokumen ini akan memperlihatkan cara menggunakan file konfigurasi dengan perintah kubectl apply. File-file konfigurasi biasanya disimpan di sebuah source control seperti Git.
konfigurasi objek live / konfigurasi live: nilai konfigurasi live dari sebuah objek, sebagaimana yang tersimpan di klaster Kubernetes. Nilai-nilai ini disimpan di storage klaster Kubernetes, biasanya etcd.
writer konfigurasi deklaratif / writer deklaratif: Seseorang atau sebuah komponen perangkat lunak yang membuat pembaruan ke objek live. Live writer yang disebut pada dokumen ini adalah writer yang membuat perubahan terhadap file konfigurasi objek dan menjalankan perintah kubectl apply untuk menulis perubahan-perubahan tersebut.
Cara membuat objek
Gunakan perintah kubectl apply untuk membuat semua objek, kecuali objek-objek yang sudah ada sebelumnya, yang didefinisikan di file-file konfigurasi dalam direktori yang ditentukan:
kubectl apply -f <directory>/
Perintah di atas akan memberi anotasi kubectl.kubernetes.io/last-applied-configuration: '{...}' pada setiap objek yang dibuat. Anotasi ini berisi konten dari file konfigurasi objek yang digunakan untuk membuat objek tersebut.
Catatan: Tambahkan parameter -R untuk memproses seluruh direktori secara rekursif.
Tampilkan konfigurasi live dengan perintah kubectl get:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
Keluaran perintah di atas akan menunjukkan bahwa anotasi kubectl.kubernetes.io/last-applied-configuration sudah dituliskan ke konfigurasi live, dan anotasi tersebut sesuai dengan file konfigurasi:
kind:Deploymentmetadata:annotations:# ...# Ini merupakan representasi dari simple_deployment.yaml dalam format json# Ini ditulis oleh perintah `kubectl apply` ketika objek dibuatkubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.7.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:# ...minReadySeconds:5selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.7.9# ...name:nginxports:- containerPort:80# ...# ...# ...# ...
Cara memperbarui objek
Kamu juga bisa menggunakan kubectl apply untuk memperbarui semua objek yang didefinisikan dalam sebuah direktori, termasuk objek-objek yang sudah ada sebelumnya. Cara ini akan melakukan hal-hal berikut:
Menyimpan nilai field-field yang ada di file konfigurasi ke konfigurasi live.
Menghapus field-field yang dihapus di file konfigurasi dari konfigurasi live.
Catatan: Untuk keperluan ilustrasi, perintah berikut merujuk ke satu file konfigurasi alih-alih ke satu direktori.
Tampilkan konfigurasi live dengan perintah kubectl get:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
Keluaran perintah di atas akan menunjukkan bahwa anotasi kubectl.kubernetes.io/last-applied-configuration sudah dituliskan ke konfigurasi live, dan anotasi tersebut sesuai dengan file konfigurasi:
kind:Deploymentmetadata:annotations:# ...# Berikut merupakan representasi dari simple_deployment.yaml dalam format json# Representasi berikut ditulis oleh perintah kubectl apply ketika objek dibuatkubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.7.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:# ...minReadySeconds:5selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.7.9# ...name:nginxports:- containerPort:80# ...# ...# ...# ...
Perbarui nilai replicas secara langsung di konfigurasi live dengan menggunakan perintah kubectl scale. Pembaruan ini tidak menggunakan perintah kubectl apply:
Tampilkan konfigurasi live dengan perintah kubectl get:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
Keluaran perintah di atas akan menunjukkan bahwa nilai replicas telah diubah menjadi 2, dan anotasi last-applied-configuration tidak memuat nilai replicas:
apiVersion:apps/v1kind:Deploymentmetadata:annotations:# ...# perhatikan bahwa anotasi tidak memuat nilai replicas# karena nilai tersebut tidak diperbarui melalui perintah kubectl-applykubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.7.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:replicas:2# ditulis oleh perintah kubectl scale# ...minReadySeconds:5selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.7.9# ...name:nginxports:- containerPort:80# ...
Perbarui file konfigurasi simple_deployment.yaml, ubah image dari nginx:1.7.9 ke nginx:1.11.9, dan hapus fieldminReadySeconds:
Tampilkan konfigurasi live dengan perintah kubectl get:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
Keluaran perintah di atas akan menunjukkan perubahan-perubahan berikut pada konfiguasi live:
Fieldreplicas tetap bernilai 2 sesuai dengan nilai yang diatur oleh perintah kubectl scale. Hal ini karena fieldreplicas dihapuskan dari file konfigurasi.
Nilai fieldimage telah diperbarui menjadi nginx:1.11.9 dari nginx:1.7.9.
Anotasi last-applied-configuration telah diperbari dengan image terbaru.
FieldminReadySeconds telah dihapus.
Anotasi last-applied-configuration tidak lagi memuat fieldminReadySeconds.
apiVersion:apps/v1kind:Deploymentmetadata:annotations:# ...# Anotasi memuat image yang telah diperbarui ke nginx 1.11.9,# tetapi tidak memuat nilai replica yang telah diperbarui menjadi 2kubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.11.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:replicas:2# Diatur oleh `kubectl scale`, tidak diubah oleh `kubectl apply`.# minReadySeconds dihapuskan oleh `kubectl apply`# ...selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.11.9# Diatur oleh `kubectl apply`# ...name:nginxports:- containerPort:80# ...# ...# ...# ...
Peringatan: Mencampur perintah kubectl apply dengan perintah imperatif untuk konfigurasi objek seperti create dan replace tidak dimungkinkan. Hal ini karena create dan replace tidak menyimpan anotasi kubectl.kubernetes.io/last-applied-configuration yang diperlukan oleh kubectl aplly untuk melakukan pembaruan.
Cara menghapus objek
Ada dua cara untuk menghapus objek-objek yang dikelola dengan kubectl apply.
Rekomendasi: kubectl delete -f <filename>
Penghapusan objek secara manual dengan menggunakan perintah imperatif merupakan cara yang direkomendasikan karena lebih eksplisit dalam menentukan objek apa yang akan dihapus dan lebih kecil kemungkinannya untuk pengguna menghapus objek lain secara tidak sengaja:
Lakukan ini hanya jika kamu benar-benar mengetahui apa yang kamu lakukan.
Peringatan: Perintah kubectl apply --prune masih dalam versi alpha dan perubahan-perubahan yang tidak memiliki kompatibilitas dengan versi sebelumnya mungkin akan diperkenalkan pada rilis-rilis berikutnya.
Peringatan: Kamu harus berhati-hati ketika menggunakan perintah ini agar kamu tidak menghapus objek-objek lain secara tak sengaja.
Sebagai alternatif dari kubectl delete, kamu bisa menggunakan kubectl apply untuk mengidentifikasi objek-objek yang hendak dihapus setelah berkas konfigurasi objek-objek tersebut dihapus dari direktori. Ketika dijalankan dengan argumen --prune, perintah kubectl apply akan melakukan query ke API server untuk mencari semua objek yang sesuai dengan himpunan label-label tertentu, dan berusaha untuk mencocokkan kofigurasi objek live yg diperoleh terhadap file konfigurasi objek. Jika sebuah objek cocok dengan query yang dilakukan, dan objek tersebut tidak memiliki file konfigurasi di direktori serta tidak memiliki anotasi last-applied-configuration, objek tersebut akan dihapus.
kubectl apply -f <directory/> --prune -l <labels>
Peringatan: Perintah kubectl apply dengan argumen --prune sebaiknya hanya dijalankan terhadap direktori root yang berisi file-file konfigurasi objek. Menjalankan perintah tadi terhadap sub direktori bisa menyebabkan terhapusnya objek-objek lain secara tidak disengaja jika objek-objek tersebut memenuhi kriteria selektor label yang dispesifikasikan oleh argumen -l <label> dan tidak muncul di sub direktori.
Cara melihat objek
Kamu bisa menggunakan perintah kubectl get dengan parameter -o yaml untuk melihat konfigurasi dari sebuah objek live:
kubectl get -f <filename|url> -o yaml
Cara kubectl apply menghitung perbedaan dan menggabungkan perubahan
Perhatian:Patch adalah operasi pembaruan yang lingkupnya spesifik terhadap sejumlah field dari sebuah objek alih-alih terhadap keseluruhan objek. Patch memungkinkan pembaruan terhadap himpunan field yang spesifik tanpa harus membaca keseluruhan objek terlebih dulu.
Ketika memperbarui konfigurasi live dari sebuah objek, kubectl apply melakukannya dengan mengirimkan request untuk melakukan patch ke API server. Patch mendefinisikan pembaruan-pembaruan yang likungpnya sepsifik terhadap sejumlah field dari objek konfigurasi live. Perintah kubectl apply menghitung patch request ini menggunakan file konfigurasi, konfigurasi live, dan anotasi last-applied-configuration yang tersimpan di konfigurasi live.
Perhitungan penggabungan patch
Perintah kubectl apply menulis konten dari berkas konfigurasi ke anotasi kubectl.kubernetes.io/last-applied-configuration. Ini digunakan untuk mengidentifikasi field apa saja yang telah dihapus dari file konfigurasi dan perlu dihapus dari konfigurasi live. Berikut adalah langkah-langkah yang digunakan untuk menghitung field apa saja yang harus dihapus atau diubah:
Hitung field-field yang perlu dihapus. Ini mencakup field-field yang ada di last-applied-configuration tapi tidak ada di file konfigurasi.
Hitung field-field yang perlu ditambah atau diubah. Ini mencakup field-field yang ada di file konfigurasi yang nilainya tidak sama dengan konfigurasi live.
Agar lebih jelas, simak contoh berikut. Misalkan, berikut adalah file konfigurasi untuk sebuah objek Deployment:
Juga, misalkan, berikut adalah konfigurasi live dari objek Deployment yang sama:
apiVersion:apps/v1kind:Deploymentmetadata:annotations:# ...# perhatikan bagaimana anotasi berikut tidak memuat replicas# karena replicas tidak diperbarui melalui perintah kubectl applykubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.7.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:replicas:2# ditulis oleh perintah kubectl scale# ...minReadySeconds:5selector:matchLabels:# ...app:nginxtemplate:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.7.9# ...name:nginxports:- containerPort:80# ...
Berikut merupakan perhitungan penggabungan yang akan dilakukan oleh perintah kubectl apply:
Hitung semua field yang akan dihapus dengan membaca nilai dari last-applied-configuration dan membandingkannya dengan nilai yang ada di file konfigurasi. Hapus semua field yang nilainya secara eksplisit diubah menjadi null pada file konfigurasi objek lokal terlepas dari apakah field-field tersebut ada di anotasi last-applied-configuration atau tidak. Pada contoh di atas, fieldminReadySeconds muncul pada anotasi last-applied-configuration, tapi tidak ada di file konfigurasi. Aksi: Hapus minReadySeconds dari konfigurasi live.
Hitung semua field yang akan diubah dengan membaca nilai-nilai dari file konfigurasi dan membandingkannya dengan nilai-nilai yang ada di konfigurasi live. Pada contoh ini, nilai dari fieldimage di file konfigurasi tidak sama dengan nilai dari konfigurasi live. Aksi: Ubah nilai image pada konfigurasi live.
Ubah anotasi last-applied-configuration agar sesuai dengan nilai yang ada di file konfigurasi.
Gabungkan hasil-hasil dari langkah 1, 2, dan 3 ke dalam satu patch request ke API server.
Berikut konfigurasi live yang dihasilkan oleh proses penggabungan pada contoh di atas:
apiVersion:apps/v1kind:Deploymentmetadata:annotations:# ...# Anotasi memuat pembaruan image menjadi nginx 1.11.9,# tetapi tidak memuat pembaruan replicas menjadi 2kubectl.kubernetes.io/last-applied-configuration:| {"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.11.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}# ...spec:selector:matchLabels:# ...app:nginxreplicas:2# Diubah oleh `kubectl scale`, tidak diubah oleh `kubectl apply`.# minReadySeconds dihapus oleh `kubectl apply`# ...template:metadata:# ...labels:app:nginxspec:containers:- image:nginx:1.11.9# Diubah oleh `kubectl apply`# ...name:nginxports:- containerPort:80# ...# ...# ...# ...
Cara penggabungan tipe-tipe field yang berbeda
Cara sebuah field terentu dalam sebuah file konfigurasi digabungkan dengan konfigurasi live bergantung pada tipe field tersebut. Ada beberapa tipe field:
primitif: field yang bertipe string, integer, atau boolean. Sebagai contoh, image dan replicas termasuk sebagai field primitif. Aksi:Replace.
map, atau objek: field yang bertipe map atau tipe kompleks yang mengandung sub field. Sebagai contoh, labels, annotations, spec, dan metadata termasuk sebagai map. Aksi: Lakukan penggabungan tiap-tiap elemen atau sub field.
list: field yang berisi sejumlah item yang tiap itemnya bisa berupa tipe primitif maupun map. Sebagai contoh, containers, ports, dan args termasuk sebagai list. Aksi: Bervariasi.
Ketika digunakan untuk memperbarui sebuah field bertipe map atau list, perintah kubectl apply memperbarui nilai tiap-tiap sub elemen ketimbang mengganti nilai semua field. Misalnya, ketika menggabungkan fieldspec pada sebuah Deployment, bukan keseluruhan fieldspec yang diubah nilainya. Alih-alih, sub field dari spec seperti replicas yang kemudian dibandingkan nilainya dan digabungkan.
Menggabungkan perubahan pada field primitif
Field primitif diganti nilainya atau dihapus sama sekali.
Catatan:- digunakan untuk menandai sebuah nilai "not applicable" karena nilai tersebut tidak digunakan.
Field pada file konfigurasi objek
Field pada objek konfigurasi live
Field pada last-applied-configuration
Aksi
Ya
Ya
-
Ubah nilai di konfigurasi live mengikuti nilai pada file konfigurasi.
Ya
Tidak
-
Ubah nilai di konfigurasi live mengikuti nilai pada konfigurasi lokal.
Tidak
-
Ya
Hapus dari konfigurasi live.
Tidak
-
Tidak
Tidak melakukan apa-apa, pertahankan nilai konfigurasi live.
Menggabungkan perubahan pada field bertipe map
Field yang bertipe map digabungkan dengan membandingkan tiap sub field atau elemen dari map:
Catatan:- digunakan untuk menandai sebuah nilai "not applicable" karena nilai tersebut tidak digunakan.
Key pada file konfigurasi objek
Key pada objek konfigurasi live
Field pada last-applied-configuration
Aksi
Ya
Ya
-
Bandingkan nilai tiap sub field.
Ya
Tidak
-
Ubah nilai pada konfigurasi live mengikuti nilai pada konfigurasi lokal.
Tidak
-
Ya
Hapus dari konfigurasi live.
Tidak
-
Tidak
Tidak melakukan apa-apa, pertahankan nilai konfigurasi live.
Menggabungkan perubahan pada field yang bertipe list
Penggabungan perubahan pada sebuah list bisa menggunakan salah satu dari tiga strategi:
Ganti nilai keseluruhan list.
Gabungkan nilai tiap-tiap elemen di dalam sebuah list yang elemennya kompleks.
Gabungkan list yang elemennya primitif.
Pilihan strategi dibuat berbeda-beda bergantung tipe tiap field.
Ganti nilai keseluruhan list
Perlakukan list sama dengan field primitif. Ganti atau hapus keseluruhan list. Ini akan menjaga urutan dari list.
Contoh: Gunakan kubectl apply untuk memperbarui fieldargs pada sebuah kontainer di dalam sebuah pod. Ini akan mengubah nilai args di konfigurasi live mengikuti nilai di file konfigurasi. Elemen args apapun yang sebelumnya ditambahkan ke konfigurasi live akan hilang. Urutan dari elemen-elemen args yang didefinisikan di file konfigurasi akan dipertahankan ketika ditulis ke konfigurasi live.
# nilai last-applied-configuration*args:["a","b"]# nilai berkas konfigurasiargs:["a","c"]# nilai konfigurasi liveargs:["a","b","d"]# hasil setelah penggabunganargs:["a","c"]
Penjelasan: Penggabungan menggunakan nilai pada file konfigurasi sebagai nilai baru untuk listargs.
Menggabungkan tiap-tiap elemen dari sebuah list dengan elemen kompleks:
Perlakukan list selayaknya sebuah map, perlakukan field spesifik dari tiap element sebagai sebuah key. Tambah, hapus, atau perbarui tiap-tiap elemen. Operasi ini tidak mempertahankan urutan elemen di dalam list.
Strategi penggabungan ini menggunakan tag khusus patchMergeKey pada tiap field. TagpatchMergeKey didefinisikan untuk tiap field pada source code Kubernetes: types.go. Ketika menggabungkan sebuah list yang berisi map, field yang dispesifikasikan sebagai patchMergeKey untuk tiap elemen digunakan sebagai map key untuk elemen tersebut.
Contoh: Gunakan kubectl apply untuk memperbarui fieldcontainers pada sebuah PodSpec. Perintah ini akan menggabungkan listcontainers seolah-olah list tersebut adalah sebuah map dan tiap elemennya menggunakan name sebagai key.
# nilai last-applied-configurationcontainers:- name:nginximage:nginx:1.10- name: nginx-helper-a # key:nginx-helper-a; akan dihapus pada hasil akhirimage:helper:1.3- name: nginx-helper-b # key:nginx-helper-b; akan dipertahankan pada hasil akhirimage:helper:1.3# nilai berkas konfigurasicontainers:- name:nginximage:nginx:1.10- name:nginx-helper-bimage:helper:1.3- name: nginx-helper-c # key:nginx-helper-c; akan ditambahkan pada hasil akhirimage:helper:1.3# konfigurasi livecontainers:- name:nginximage:nginx:1.10- name:nginx-helper-aimage:helper:1.3- name:nginx-helper-bimage:helper:1.3args:["run"]# Field ini akan dipertahankan pada hasil akhir- name: nginx-helper-d # key:nginx-helper-d; akan dipertahankan pada hasil akhirimage:helper:1.3# hasil akhir setelah penggabungancontainers:- name:nginximage:nginx:1.10# Elemen nginx-helper-a dihapus- name:nginx-helper-bimage:helper:1.3args:["run"]# Field dipertahankan- name:nginx-helper-c# Elemen ditambahkanimage:helper:1.3- name:nginx-helper-d# Elemen tidak diubahimage:helper:1.3
Penjelasan:
Kontainer dengan nama "nginx-helper-a" dihapus karena tidak ada kontainer dengan nama tersebut di file konfigurasi.
Kontainer dengan nama "nginx-helper-b" tetap mempertahankan nilai args pada konfigurasi live. Perintah kubectl apply bisa mengenali bahwa "nginx-helper-b" di konfigurasi live sama dengan "ngnix-helper-b" di file konfigurasi, meskipun keduanya memiliki field yang berbeda (tidak ada args pada file konfigurasi). Ini karena nilai patchMergeKey di kedua konfigurasi identik.
Kontainer dengan nama "nginx-helper-c" ditambahkan karena tidak ada kontainer dengan nama tersebut di konfigurasi live, tapi ada di file konfigurasi.
Kontainer dengan nama "nginx-helper-d" dipertahankan karena tidak ada elemen dengan nama tersebut pada last-applied-configuration.
Menggabungkan sebuah list dengan elemen-elemen primitif
Pada versi Kubernetes 1.5, penggabungan list dengan elemen-elemen primitif tidak lagi didukung.
Catatan: Strategi mana yang dipilih untuk sembarang field ditentukan oleh tagpatchStrategy pada types.go. Jika patchStrategy tidak ditentukan untuk sebuah field yang bertipe list, maka list tersebut akan diubah nilainya secara keseluruhan.
Nilai default dari sebuah field
API server mengisi field tertentu dengan nilai default pada konfigurasi live jika nilai field-field tersebut tidak dispesifikasikan ketika objek dibuat.
Berikut adalah sebuah file konfigurasi untuk sebuah Deployment. Berkas berikut tidak menspesifikasikan strategy:
Tampilkan konfigurasi live dengan perintah kubectl get:
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
Keluaran dari perintah tadi menunjukkan bahwa API server mengisi beberapa field dengan nilai default pada konfigurasi live. Field-field berikut tidak dispesifikan pada file konfigurasi.
apiVersion:apps/v1kind:Deployment# ...spec:selector:matchLabels:app:nginxminReadySeconds:5replicas:1# nilai default dari apiserverstrategy:rollingUpdate:# nilai default dari apiserver - diturunkan dari strategy.typemaxSurge:1maxUnavailable:1type:RollingUpdate# nilai default dari apiservertemplate:metadata:creationTimestamp:nulllabels:app:nginxspec:containers:- image:nginx:1.7.9imagePullPolicy:IfNotPresent# nilai default dari apiservername:nginxports:- containerPort:80protocol:TCP# nilai default dari apiserverresources:{}# nilai default dari apiserverterminationMessagePath:/dev/termination-log# nilai default dari apiserverdnsPolicy:ClusterFirst# nilai default dari apiserverrestartPolicy:Always# nilai default dari apiserversecurityContext:{}# nilai default dari apiserverterminationGracePeriodSeconds:30# nilai default dari apiserver# ...
Dalam sebuah patch request, field-field dengan nilai default tidak diisi kembali dengan nilai default kecuali secara eksplisit nilainya dihapuskan sebagai bagian dari patch request. Ini bisa menimbulkan hasil yang tak terduga jika sebagian field diisi dengan nilai default yang diturunkan dari nilai field lainnya. Ketika field lain tersebut nilainya diubah, field-field yang diisi dengan nilai default berdasarkan field yang berubah tadi tidak akan diperbarui kecuali secara eksplisit dihapus.
Oleh karena itu, beberapa field yang nilainya diisi secara default oleh server perlu didefinisikan secara eksplisit di file konfigurasi, meskipun nilai yang diinginkan sudah sesuai dengan nilai default dari server. Ini untuk mempermudah mengenali nilai-nilai yang berselisih yang tidak akan diisi dengan nilai default oleh server.
Contoh:
# last-applied-configurationspec:template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.7.9ports:- containerPort:80# berkas konfigurasispec:strategy:type:Recreate# nilai yang diperbaruitemplate:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.7.9ports:- containerPort:80# konfigurasi livespec:strategy:type:RollingUpdate# nilai defaultrollingUpdate:# nilai default yang diturunkan dari typemaxSurge :1maxUnavailable:1template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.7.9ports:- containerPort:80# hasil setelah penggabungan - ERROR!spec:strategy:type: Recreate # nilai yang diperbarui:tidak kompatibel dengan field rollingUpdaterollingUpdate: # nilai default:tidak kompatibel dengan "type: Recreate"maxSurge :1maxUnavailable:1template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.7.9ports:- containerPort:80
Penjelasan:
Pengguna sebelumnya sudah membuat sebuah Deployment tanpa mendefinisikan strategy.type (seperti yang bisa dilihat pada last-applied-configuration).
Server mengisi strategy.type dengan nilai defaultRollingUpdate dan mengisi strategy.rollingUpdate dengan nilai default pada konfigurasi live.
Pengguna mengubah nilai fieldstrategy.type menjadi Recreate pada file konfigurasi. Nilai strategy.rollingUpdate tidak berubah dari nilai default, meskipun server sekarang berekspektasi nilai tersebut dihapus. Jika nilai strategy.rollingUpdate didefinisikan di awal pada file konfigurasi, akan jelas bagi server bahwa field tersebut perlu dihapus.
Perintah kubect apply gagal karena strategy.rollingUpdate tidak dihapus. Fieldstrategy.rollingUpdate tidak bisa didefinisikan jika fieldstrategy.type berisi Recreate.
Rekomendasi: Field-field ini harus didefinisikan secara eksplisit di file konfigurasi objek:
Label Selectors dan PodTemplate pada workloads, misalnya Deployment, StatefulSet, Job, DaemonSet, ReplicaSet, dan ReplicationController
Strategi Deployment rollout
Cara menghilangkan field-field yang diisi dengan nilai default atau diisi oleh writer lainnya
Field-field yang tidak muncul di file konfigurasi bisa dihilangkan dengan mengisi nilainya dengan null dan kemudian jalankan kubectl apply dengan file konfigurasi tersebut. Untuk field-field yang nilainya diisi dengan nilai default oleh server, aksi ini akan mmenyebabkan pengisian ulang field dengan nilai default.
Cara mengubah kepemilikan sebuah field antara file konfigurasi dan writer imperatif
Hanya metode-metode berikut yang bisa kamu gunakan untuk mengubah satu field objek:
Gunakan kubectl apply.
Tulis secara langsung ke konfigurasi live tanpa memodifikasi file konfigurasi: misalnya, dengan perintah kubectl scale.
Mengubah kepemilikan dari writer imperatif ke file konfigurasi
Tambahkan field ke file konfigurasi. Hentikan pembaruan secara langsung ke konfigurasi live tanpa melalui kubectl apply.
Mengubah kepemilikan dari file konfigurasi ke writer imperatif
Pada versi Kubernetes 1.5, mengubah kepemilikan sebuah field dari file konfigurasi memerlukan langkah-langkah manual:
Hapus field dari file konfigurasi.
Hapus field dari anotasi kubectl.kubernetes.io/last-applied-configuration pada objek live.
Mengubah metode-metode pengelolaan objek
Objek-objek Kubernetes sebaiknya dikelola dengan satu metode dalam satu waktu. Berpindah dari satu metode ke metode lain dimungkinkan, tetapi memerlukan proses manual.
Catatan: Boleh menggunakan perintah hapus secara imperatif dalam pengelolaan objek secara deklaratif.
Migrasi dari pengelolaan dengan perintah imperatif ke konfigurasi objek deklaratif
Migrasi dari pengelolaan objek dengan perintah imperatif ke pengelolaan objek dengan konfigurasi deklaratif memerlukan beberapa langkah manual:
Ekspor objek live ke file konfigurasi lokal:
kubectl get <kind>/<name> -o yaml > <kind>_<name>.yaml
Hapus secara manual fieldstatus dari file konfigurasi.
Catatan: Tahap ini opsional, karena kubectl apply tidak memperbarui field status meskipun field tersebut ada di file konfigurasi.
Ubah anotasi kubectl.kubernetes.io/last-applied-configuration pada objek:
Gunakan selalu perintah kubectl apply saja untuk mengelola objek.
Pendefinisian selektor controller dan label PodTemplate
Peringatan: Pembaruan selektor pada controllers sangat tidak disarankan.
Cara yang disarankan adalah dengan mendefinisikan sebuah PodTemplate immutable yang hanya digunakan oleh selektor controller tanpa memiliki arti semantik lainnya.
5.2 - Mengelola Objek Kubernetes secara Deklaratif menggunakan Kustomize
Kustomize merupakan sebuah alat
untuk melakukan kustomisasi objek Kubernetes melalui sebuah berkas berkas kustomization.
Sejak versi 1.14, kubectl mendukung pengelolaan objek Kubernetes melalui berkas kustomization.
Untuk melihat sumber daya yang ada di dalam direktori yang memiliki berkas kustomization, jalankan perintah berikut:
kubectl kustomize <direktori_kustomization>
Untuk menerapkan sumber daya tersebut, jalankan perintah kubectl apply dengan flag--kustomize atau -k:
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Kustomize adalah sebuah alat untuk melakukan kustomisasi konfigurasi Kubernetes. Untuk mengelola berkas-berkas konfigurasi, kustomize memiliki fitur -fitur di bawah ini:
membangkitkan (generate) sumber daya dari sumber lain
mengatur field dari berbagai sumber daya yang bersinggungan
mengkomposisikan dan melakukan kustomisasi sekelompok sumber daya
Membangkitkan Sumber Daya
ConfigMap dan Secret menyimpan konfigurasi atau data sensitif yang digunakan oleh objek-objek Kubernetes lainnya, seperti Pod.
Biasanya, source of truth dari ConfigMap atau Secret berasal dari luar klaster, seperti berkas .properties atau berkas kunci SSH.
Kustomize memiliki secretGenerator dan configMapGenerator, yang akan membangkitkan (generate) Secret dan ConfigMap dari berkas-berkas atau nilai-nilai literal.
configMapGenerator
Untuk membangkitkan sebuah ConfigMap dari berkas, tambahkan entri ke daftar files pada configMapGenerator.
Contoh di bawah ini membangkitkan sebuah ConfigMap dengan data dari berkas .properties:
ConfigMap juga dapat dibangkitkan dari pasangan key-value literal. Untuk membangkitkan secara literal, tambahkan entri pada daftar literals di configMapGenerator.
Contoh di bawah ini membangkitkan ConfigMap dengan data dari pasangan key-value:
Kamu dapat membangkitkan Secret dari berkas atau pasangan key-value literal. Untuk membangkitkan dari berkas, tambahkan entri pada daftar files di secretGenerator.
Contoh di bawah ini membangkitkan Secret dengan data dari berkas:
Untuk membangkitkan secara literal dari pasangan key-value, tambahkan entri pada daftar literals di secretGenerator.
Contoh di bawah ini membangkitkan Secret dengan data dari pasangan key-value:
ConfigMap dan Secret yang dibangkitkan memiliki informasi sufiks hash. Hal ini memastikan bahwa ConfigMap atau Secret yang baru, dibangkitkan saat isinya berubah.
Untuk menonaktifkan penambahan sufiks ini, kamu bisa menggunakan generatorOptions. Selain itu, melalui field ini kamu juga bisa mengatur opsi-opsi yang bersinggungan untuk ConfigMap dan Secret yang dibangkitkan.
Mengkomposisi dan Melakukan Kustomisasi Sumber Daya
Mengkomposisi kumpulan sumber daya dalam sebuah proyek dan mengelolanya di dalam berkas atau direktori yang sama merupakan hal yang cukup umum dilakukan.
Kustomize menyediakan cara untuk mengkomposisi sumber daya dari berkas-berkas yang berbeda, lalu menerapkan patch atau kustomisasi lain di atasnya.
Melakukan Komposisi
Kustomize mendukung komposisi dari berbagai sumber daya yang berbeda. Fieldresources pada berkas kustomization.yaml, mendefinisikan daftar sumber daya yang diinginkan dalam sebuah konfigurasi. Atur terlebih dahulu jalur (path) ke berkas konfigurasi sumber daya pada daftar resources.
Contoh di bawah ini merupakan sebuah aplikasi NGINX yang terdiri dari sebuah Deployment dan sebuah Service:
Sumber daya dari kubectl kustomize ./ berisi kedua objek Deployment dan Service.
Melakukan Kustomisasi
Patch dapat digunakan untuk menerapkan berbagai macam kustomisasi pada sumber daya. Kustomize mendukung berbagai mekanisme patching yang berbeda melalui patchesStrategicMerge dan patchesJson6902. patchesStrategicMerge adalah daftar dari yang berisi tentang path berkas. Setiap berkas akan dioperasikan dengan cara strategic merge patch. Nama di dalam patch harus sesuai dengan nama sumber daya yang telah dimuat. Kami menyarankan patch-patch kecil yang hanya melakukan satu hal saja.
Contoh membuat sebuah patch di bawah ini akan menambahkan jumlah replika Deployment dan patch lainnya untuk mengatur limit memori.
Tidak semua sumber daya atau field mendukung strategic merge patch. Untuk mendukung field sembarang pada sumber daya field, Kustomize
menyediakan penerapan patch JSON melalui patchesJson6902.
Untuk mencari sumber daya yang tepat dengan sebuah patch Json, maka grup, versi, jenis dan nama dari sumber daya harus dispesifikasikan dalam kustomization.yaml.
Contoh di bawah ini menambahkan jumlah replika dari objek Deployment yang bisa juga dilakukan melalui patchesJson6902.
Selain patch, Kustomize juga menyediakan cara untuk melakukan kustomisasi image Container atau memasukkan nilai field dari objek lainnya ke dalam Container tanpa membuat patch. Sebagai contoh, kamu dapat melakukan kustomisasi image yang digunakan di dalam Container dengan menyebutkan spesifikasi fieldimages di dalam kustomization.yaml.
Terkadang, aplikasi yang berjalan di dalam Pod perlu untuk menggunakan nilai konfigurasi dari objek lainnya.
Contohnya, sebuah Pod dari objek Deployment perlu untuk membaca nama Service dari Env atau sebagai argumen perintah.
Ini karena nama Service bisa saja berubah akibat dari penambahan namePrefix atau nameSuffix pada berkas kustomization.yaml.
Kami tidak menyarankan kamu untuk meng-hardcode nama Service di dalam argumen perintah.
Untuk penggunaan ini, Kustomize dapat memasukkan nama Service ke dalam Container melalui vars.
Kustomize memiliki konsep base dan overlay. base merupakan direktori dengan kustomization.yaml, yang berisi
sekumpulan sumber daya dan kustomisasi yang terkait. base dapat berupa direktori lokal maupun direktori dari repo remote,
asalkan berkas kustomization.yaml ada di dalamnya. overlay merupakan direktori dengan kustomization.yaml yang merujuk pada
direktori kustomization lainnya sebagai base-nya. base tidak memiliki informasi tentang overlay. dan dapat digunakan pada beberapa overlay sekaligus.
overlay bisa memiliki beberapa base dan terdiri dari semua sumber daya yang berasal dari base yang juga dapat memiliki kustomisasi lagi di atasnya.
Contoh di bawah ini memperlihatkan kegunaan dari base:
# Membuat direktori untuk menyimpan base
mkdir base
# Membuat base/deployment.yaml
cat <<EOF > base/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
EOF# Membuat berkas base/service.yaml
cat <<EOF > base/service.yaml
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
ports:
- port: 80
protocol: TCP
selector:
run: my-nginx
EOF# Membuat berkas base/kustomization.yaml
cat <<EOF > base/kustomization.yaml
resources:
- deployment.yaml
- service.yaml
EOF
base ini dapat digunakan di dalam beberapa overlay sekaligus. Kamu dapat menambahkan namePrefix yang berbeda ataupun
field lainnya yang bersinggungan di dalam overlay berbeda. Di bawah ini merupakan dua buah overlay yang menggunakan base yang sama.
Cara menerapkan/melihat/menghapus objek menggunakan Kustomize
Gunakan --kustomize atau -k di dalam perintah kubectl untuk mengenali sumber daya yang dikelola oleh kustomization.yaml.
Perhatikan bahwa -k harus merujuk pada direktori kustomization, misalnya:
Jalankan perintah di bawah ini untuk menerapkan objek Deployment dev-my-nginx:
> kubectl apply -k ./
deployment.apps/dev-my-nginx created
Jalankan perintah di bawah ini untuk melihat objek Deployment dev-my-nginx:
kubectl get -k ./
kubectl describe -k ./
Jalankan perintah di bawah ini untuk membandingkan objek Deployment dev-my-nginx dengan kondisi yang diinginkan pada klaster jika manifes telah berhasil diterapkan:
kubectl diff -k ./
Jalankan perintah di bawah ini untuk menghapus objek Deployment dev-my-nginx:
5.3 - Pengelolaan Objek Kubernetes dengan Perintah Imperatif
Objek-objek Kubernetes bisa dibuat, diperbarui, dan dihapus secara langsung dengan menggunakan perintah-perintah imperatif yang ada pada command-linekubectl. Dokumen ini menjelaskan cara perintah-perintah tersebut diorganisir dan cara menggunakan perintah-perintah tersebut untuk mengelola objek live.
Kelebihan dan kekurangan
Perintah kubectl mendukung tiga cara pengelolaan objek:
Perintah imperatif
Konfigurasi objek imperatif
Konfigurasi objek deklaratif
Lihat Pengelolaan Objek Kubernetes untuk mengenali lebih lanjut kelebihan dan kekurangan dari tiap pengelolaan objek.
Cara membuat objek
Perangkat kubectl mendukung perintah-perintah berbentuk kata kerja untuk membuat beberapa tipe objek yang paling umum. Perintah-perintah tersebut diberi nama yang mudah dikenali oleh pengguna yang belum familiar dengan tipe-tipe objek Kubernetes.
run: Membuat sebuah objek Deployment untuk menjalankan kontainer di satu atau lebih Pod.
expose: Membuat sebuah objek Service untuk mengatur lalu lintas beban antar Pod.
autoscale: Membuat sebuah objek Autoscaler untuk melakukan scaling horizontal secara otomatis terhadap sebuah objek controller, misalnya sebuah objek Deployment.
Perangkat kubectl juga mendukung perintah-perintah pembuatan objek yang berdasarkan pada tipe objek. Perintah-perintah ini mendukung lebih banyak tipe objek dan lebih eksplisit tentang intensi mereka. Tapi, perintah-perintah ini memerlukan pengguna untuk memahami tipe dari objek-objek yang hendak mereka buat.
create <objecttype> [<subtype>] <instancename>
Beberapa tipe objek memiliki sub tipe yang bisa kamu spesifikasikan pada perintah create. Misalnya, objek Service memiliki beberapa sub tipe seperti ClusterIP, LoadBalancer, dan NodePort. Berikut adalah sebuah contoh cara membuat sebuah Service dengan sub tipe NodePort:
kubectl create service nodeport <myservicename>
Pada contoh di atas, perintah create service nodeport merupakan sub perintah dari create service.
Kamu bisa menggunakan parameter -h untuk mencari argumen-argumen dan paramenter-parameter yang didukung oleh sebuah sub perintah:
kubectl create service nodeport -h
Cara memperbarui objek
Perintah kubectl mendukung perintah-perintah berbasis kata kerja untuk beberapa operasi pembaruan yang umum. Perintah-perintah ini diberi nama yang memudahkan pengguna yang belum familiar dengan objek-objek Kubernetes untuk melakukan pembaruan tanpa terlebih dulu mengetahui field-field spesifik yang harus diperbarui:
scale: Melakukan scaling horizontal terhadap sebuah controller untuk menambah atau menghapus Pod dengan memperbarui jumlah replika dari controller tersebut.
annotate: Menambah atau menghapus anotasi sebuah objek.
label: Menambah atau menghapus label sebuah objek.
Perintah kubectl juga mendukung perintah-perintah pembaruan berdasarkan salah satu aspek dari sebuah objek. Untuk tiap tipe objek yang berbeda, memperbarui sebuah aspek tertentu bisa berarti memperbarui sekumpulan field yang berbeda pula:
set<field>: Memperbarui salah satu aspek dari sebuah objek.
Catatan: Pada Kubernetes versi 1.5, tidak semua perintah yang berdasarkan kata kerja berasosiasi dengan perintah yang berdasarkan aspek tertentu.
Perangkat kubectl juga mendukung beberapa cara lain untuk memperbarui objek live secara langsung, meskipun cara-cara berikut membutuhkan pemahaman yang lebih tentang skema objek Kubernetes.
edit: Secara langsung mengedit konfigurasi mentah dari sebuah objek live dengan membuka konfigurasinya di sebuah editor.
patch: Secara langsung memodifikasi field-field spesifik dari sebuah objek live dengan menggunakan patch string. Untuk detil lebih lanjut mengenai patch string, lihat bagian tentang patch pada Konvensi API.
Cara menghapus objek
Kamu bisa menggunakan perintah delete pada sebuah objek dari sebuah klaster:
delete <type>/<name>
Catatan: Kamu bisa menggunakan kubectl delete baik untuk perintah imperatif maupun konfigurasi objek imperatif. Perbedaannya hanya pada argumen yang diberikan ke perintah tersebut. Untuk menggunakan kubectl delete sebagai perintah imperatif, argumen yang diberikan adalah objek yang hendak dihapus. Berikut adalah sebuah contoh perintah kubectl delete dengan sebuah objek Deployment bernama nginx sebagai argumen:
kubectl delete deployment/nginx
Cara melihat objek
Ada beberapa perintah untuk menampilkan informasi tentang sebuah objek:
get: Menampilkan informasi dasar dari objek-objek yang sesuai dengan parameter dari perintah ini. Gunakan get -h untuk melihat daftar opsi yang bisa digunakan.
describe: Menampilkan agregat informasi detil dari objek-objek yang sesuai dengan parameter dari perintah ini.
logs: Menampilkan isi stdout dan stderr dari sebuah kontainer yang berjalan di sebuah Pod.
Menggunakan perintah set untuk memodifikasi objek sebelum dibuat
Ada beberapa field objek yang tidak memiliki parameter yang bisa kamu gunakan pada perintah create. Pada kasus-kasus tersebut, kamu bisa menggunakan kombinasi dari perintah set dan create untuk menspesifikasikan nilai untuk field-field tersebut sebelum objek dibuat. Ini dilakukan dengan melakukan piping pada hasil dari perintah create ke perintah set, dan kemudian mengembalikan hasilnya ke perintah create. Simak contoh berikut:
Perintah kubectl create service -o yaml --dry-run membuat konfigurasi untuk sebuah Service, tapi kemudian menuliskan konfigurasi tadi ke stdout dalam format YAML alih-alih mengirimnya ke API Server Kubernetes.
Perintah kubectl set selector --local -f - -o yaml membaca konfigurasi dari stdin, dan menuliskan pembaruan konfigurasi ke stdout dalam format YAML.
Perintah kubectl create -f - membuat objek dengan menggunakan konfigurasi yang disediakan pada stdin.
Menggunakan --edit untuk memodifikasi objek sebelum dibuat
Kamu bisa menggunakan perintah kubectl create --edit untuk membuat perubahan terhadap sebuah objek sebelum objek tersebut dibuat. Simak contoh berikut:
5.4 - Pengelolaan Objek Kubernetes Secara Imperatif dengan Menggunakan File Konfigurasi
Objek-objek Kubernetes bisa dibuat, diperbarui, dan dihapus dengan menggunakan perangkat command-linekubectl dan file konfigurasi objek yang ditulis dalam format YAML atau JSON. Dokumen ini menjelaskan cara mendefinisikan dan mengelola objek dengan menggunakan file konfigurasi.
Kelebihan dan kekurangan
Perintah kubectl mendukung tiga cara pengelolaan objek:
Perintah imperatif
Konfigurasi objek imperatif
Konfigurasi objek deklaratif
Lihat Pengelolaan Objek Kubernetes untuk mengenali lebih lanjut kelebihan dan kekurangan dari tiap cara pengelolaan objek.
Cara membuat objek
Kamu bisa menggunakan perintah kubectl create -f untuk membuat sebuah objek dari sebuah file konfigurasi. Rujuk dokumen referensi API Kubernetes untuk detil lebih lanjut.
kubectl create -f <nama-file|url>
Cara memperbarui objek
Peringatan: Memperbarui objek dengan perintah replace akan menghilangkan semua bagian dari spesifikasi objek yang tidak dispesifikasikan pada file konfigurasi. Oleh karena itu, perintah ini sebaiknya tidak digunakan terhadap objek-objek yang spesifikasinya sebagian dikelola oleh klaster, misalnya Service dengan tipe LoadBalancer, di mana fieldexternalIPs dikelola secara terpisah dari file konfigurasi. Field-field yang dikelola secara terpisah harus disalin ke file konfigurasi untuk mencegah terhapus oleh perintah replace.
Kamu bisa menggunakan perintah kubectl replace -f untuk memperbarui sebuah objek live sesuai dengan sebuah file konfigurasi.
kubectl replace -f <nama-file|url>
Cara menghapus objek
Kamu bisa menggunakan perintah kubectl delete -f untuk menghapus sebuah objek yang dideskripsikan pada sebuah file konfigurasi.
kubectl delete -f <nama-file|url>
Cara melihat objek
Kamu bisa menggunakan perintah kubectl get -f untuk melihat informasi tentang sebuah objek yang dideskripsikan pada sebuah file konfigurasi.
kubectl get -f <nama-file|url> -o yaml
Parameter -o yaml menetapkan bahwa keseluruhan konfigurasi objek ditulis ke file yaml. Gunakan perintah kubectl get -h untuk melihat daftar pilihan selengkapnya.
Keterbatasan
Perintah-perintah create, replace, dan delete bekerja dengan baik saat tiap konfigurasi dari sebuah objek didefinisikan dan dicatat dengan lengkap pada file konfigurasi objek tersebut. Akan tetapi, ketika sebuah objek live diperbarui dan pembaruannya tidak dicatat di file konfigurasinya, pembaruan tersebut akan hilang ketika perintah replace dieksekusi di waktu berikutnya. Ini bisa terjadi saat sebuah controller, misalnya sebuah HorizontalPodAutoscaler, membuat pembaruan secara langsung ke sebuah objek live. Berikut sebuah contoh:
Kamu membuat sebuah objek dari sebuah file konfigurasi.
Sebuah sumber lain memperbarui objek tersebut dengan mengubah beberapa field.
Kamu memperbarui objek tersebut dengan kubectl replace dari file konfigurasi. Perubahan yang dibuat dari sumber lain pada langkah nomor 2 di atas akan hilang.
Jika kamu perlu mendukung beberapa writer untuk objek yang sama, kamu bisa menggunakan kubectl apply untuk mengelola objek tersebut.
Membuat dan mengedit objek dari URL tanpa menyimpan konfigurasinya
Misalkan kamu memiliki URL dari sebuah file konfigurasi objek. Kamu bisa menggunakan kubectl create --edit untuk membuat perubahan pada konfigurasi sebelum objek tersebut dibuat. Langkah ini terutama berguna untuk mengikuti tutorial atau untuk pekerjaan-pekerjaan yang menggunakan sebuah file konfigurasi di URL terentu yang perlu dimodifikasi.
kubectl create -f <url> --edit
Migrasi dari perintah imperatif ke konfigurasi objek imperatif
Migrsasi dari perintah imperatif ke konfigurasi objek imperatif melibatkan beberapa langkah manual.
Ekspor objek live ke sebuah file konfigurasi objek lokal:
kubectl get <kind>/<name> -o yaml --export > <kind>_<name>.yaml
Hapus secara manual field status dari file konfigurasi objek.
Untuk pengelolaan objek selanjutnya, gunakan perintah replace secara eksklusif.
kubectl replace -f <kind>_<name>.yaml
Mendefinisikan controller selectors dan label PodTemplate
Peringatan: Memperbarui selectors pada controllers sangat tidak disarankan.
Pendekatan yang direkomendasikan adalah mendefinisikan sebuah label PodTemplate tunggal dan immutable yang hanya digunakan oleh controller selector tersebut, tanpa makna semantik lainnya.
6.1 - Mendefinisikan Perintah dan Argumen untuk sebuah Kontainer
Laman ini menunjukkan bagaimana cara mendefinisikan perintah-perintah
dan argumen-argumen saat kamu menjalankan Container
dalam sebuah Pod.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Mendefinisikan sebuah perintah dan argumen-argumen saat kamu membuat sebuah Pod
Saat kamu membuat sebuah Pod, kamu dapat mendefinisikan sebuah perintah dan argumen-argumen untuk
Container-Container yang berjalan di dalam Pod. Untuk mendefinisikan sebuah perintah, sertakan
bidang command di dalam berkas konfigurasi. Untuk mendefinisikan argumen-argumen untuk perintah, sertakan
bidang args di dalam berkas konfigurasi. Perintah dan argumen-argumen yang telah
kamu definisikan tidak dapat diganti setelah Pod telah terbuat.
Perintah dan argumen-argumen yang kamu definisikan di dalam berkas konfigurasi
membatalkan perintah dan argumen-argumen bawaan yang disediakan oleh image Container.
Jika kamu mendefinisikan argumen-argumen, tetapi tidak mendefinisikan sebuah perintah, perintah bawaan digunakan
dengan argumen-argumen baru kamu.
Catatan: Bidang command menyerupai entrypoint di beberapa runtime Container.
Merujuk pada catatan di bawah.
Pada latihan ini, kamu akan membuat sebuah Pod baru yang menjalankan sebuah Container. Berkas konfigurasi
untuk Pod mendefinisikan sebuah perintah dan dua argumen:
Keluaran menunjukkan bahwa Container yang berjalan di dalam Pod command-demo
telah selesai.
Untuk melihat keluaran dari perintah yang berjalan di dalam Container, lihat log
dari Pod tersebut:
kubectl logs command-demo
Keluaran menunjukan nilai dari variabel lingkungan HOSTNAME dan KUBERNETES_PORT:
command-demo
tcp://10.3.240.1:443
Menggunakan variabel lingkungan untuk mendefinisikan argumen
Dalam contoh sebelumnya, kamu mendefinisikan langsung argumen-argumen dengan
menyediakan string. Sebagai sebuah alternatif untuk menyediakan string secara langsung,
kamu dapat mendefinisikan argumen-argumen dengan menggunakan variabel lingkungan:
Ini berarti kamu dapat mendefinisikan sebuah argumen untuk sebuah Pod menggunakan
salah satu teknik yang tersedia untuk mendefinisikan variabel-variabel lingkungan, termasuk
ConfigMap
dan
Secret.
Catatan: Variabel lingkugan muncul dalam tanda kurung, "$(VAR)". Ini
dibutuhkan untuk variabel yang akan diperuluas di bidang command atau args.
Menjalankan sebuah perintah di dalam shell
Di beberapa kasus, kamu butuh perintah untuk menjalankan sebuah shell. Contohnya,
perintah kamu mungkin terdiri dari beberapa perintah yang digabungkan, atau mungkin berupa
skrip shell. Untuk menjalankan perintah kamu di sebuah shell, bungkus seperti ini:
Tabel ini merangkum nama-nama bidang yang digunakan oleh Docker dan Kubernetes.
Deskripsi
Nama bidang pada Docker
Nama bidang pada Kubernetes
Perintah yang dijalankan oleh Container
Entrypoint
command
Argumen diteruskan ke perintah
Cmd
args
Saat kamu mengesampingkan Entrypoint dan Cmd standar,
aturan-aturan ini berlaku:
Jika kamu tidak menyediakan command atau args untuk sebuah Container,
maka command dan args yang didefinisikan di dalam image Docker akan digunakan.
Jika kamu menyediakan command tetapi tidak menyediakan args untuk sebuah Container, akan digunakan
command yang disediakan. Entrypoint dan Cmd bawaan yang didefinisikan di dalam
image Docker diabaikan.
Jika kamu hanya menyediakan args untuk sebuah Container, Entrypoint bawaan yang didefinisikan di dalam
image Docker dijalakan dengan args yang kamu sediakan.
Jika kamu menyediakan command dan args, Entrypoint dan Cmd standar yang didefinisikan
di dalam image Docker diabaikan. command kamu akan dijalankan dengan args kamu.
6.2 - Mendefinisikan Variabel Lingkungan untuk sebuah Kontainer
Laman ini menunjukkan bagaimana cara untuk mendefinisikan variabel lingkungan (environment variable) untuk sebuah Container di dalam sebuah Pod Kubernetes.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Mendefinisikan sebuah variabel lingkungan untuk sebuah Container
Ketika kamu membuat sebuah Pod, kamu dapat mengatur variabel lingkungan untuk Container-Container yang berjalan di dalam sebuah Pod.
Untuk mengatur variabel lingkungan, sertakan bagian env atau envFrom pada berkas konfigurasi.
Dalam latihan ini, kamu membuat sebuah Pod yang menjalankan satu buah Container.
Berkas konfigurasi untuk Pod tersebut mendefinisikan sebuah variabel lingkungan dengan nama DEMO_GREETING yang bernilai "Hello from the environment".
Berikut berkas konfigurasi untuk Pod tersebut:
apiVersion:v1kind:Podmetadata:name:envar-demolabels:purpose:demonstrate-envarsspec:containers:- name:envar-demo-containerimage:gcr.io/google-samples/node-hello:1.0env:- name:DEMO_GREETINGvalue:"Hello from the environment"- name:DEMO_FAREWELLvalue:"Such a sweet sorrow"
Buatlah sebuah Pod berdasarkan berkas konfigurasi YAML tersebut:
NAME READY STATUS RESTARTS AGE
envar-demo 1/1 Running 0 9s
Dapatkan sebuah shell ke Container yang sedang berjalan di Pod kamu:
kubectl exec -it envar-demo -- /bin/bash
Di shell kamu, jalankan perintah printenv untuk melihat daftar variabel lingkungannya.
root@envar-demo:/# printenv
Keluarannya mirip seperti ini:
NODE_VERSION=4.4.2
EXAMPLE_SERVICE_PORT_8080_TCP_ADDR=10.3.245.237
HOSTNAME=envar-demo
...
DEMO_GREETING=Hello from the environment
DEMO_FAREWELL=Such a sweet sorrow
Untuk keluar dari shell tersebut, masukkan perintah exit.
Catatan: Variabel-variabel lingkungan yang diatur menggunakan bagian env atau envFrom akan mengesampingkan
variabel-variabel lingkungan yang ditentukan di dalam image kontainer.
Menggunakan variabel-variabel lingkungan di dalam konfigurasi kamu
Variabel-variabel lingkungan yang kamu definisikan di dalam sebuah konfigurasi Pod dapat digunakan di tempat lain dalam konfigurasi, contohnya di dalam perintah-perintah dan argumen-argumen yang kamu atur dalam Container-Container milik Pod.
Pada contoh konfigurasi berikut, variabel-variabel lingkungan GREETING, HONORIFIC, dan NAME disetel masing-masing menjadi Warm greetings to, The Most Honorable, dan Kubernetes.
Variabel-variabel lingkungan tersebut kemudian digunakan dalam argumen CLI yang diteruskan ke Container env-print-demo.
6.3 - Mendistribusikan Kredensial dengan Aman Menggunakan Secret
Laman ini menjelaskan bagaimana cara menginjeksi data sensitif, seperti kata sandi (password) dan kunci enkripsi, ke dalam Pod.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Mengubah data rahasia kamu ke dalam representasi Base64
Misalnya kamu mempunyai dua buah data rahasia: sebuah nama pengguna my-app dan kata sandi
39528$vdg7Jb. Pertama, gunakan alat penyandian Base64 untuk mengubah nama pengguna kamu dan kata sandi ke dalam representasi Base64. Berikut ini contoh menggunakan program Base64 yang umum digunakan:
Hasil keluaran menampilkan representasi Base64 dari nama pengguna kamu yaitu bXktYXBw,
dan representasi Base64 dari kata sandi kamu yaitu Mzk1MjgkdmRnN0pi.
Perhatian: Gunakan alat yang telah dipercayai oleh OS kamu untuk menghindari risiko dari penggunaan alat eksternal.
Membuat Secret
Berikut ini adalah berkas konfigurasi yang dapat kamu gunakan untuk membuat Secret yang akan menampung nama pengguna dan kata sandi kamu:
Jika kamu ingin melompati langkah penyandian dengan Base64, kamu dapat langsung membuat Secret yang sama dengan menggunakan perintah kubectl create secret. Contohnya:
Tentu saja ini lebih mudah. Pendekatan yang mendetil setiap langkah di atas bertujuan untuk mendemonstrasikan apa yang sebenarnya terjadi pada setiap langkah.
Membuat Pod yang memiliki akses ke data Secret melalui Volume
Berikut ini adalah berkas konfigurasi yang dapat kamu gunakan untuk membuat Pod:
apiVersion:v1kind:Podmetadata:name:secret-test-podspec:containers:- name:test-containerimage:nginxvolumeMounts:# nama harus sesuai dengan nama Volume di bawah ini- name:secret-volumemountPath:/etc/secret-volume# Data Secret diekspos ke Container di dalam Pod melalui Volumevolumes:- name:secret-volumesecret:secretName:test-secret
Gunakan envFrom untuk mendefinisikan semua data Secret sebagai variabel lingkungan Container. Key dari Secret akan mennjadi nama variabel lingkungan di dalam Pod.
Menjalankan dan mengatur aplikasi stateless dan stateful.
7.1 - Menjalankan Aplikasi Stateless Menggunakan Deployment
Dokumen ini menunjukkan cara bagaimana cara menjalankan sebuah aplikasi menggunakan objek Deployment Kubernetes.
Tujuan
Membuat sebuah Deployment Nginx.
Menggunakan kubectl untuk mendapatkan informasi mengenai Deployment.
Mengubah Deployment.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Kubernetes servermu harus dalam versi yang sama atau lebih baru dari v1.9.
Untuk melihat versi, tekan kubectl version.
Membuat dan Menjelajahi Deployment Nginx
Kamu dapat menjalankan aplikasi dengan membuat sebuah objek Deployment Kubernetes, dan kamu
dapat mendeskripsikan sebuah Deployment di dalam berkas YAML. Sebagai contohnya, berkas
YAML berikut mendeskripsikan sebuah Deployment yang menjalankan image Docker nginx:1.14.2:
apiVersion:apps/v1# for versions before 1.9.0 use apps/v1beta2kind:Deploymentmetadata:name:nginx-deploymentspec:selector:matchLabels:app:nginxreplicas:2# tells deployment to run 2 pods matching the templatetemplate:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.7.9ports:- containerPort:80
Buatlah sebuah Deployment berdasarkan berkas YAML:
Name: nginx-deployment
Namespace: default
CreationTimestamp: Tue, 30 Aug 2016 18:11:37 -0700
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=1
Selector: app=nginx
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.14.2
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-1771418926 (2/2 replicas created)
No events.
Lihatlah daftar Pod-Pod yang dibuat oleh Deployment:
kubectl get pods -l app=nginx
Keluaran dari perintah tersebut akan menyerupai:
NAME READY STATUS RESTARTS AGE
nginx-deployment-1771418926-7o5ns 1/1 Running 0 16h
nginx-deployment-1771418926-r18az 1/1 Running 0 16h
Tampilkan informasi mengenai Pod:
kubectl describe pod <nama-pod>
dimana <nama-pod> merupakan nama dari Pod kamu.
Mengubah Deployment
Kamu dapat mengubah Deployment dengan cara mengaplikasikan berkas YAML yang baru.
Berkas YAML ini memberikan spesifikasi Deployment untuk menggunakan Nginx versi 1.16.1.
apiVersion:apps/v1# untuk versi sebelum 1.9.0 gunakan apps/v1beta2kind:Deploymentmetadata:name:nginx-deploymentspec:selector:matchLabels:app:nginxreplicas:2template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.16.1# Memperbarui versi nginx dari 1.14.2 ke 1.16.1ports:- containerPort:80
Perhatikan bahwa Deployment membuat Pod-Pod dengan nama baru dan menghapus Pod-Pod lama:
kubectl get pods -l app=nginx
Meningkatkan Jumlah Aplikasi dengan Meningkatkan Ukuran Replika
Kamu dapat meningkatkan jumlah Pod di dalam Deployment dengan menerapkan
berkas YAML baru. Berkas YAML ini akan meningkatkan jumlah replika menjadi 4,
yang nantinya memberikan spesifikasi agar Deployment memiliki 4 buah Pod.
apiVersion:apps/v1# untuk versi sebelum 1.9.0 gunakan apps/v1beta2kind:Deploymentmetadata:name:nginx-deploymentspec:selector:matchLabels:app:nginxreplicas:4# Memperbarui replica dari 2 menjadi 4template:metadata:labels:app:nginxspec:containers:- name:nginximage:nginx:1.14.2ports:- containerPort:80
Verifikasi Deployment kamu saat ini yang memiliki empat Pod:
kubectl get pods -l app=nginx
Keluaran dari perintah tersebut akan menyerupai:
NAME READY STATUS RESTARTS AGE
nginx-deployment-148880595-4zdqq 1/1 Running 0 25s
nginx-deployment-148880595-6zgi1 1/1 Running 0 25s
nginx-deployment-148880595-fxcez 1/1 Running 0 2m
nginx-deployment-148880595-rwovn 1/1 Running 0 2m
Menghapus Deployment
Menghapus Deployment dengan nama:
kubectl delete deployment nginx-deployment
Cara Lama Menggunakan: ReplicationController
Cara yang dianjurkan untuk membuat aplikasi dengan replika adalah dengan menggunakan Deployment,
yang nantinya akan menggunakan ReplicaSet. Sebelum Deployment dan ReplicaSet ditambahkan
ke Kubernetes, aplikasi dengan replika dikonfigurasi menggunakan ReplicationController.
Laman ini menjelaskan bagaimana cara menghapus Pod yang menjadi bagian dari sebuah stateful set, dan menjelaskan pertimbangan yang harus diperhatikan saat melakukannya.
Sebelum kamu memulai
Ini merupakan tugas yang cukup rumit dan memiliki potensi melanggar beberapa properti yang melekat dari StatefulSet.
Sebelum melanjutkan, pastikan kamu paham dengan pertimbangan yang disebutkan di bawah ini.
Pertimbangan StatefulSet
Pada operasi normal dari StatefulSet, tidak pernah ada kebutuhan untuk menghapus paksa sebuah Pod StatefulSet. Controller StatefulSet bertanggung jawab terhadap pembuatan, penyekalaan dan penghapusan terhadap anggota dari StatefulSet. Controller akan berusaha menjaga agar jumlah Pod yang ditentukan dari 0 hingga N-1 hidup dan siap sedia. StatefulSet memastikan bahwa, pada waktu kapanpun, akan ada minimal satu Pod dengan identitas yang telah ditetapkan berjalan pada klaster. Hal ini direferensikan sebagai semantik at most one yang disediakan StatefulSet.
Penghapusan paksa secara manual harus dilakukan dengan hati-hati, karena hal tersebut berpotensi melanggar semantik at most one yang melekat pada StatefulSet. StatefulSet dapat digunakan untuk menjalankan aplikasi terklaster dan terdistribusi yang membutuhkan identitas jaringan dan penyimpanan yang stabil dan tetap. Aplikasi-aplikasi ini biasanya memiliki konfigurasi yang tergantung dengan sejumlah anggota dengan identitas yang tetap. Memiliki banyak anggota dengan identitas yang sama berpotensi menimbulkan kerusakan dan kehilangan data (contohnya skenario split brain pada sistem berbasis kuorum).
Menghapus Pod
Kamu dapat melakukan penghapusan Pod secara graceful dengan perintah berikut:
kubectl delete pods <pod>
Agar perintah di atas mengarah ke terminasi secara graceful, Pod tidak boleh menspesifikasikan pod.Spec.TerminationGracePeriodSeconds dengan nilai 0. Praktik untuk mengatur nilai pod.Spec.TerminationGracePeriodSeconds menjadi 0 detik merupakan hal yang tidak aman dan sangat tidak disarankan untuk Pod StatefulSet. Penghapusan secara graceful itu aman dan akan memastikan bahwa Pod akan mati secara gracefully sebelum kubelet menghapus nama dari apiserver.
Kubernetes (versi 1.5 atau lebih baru) tidak akan menghapus Pod hanya karena Node tidak dapat dijangkau. Pod yang berjalan pada Node yang tidak dapat dijangkau akan memasuki keadaan 'Terminating' atau 'Unknown' setelah waktu habis. Pod juga dapat memasuki keadaan ini saat pengguna berusaha melakukan penghapusan secara graceful terhadap Pod pada Node yang tidak dapat dijangkau. Cara yang hanya dapat dilakukan untuk menghapus Pod pada keadaan tersebut dari apiserver adalah:
Objek Node telah dihapus (baik oleh kamu, atau oleh Controller Node).
Kubelet pada Node yang tidak responsif akan menanggapi, lalu mematikan Pod dan menghapusnya dari apiserver.
Penghapusan paksa Pod oleh pengguna.
Praktik terbaik yang direkomendasikan adalah menggunakan pendekatan pertama atau kedua. Jika sebuah Node telah terkonfirmasi mati (contohnya terputus dari jaringan secara permanen, dimatikan, dll), maka objek Node dihapus. Jika Node mengalami partisi jaringan, maka coba selesaikan masalah ini atau menunggu masalah itu terselesaikan. Saat partisi terselesaikan, kubelet akan menyelesaikan penghapusan Pod serta membebaskan namanya dari apiserver.
Normalnya, sistem akan menyelesaikan penghapusan saat Pod tidak lagi berjalan pada Node, atau Node telah dihapus oleh administrator. Kamu dapat mengabaikan hal ini dengan menghapus paksa Pod.
Penghapusan Paksa
Penghapusan paksa tidak menunggu konfirmasi dari kubelet bahwa Pod telah diterminasi. Terlepas dari apakah penghapusan paksa sukses mematikan sebuah Pod, namanya akan segera dibebaskan dari apiserver. Hal ini berakibat controller StatefulSet akan membuat Pod pengganti dengan identitas yang sama; ini dapat menimbulkan duplikasi terhadap Pod apabila ternyata Pod tersebut masih berjalan, dan jika Pod tersebut masih dapat berkomunikasi dengan anggota Statefulset lainnya, hal ini berakibat terjadi pelanggaran semantik at most one dari StatefulSet yang telah dijamin.
Saat kamu menghapus paksa sebuah Pod StatefulSet, berarti kamu menjamin bahwa Pod tersebut tidak akan pernah lagi berkomunikasi dengan Pod lain pada StatefulSet dan namanya dapat dibebaskan secara aman untuk pembuatan penggantinya.
Jika kamu ingin menghapus paksa Pod dengan menggunakan kubectl versi >= 1.5, lakukan perintah berikut:
HorizontalPodAutoscaler secara otomatis akan memperbanyak jumlah Pod di dalam ReplicationController, Deployment,
ReplicaSet ataupun StatefulSet berdasarkan hasil observasi penggunaan CPU(atau, dengan
metrik khusus, pada beberapa aplikasi yang menyediakan metrik).
Perlu dicatat bahwa HorizontalPodAutoscale tidak dapat diterapkan pada objek yang tidak dapat diperbanyak, seperti DeamonSets.
HorizontalPodAutoscaler diimplementasikan sebagai Kubernetes API resource dan sebuah controller.
Resource tersebut akan menentukan perilaku dari controller-nya.
Kontroler akan mengubah jumlah replika pada ReplicationController atau pada Deployment untuk menyesuaikan dengan hasil observasi rata-rata
penggunaan CPU sesuai dengan yang ditentukan oleh pengguna.
Bagaimana cara kerja HorizontalPodAutoscaler?
HorizontalPodAutoscaler diimplementasikan sebagai sebuah loop kontrol, yang secara
berkala dikontrol oleh flag--horizontal-pod-autoscaler-sync-period pada controller manager
(dengan nilai bawaan 15 detik).
Dalam setiap periode, controller manager melakukan kueri penggunaan sumber daya dan membandingkan
dengan metrik yang dispesifikasikan pada HorizontalPodAutoscaler. Controller manager mendapat
metrik dari sumber daya metrik API (untuk metrik per Pod) atau dari API metrik khusus (untuk semua metrik lainnya).
Untuk metrik per Pod (seperti CPU), controller mengambil metrik dari sumber daya metrik API
untuk setiap Pod yang ditargetkan oleh HorizontalPodAutoscaler. Kemudian, jika nilai target penggunaan ditentukan,
maka controller akan menghitung nilai penggunaan sebagai persentasi dari pengguaan sumber daya dari Container
pada masing-masing Pod. Jika target nilai mentah (raw value) ditentukan, maka nilai metrik mentah (raw metric)
akan digunakan secara langsung. Controller kemudian mengambil nilai rata-rata penggunaan atau nilai mentah (tergantung
dengan tipe target yang ditentukan) dari semua Pod yang ditargetkan dan menghasilkan perbandingan yang
digunakan untuk menentukan jumlah replika yang akan diperbanyak.
Perlu dicatat bahwa jika beberapa Container pada Pod tidak memiliki nilai resource request, penggunaan CPU
pada Pod tersebut tidak akan ditentukan dan autoscaler tidak akan melakukan tindakan apapun untuk metrik tersebut.
Perhatikan pada bagian detail algoritma di bawah ini untuk informasi lebih lanjut mengenai
cara kerja algoritma autoscale.
Untuk metrik khusus per Pod, controller bekerja sama seperti sumber daya metrik per Pod,
kecuali Pod bekerja dengan nilai mentah, bukan dengan nilai utilisasi (utilization values).
Untuk objek metrik dan metrik eksternal, sebuah metrik diambil, dimana metrik tersebut menggambarkan
objek tersebut. Metrik ini dibandingkan dengan nilai target untuk menghasilkan perbandingan seperti di atas.
Pada API autoscaling/v2beta2, nilai perbandingan dapat secara opsional dibagi dengan jumlah Pod
sebelum perbandingan dibuat.
Pada normalnya, HorizontalPodAutoscaler mengambil metrik dari serangkaian API yang sudah diagregat
(custom.metric.k8s.io, dan external.metrics.k8s.io). API metrics.k8s.io biasanya disediakan oleh
metric-server, dimana metric-server dijalankan secara terpisah. Perhatikan
metrics-server sebagai petunjuk.
HorizontalPodAutoscaler juga mengambil metrik dari Heapster secara langsung.
Catatan:
FEATURE STATE:Kubernetes v1.11 [deprecated]
Pengambian metrik dari Heapster tidak didukung lagi pada Kubernetes versi 1.11.
Autoscaler mengkases controller yang dapat diperbanyak (seperti ReplicationController, Deployment, dan ReplicaSet)
dengan menggunakan scale sub-resource. Untuk lebih detail mengenai scale sub-resource dapat ditemukan
di sini.
Detail Algoritma
Dari sudut pandang paling sederhana, controller HorizontalPodAutoscaler mengoperasikan
perbandingan metrik yang diinginkan dengan kedaan metrik sekarang.
Sebagai contoh, jika nilai metrik sekarang adalah 200m dan nilai metrik yang
diinginkan adalah 100m, jumlah replika akan ditambah dua kali lipat,
karena 200.0 / 100.0 == 2.0. Jika nilai metrik sekarang adalah 50m,
maka jumlah replika akan dikurangi setengah, karena 50.0 / 100.0 == 0.5.
Kita tetap memperbanyak replika (scale) jika nilai perbandingan mendekati 1.0 (dalam toleransi yang
dapat dikonfigurasi secata global, dari flag--horizontal-pod-autoscaler-tolerance
dengan nilai bawaan 0.1.
Ketika targetAverageValue (nilai target rata-rata) atau targetAverageUtilization
(target penggunaan rata-rata) ditentukan, currentMetricValue (nilai metrik sekaraang)
dihitung dengan mengambil rata-rata dari metrik dari semua Pod yang ditargetkan oleh
HorizontalPodAutoscaler. Sebelum mengecek toleransi dan menentukan nilai akhir,
kita mengambil kesiapan Pod dan metrik yang hilang sebagai pertimbangan.
Semua Pod yang memiliki waktu penghapusan (Pod dalam proses penutupan)
dan semua Pod yang mengalami kegagalan akan dibuang.
Jika ada metrik yang hilang dari Pod, maka Pod akan dievaluasi nanti.
Pod dengan nilai metrik yang hilang akan digunakan untuk menyesuaikan
jumlah akhir Pod yang akan diperbanyak atau dikurangi.
Ketika scaling dilakukan karena CPU, jika terdapat Pod yang akan siap (dengan kata lain
Pod tersebut sedang dalam tahap inisialisasi) atau metrik terakhir dari Pod
adalah metrik sebelum Pod dalam keadaan siap, maka Pod tersebut juga
akan dievaluasi nantinya.
Akibat keterbatasan teknis, controller HorizontalPodAutoscaler tidak dapat
menentukan dengan tepat kapan pertama kali Pod akan dalam keadaan siap
ketika menentukan apakah metrik CPU tertentu perlu dibuang. Sebaliknya,
HorizontalPodAutoscaler mempertimbangkan sebuah Pod "tidak dalam keadaan siap"
jika Pod tersebut dalam keadaan tidak siap dan dalam transisi ke status tidak
siap dalam waktu singkat, rentang waktu dapat dikonfigurasi, sejak Pod tersebut dijalankan.
Rentang waktu tersebut dapat dikonfigurasi dengan flag--horizontal-pod-autoscaler-initial-readiness-delay
dan waktu bawaannya adalah 30 detik. Ketika suatu Pod sudah dalam keadaan siap,
Pod tersebut mempertimbangkan untuk siap menjadi yang pertama jika itu terjadi dalam
waktu yang lebih lama, rentang waktu dapat dikonfigurasi, sejak Pod tersebut dijalankan.
Rentang waktu tersebut dapat dikonfigurasi dengan flag--horizontal-pod-autoscaler-cpu-initialization-period
dan nilai bawaannya adalah 5 menit.
Skala perbandingan dasar currentMetricValue / desiredMetricValue
dihitung menggunakan Pod yang tersisa yang belum disisihkan atau dibuang dari
kondisi di atas.
Jika terdapat metrik yang hilang, kita menghitung ulang rata-rata dengan lebih
konservatif, dengan asumsi Pod mengkonsumsi 100% dari nilai yang diharapkan
jika jumlahnya dikurangi (scale down) dan 0% jika jumlahnya diperbanyak (scale up).
Ini akan mengurangi besarnya kemungkinan untuk scale.
Selanjutnya, jika terdapat Pod dalam keadaan tidak siap, dan kita akan
memperbanyak replikas (scale up) tanpa memperhitungkan metrik yang hilang atau Pod yang tidak dalam
keadaan siap, kita secara konservatif mengasumsikan Pod yang tidak dalam keadaan siap
mengkonsumsi 0% dari metrik yang diharapkan, akhirnya meredam jumlah replika yang diperbanyak (scale up).
Seteleh memperhitungkan Pod yang tidak dalam keadaan siap dan metrik yang hilang,
kita menghitung ulang menggunakan perbandingan. Jika perbandingan yang baru membalikkan
arah scale-nya atau masih di dalam toleransi, kita akan melakukan scale dengan tepat. Jika tidak,
kita menggunakan perbandingan yang baru untuk memperbanyak atau mengurangi jumlah replika.
Perlu dicatat bahwa nilai asli untuk rata-rata penggunaan dilaporkan kembali melalui
status HorizontalPodAutoscaler, tanpa memperhitungkan Pod yang tidak dalam keadaan siap atau
metrik yang hilang, bahkan ketika perbandingan yang baru digunakan.
Jika beberapa metrik ditentukan pada sebuah HorizontalPodAutoscaler, perhitungan
dilakukan untuk setiap metrik dan nilai replika terbesar yang diharapkan akan dipilih.
Jika terdapat metrik yang tidak dapat diubah menjadi jumlah replika yang diharapkan
(contohnya terdapat kesalahan ketika mengambil metrik dari API metrik) dan pengurangan replika
disarankan dari metrik yang dapat diambil, maka scaling akan diabaikan. Ini berarti
HorizontalPodAutoscaler masih mampu untuk memperbanyak replika jika satu atau lebih metrik
memberikan sebuah desiredReplicas lebih besar dari nilai yang sekarang.
Pada akhirnya, sebelum HorizontalPodAutoscaler memperbanyak target, rekomendasi scaling akan
dicatat. Controller mempertimbangkan semua rekomendasi dalam rentang waktu yang dapat
dikonfigurasi untuk memilih rekomendasi tertinggi. Nilai ini dapat dikonfigurasi menggunakan
flag--horizontal-pod-autoscaler-downscale-stabilization, dengan nilai bawaan
5 menit. Ini berarti pengurangan replika akan terjadi secara bertahap, untuk mengurangi dampak dari
perubahan nilai metrik yang cepat.
Objek API
HorizontalPodAutoscaler adalah sebuah API dalam grup autoscaling pada Kubernetes.
Versi stabil, yang hanya mendukung untuk autoscale CPU, dapat ditemukan pada versi
API autoscaling/v1.
Versi beta, yang mendukung untuk scaling berdasarkan memori dan metrik khusus,
dapat ditemukan pada autoscaling/v2beta2. Field yang baru diperkenalkan pada
autoscaling/v2beta2 adalah preserved sebagai anotasi ketika menggunakan autoscaling/v1.
Ketika kamu membuat sebuah HorizontalPodAutoscaler, pastikan nama yang ditentukan adalah valid
nama subdomain DNS.
Untuk lebih detail tentang objek API ini dapat ditemukan di
Objek HorizontalPodAutoscaler.
Dukungan untuk HorizontalPodAutoscaler pada kubectl
Seperti sumber daya API lainnya, HorizontalPodAutoscaler didukung secara bawaan oleh kubectl.
Kita dapat membuat autoscaler yang baru dengan menggunakan perintah kubectl create.
Kita dapat melihat daftar autoscaler dengan perintah kubectl get hpa dan melihat deskripsi
detailnya dengan perintah kubectl describe hpa. Akhirnya, kita dapat menghapus autoscaler
meggunakan perintah kubectl delete hpa.
Sebagai tambahan, terdapat sebuah perintah khusus kubectl autoscaler untuk mempermudah pembuatan
HorizontalPodAutoscaler. Sebagai contoh, mengeksekusi
kubectl autoscaler rs foo --min=2 --max=5 --cpu-percent=80 akan membuat sebuah autoscaler untuk
ReplicaSet foo, dengan target pengguaan CPU 80% dan jumlah replika antara 2 sampai dengan 5.
Dokumentasi lebih detail tentang kubectl autoscaler dapat ditemukan di
sini.
Autoscaling ketika Rolling Update
Saat ini, dimungkinkan untuk melakukan rolling update menggunakan objek Deployment, yang akan
mengatur ReplicaSet untuk kamu. HorizontalPodAutoscaler hanya mendukung pendekatan terakhir:
HorizontalPodAutoscaler terikat dengan objek Deployment, yang mengatur seberapa besar dari objek Deployment tersebut,
dan Deployment bertugas untuk mengatur besar dari ReplicaSet.
HorizontalPodAutoscaler tidak bekerja dengan rolling update yang menggunakan manipulasi
pada ReplicationContoller secara langsung, dengan kata lain kamu tidak bisa mengikat
HorizontalPodAutoscaler dengan ReplicationController dan melakukan rolling update.
Alasan HorizontalPodAutoscaler tidak bekerja ketika rolling update membuat ReplicationController
yang baru adalah HorizontalPodAutoscaler tidak akan terikat dengan ReplicationController yang baru tersebut.
Dukungan untuk Cooldown / Penundaan
Ketika mengolah scaleing dari sebuah grup replika menggunakan HorizonalPodAutoscaler,
jumlah replika dimungkinkan tetap berubah secara sering disebabkan oleh perubahan dinamis
dari metrik yang dievaluasi. Hal ini sering disebut dengan thrashing.
Mulai dari versi 1.6, operator klaster dapat mengatasi masalah ini dengan mengatur
konfigurasi HorizontalPodAutoscaler global sebagai flagkube-controller-manager.
Mulai dari versi 1.12, sebuah algoritma pembaruan baru menghilangkan kebutuhan terhadap
penundaan memperbanyak replika (upscale).
--horizontal-pod-autoscaler-downscale-stabilization: Nilai untuk opsi ini adalah
sebuah durasi yang menentukan berapa lama autoscaler menunggu sebelum operasi
pengurangan replika (downscale) yang lain dilakukan seteleh operasi sekarang selesai. Nilai bawaannya
adalah 5 menit (5m0s).
Catatan: Ketika mengubah nilai paramater ini, sebuah operator klaster sadar akan kemungkinan
konsekuensi. Jika waktu penundaan diset terlalu lama, kemungkinan akan membuat
HorizontalPodAutoscaler tidak responsif terharap perubahan beban kerja. Namun, jika
waktu penundaan diset terlalu cepat, kemungkinan replikasi akan trashing seperti
biasanya.
Dukungan untuk Beberapa Metrik
Kubernetes versi 1.6 menambah dukungan untuk scaling berdasarkan beberapa metrik.
Kamu dapat menggunakan API versi autoscaling/v2beta2 untuk menentukan beberapa metrik
yang akan digunakan HorizontalPodAutoscaler untuk menambah atau mengurangi jumlah replika.
Kemudian, controller HorizontalPodAutoscaler akan mengevaluasi setiap metrik dan menyarankan jenis
scaling yang baru berdasarkan metrik tersebut. Jumlah replika terbanyak akan digunakan untuk scale
yang baru.
Dukungan untuk Metrik Khusus
Catatan: Kubernetes versi 1.2 menambah dukungan alpha untuk melakukan scaling berdasarkan metrik
yang spesifik dengan aplikasi menggunakan anotasi khusus. Dukungan untuk anotasi ini
dihilangkan pada Kubernetes versi 1.6 untuk mendukung API autoscaling yang baru. Selama
cara lama untuk mendapatkan metrik khusus masih tersedia, metrik ini tidak akan tersedia untuk
digunakan oleh HorizontalPodAutoscaler dan anotasi sebelumnya untuk menentukan metrik khusus untuk
scaling tidak lagi digunakan oleh controller HorizontalPodAutscaler.
Kubernetes versi 1.6 menambah dukungan untuk menggunakan metrik khusus pada HorizontalPodAutoscaler.
Kamu dapat menambahkan metrik khusus untuk HorizontalPodAutoscaler pada API versi autoscaling/v2beta2.
Kubernetes kemudian memanggil API metrik khusus untuk mengambil nilai dari metrik khusus.
Secara standar, controller HorizontalPodAutoscaler mengambil metrik dari beberapa API. Untuk dapat
mengakses API ini, administrator klaster harus memastikan bahwa:
Untuk metrik sumber daya, ini adalah API metrics.k8s.io, pada umumnya disediakan oleh
metrics-server. API tersebut dapat
diaktifkan sebagai addon atau tambahan pada klaster.
Untuk metrik khusus, ini adalah API custom.metrics.k8s.io. API ini disediakan oleh API
adaptor server yang disediakan oleh vendor yang memberi solusi untuk metrik. Cek dengan
pipeline metrikmu atau daftar solusi yang sudah diketahui. Jika kamu ingin membuat sendiri, perhatikan
boilerplate berikut untuk memulai.
Untuk metrik eksternal, ini adalah API external.metrics.k8s.io. API ini mungkin disediakan oleh penyedia
metrik khusus diatas.
Nilai dari --horizontal-pod-autoscaler-use-rest-clients adalah true atau tidak ada. Ubah nilai tersebut menjadi
false untuk mengubah ke autoscaling berdasarkan Heapster, dimana ini sudah tidak didukung lagi.
Dukungan untuk Perilaku Scaling yang dapat Dikonfigurasi
Mulai dari versi v1.18, API v2beta2 mengizinkan perilaku scaling dapat
dikonfigurasi melalui fieldbehavior pada HorizontalPodAutoscaler. Perilaku scaling up dan scaling down
ditentukan terpisah pada fieldslaceUp dan fieldscaleDown, dibawah dari fieldbehavior.
Sebuah stabilisator dapat ditentukan untuk kedua arah scale untuk mencegah perubahan replika yang terlalu
berbeda pada target scaling. Menentukan scaling policies akan mengontrol perubahan replika
ketika scaling.
Scaling Policies
Satu atau lebih scaling policies dapat ditentukan pada fieldbehavior. Ketika beberapa
policies ditentukan, policy yang mengizinkan scale terbesar akan dipilih secara default.
Contoh berikut menunjukkan perilaku ketika mengurangi replika:
Ketika jumlah Pod lebih besar dari 40, policy kedua akan digunakan untuk scaling down.
Misalnya, jika terdapat 80 replika dan target sudah di scale down ke 10 replika, 8 replika
akan dikurangi pada tahapan pertama. Pada iterasi berikutnya, ketika jumlah replika adalah 72,
10% dari Pod adalah 7.2 tetapi akan dibulatkan menjadi 8. Dalam setiap iterasi pada controllerautoscaler jumlah Pod yang akan diubah akan dihitung ulang berdarkan jumlah replika sekarang.
Ketika jumlah replika dibawah 40, policy pertama (Pods) akan digunakan dan 4 replika akan dikurangi
dalam satu waktu.
periodSeconds menunjukkan berapa lama waktu pada iterasi terkhir untuk menunjukkan policy
mana yang akan digunakan. Policy pertama mengizinkan maksimal 4 replika di scale down
dalam satu menit. Policy kedua mengixinkan maksimal 10% dari total replika sekarang di
scale down dalam satu menit.
Pemilihan policy dapat diubah dengan menentukannya pada fieldselectPolicy untuk sebuah
arah scale (baik scale up ataupun scale down). Dengan menentukan nilai Min,
HorizontalPodAutoscaler akan memilih policy yang mengizinkan pergantian replika paling sedikit.
Dengan menuntukan nilai Disable, akan menghentikan scaling pada arah scale tersebut.
Jendela Stabilisasi
Jendela stabilisasi digunakan untuk membatasi perubahan replika yang terlalu drastis ketika
metrik yang digunakan untuk scaling tetap berubah-ubah. Jendela stabilisasi digunakan oleh
algoritma autoscaling untuk memperhitungkan jumlah replika yang diharapkan dari scaling
sebelumnya untuk mencengah *scaling. Berikut adalah contoh penggunaan jendela stabilisasi
pada scaleDown.
scaleDown:stabilizationWindowSeconds:300
Ketika metrik menandakan bahwa replika pada target akan dikurangi, algoritma akan memperhatikan
jumlah replika yang diharapkan sebelumnya dan menggunakan nilai terbesar dari interval
yang ditentukan. Pada contoh diatas, semua jumlah replika yang diharapkan pada 5 menit
yang lalu akan dipertimbangkan.
Perilaku Standar
Untuk menggunakan scaling khusus, tidak semua field perlu ditentukan. Hanta nilai yang
perlu diubah saja yang ditentukan. Nilai khusus ini akan digabungkan dengan nilai standar.
Berikut adalah nilai standar perilaku pada algoritma yang digunakan HorizontalPodAutoscaler.
Untuk scaleDown, nilai dari jendela stabilisasi adalah 300 detik (atau nilai dari
flag--horizontal-pod-autoscaler-downscale-stabilization jika ditentukan). Hanya terdapat
satu policy, yaitu mengizinkan menghapus 100% dari replika yang berjalan,
artinya target replikasi di scale ke jumlah replika minimum. Untuk scaleUp, tidak terdapat
jendela stabilisasi. Jika metrik menunjukkan bahwa replika pada target perlu diperbanyak, maka replika akan
diperbanyak di secara langsung. Untuk scaleUp terdapat dua policy, yaitu empat Pod atau 100% dari
replika yang berjalan akan ditambahkan setiap 15 detik sampai HorizontalPodAutoscaler
dalam keadaan stabil.
Contoh: Mengubah Jendela Stabiliasi pada field scaleDown
Untuk membuat jendela stabilisai untuk pengurangan replika selama satu menit, perilaku
berikut ditambahkan pada HorizontalPodAutoscaler.
behavior:scaleDown:stabilizationWindowSeconds:60
Contoh: Membatasi nilai scale down
Untuk membatasi total berapa Pod yang akan dihapus, 10% setiap menut, perilaku
berikut ditambahkan pada HorizontalPodAutoscaler.
Nilai Disable pada selectPolicy akan menonaktifkan scaling pada arah yang
ditentukan. Untuk mencegah pengurangan replika dapat menggunakan policy berikut.
HorizontalPodAutoscaler secara otomatis akan memperbanyak jumlah Pod di dalam ReplicationController, Deployment,
ReplicaSet ataupun StatefulSet berdasarkan hasil observasi penggunaan CPU (atau, dengan
metrik khusus, pada beberapa aplikasi yang menyediakan metrik).
Laman ini memandu kamu dengan contoh pengaktifan HorizontalPodAutoscaler untuk server php-apache. Untuk informasi lebih lanjut tentang perilaku HorizontalPodAutoscaler, lihat Petunjuk pengguna HorizontalPodAutoscaler.
Contoh dibawah ini membutuhkan klaster Kubernetes dan kubectl di versi 1.2 atau yang lebih baru yang sedang berjalan.
Server metrik sebagai pemantauan perlu diluncurkan di dalam sebuah klaster
untuk menyediakan metrik melalui metrik API sumber daya, karena HorizontalPodAutoscaler menggunakan API ini untuk mengumpulkan metrik. Petunjuk untuk menerapkan server metrik ada di repositori GitHub dari server metrik, jika kamu mengikuti petunjuk memulai panduan GCE,
metrik-pemantauan server akan diaktifkan secara default
Untuk menentukan beberapa metrik sumber daya untuk HorizontalPodAutoscaler, kamu harus memiliki klaster Kubernetes
dan kubectl di versi 1.6 atau yang lebih baru. Selanjutnya, untuk menggunakan metrik khusus, klaster kamu
harus dapat berkomunikasi dengan server API yang menyediakan API metrik khusus. Terakhir, untuk menggunakan metrik yang tidak terkait dengan objek Kubernetes apa pun, kamu harus memiliki klaster Kubernetes pada versi 1.10 atau yang lebih baru, dan kamu harus dapat berkomunikasi dengan server API yang menyediakan API metrik eksternal.
Lihat Panduan pengguna HorizontalPodAutoscaler untuk detail lebih lanjut.
Menjalankan & mengekspos server php-apache
Untuk mendemonstrasikan HorizontalPodAutoscaler kita akan menggunakan image Docker khusus berdasarkan image php-apache.
Dockerfile memiliki konten berikut:
FROM php:5-apache
ADD index.php /var/www/html/index.php
RUN chmod a+rx index.php
Bagian ini mendefinisikan laman index.php yang melakukan beberapa komputasi intensif CPU:
deployment.apps/php-apache created
service/php-apache created
Membuat HorizontalPodAutoscaler
Sekarang server sudah berjalan, selanjutnya kita akan membuat autoscaler menggunakan
kubectl autoscale.
Perintah berikut akan membuat HorizontalPodAutoscaler yang mengelola antara 1 dan 10 replika Pod yang dikontrol oleh Deployment php-apache yang kita buat pada langkah pertama instruksi ini.
Secara kasar, HPA akan menambah dan mengurangi jumlah replika
(melalui Deployment) untuk mempertahankan pemakaian CPU rata-rata di semua Pod sebesar 50%
(karena setiap Pod meminta 200 mili-core menurut kubectl run), ini berarti penggunaan CPU rata-rata adalah 100 mili-core).
Lihat ini untuk detail lebih lanjut tentang algoritmanya.
Kita dapat memeriksa status autoscaler saat ini dengan menjalankan:
kubectl get hpa
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 18s
Harap dicatat bahwa konsumsi CPU saat ini adalah 0% karena kita tidak mengirimkan permintaan apa pun ke server
(kolom TARGET menunjukkan nilai rata-rata di semua Pod yang dikontrol oleh Deployment yang sesuai).
Menambahkan beban
Sekarang, kita akan melihat bagaimana autoscaler bereaksi terhadap peningkatan beban.
Kita akan memulai sebuah Container, dan mengirimkan perulangan kueri tak terbatas ke Service php-apache (jalankan di terminal yang berbeda):
kubectl run -it --rm load-generator --image=busybox /bin/sh
Hit enter forcommand prompt
while true; do wget -q -O- http://php-apache; done
Dalam satu menit atau lebih, kita akan melihat beban CPU yang lebih tinggi dengan menjalankan:
kubectl get hpa
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 1 3m
Di sini, konsumsi CPU meningkat hingga 305% dari permintaan.
Hasilnya, Deployment mengubah ukurannya menjadi 7 replika:
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 7/7 7 7 19m
Catatan: Mungkin perlu beberapa menit untuk menstabilkan jumlah replika. Karena jumlah
bebannya tidak dikendalikan dengan cara apa pun, yang mungkin terjadi adalah jumlah replika akhir
akan berbeda dari contoh.
Menghentikan beban
Kita akan menyudahi contoh dengan menghentikan beban pengguna.
Di terminal tempat kita membuat Container dengan imagebusybox, hentikan
pembangkitan beban dengan mengetik <Ctrl> + C.
Kemudian kita akan memverifikasi status hasil (setelah satu menit atau lebih):
kubectl get hpa
NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 11m
kubectl get deployment php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 27m
Di sini penggunaan CPU turun menjadi 0, sehingga HPA secara otomatis melakukan penyekalaan jumlah replika kembali menjadi 1.
Catatan: Penyekalaan otomatis replika mungkin memerlukan waktu beberapa menit.
Penyekalaan otomatis pada metrik multipel dan metrik kustom
Kamu dapat memperkenalkan metrik tambahan untuk digunakan saat melakukan penyekalaan otomatis pada Deployment php-apache dengan menggunakan versi API autoscaling / v2beta2.
Pertama, dapatkan YAML HorizontalPodAutoscaler kamu dalam bentuk autoscaling / v2beta2:
kubectl get hpa.v2beta2.autoscaling -o yaml > /tmp/hpa-v2.yaml
Buka berkas /tmp/hpa-v2.yaml di editor, dan kamu akan melihat YAML yang terlihat seperti ini:
Perhatikan bahwa kolom targetCPUUtilizationPercentage telah diganti dengan himpunan yang disebut metrics.
Metrik penggunaan CPU adalah resource metric, merepresentasikan sebagai persentase sumber daya
ditentukan pada Container Pod. Perhatikan bahwa kamu dapat menentukan metrik sumber daya selain CPU. Secara bawaan,
satu-satunya metrik sumber daya lain yang didukung adalah memori. Sumber daya ini tidak mengubah nama dari klaster
ke klaster, dan harus selalu tersedia, selama API metrics.k8s.io tersedia.
Kamu juga dapat menentukan metrik sumber daya dalam nilai secara langsung, bukan sebagai persentase dari
nilai yang diminta, dengan menggunakan target.type dari AverageValue sebagai ganti Utilization, dan
menyetel fieldtarget.averageValue yang sesuai, bukan target.averageUtilization.
Ada dua jenis metrik lainnya, keduanya dianggap sebagai metrik khusus: metrik Pod dan
metrik objek. Metrik ini memungkinkan untuk memiliki nama yang spesifik untuk klaster, dan membutuhkan lebih banyak
pengaturan pemantauan klaster lanjutan.
Jenis metrik alternatif yang pertama adalah metrik Pod. Metrik ini mendeskripsikan Pod, dan
dirata-ratakan bersama di seluruh Pod dan dibandingkan dengan nilai target untuk menentukan jumlah replika.
Mereka bekerja seperti metrik sumber daya, kecuali bahwa mereka hanya mendukung jenis target dari AverageValue.
Metrik Pod ditentukan menggunakan blok metrik seperti ini:
Jenis metrik alternatif kedua adalah metrik objek. Metrik ini mendeskripsikan perbedaan
objek di Namespace yang sama, bukan mendeskripsikan Pod. Metriknya belum tentu
diambil dari objek; mereka hanya mendeskripsikannya. Metrik objek mendukung jenis target
baik Value dan AverageValue. Dengan Value, target dibandingkan langsung dengan yang dikembalikan
metrik dari API. Dengan AverageValue, nilai yang dikembalikan dari API metrik khusus dibagi
dengan jumlah Pod sebelum dibandingkan dengan target. Contoh berikut adalah YAML
representasi dari metrik requests-per-second.
Jika kamu memberikan beberapa blok metrik seperti itu, HorizontalPodAutoscaler akan mempertimbangkan setiap metrik secara bergantian.
HorizontalPodAutoscaler akan menghitung jumlah replika yang diusulkan untuk setiap metrik, lalu memilih
satu dengan jumlah replika tertinggi.
Misalnya, jika sistem pemantauan kamu mengumpulkan metrik tentang lalu lintas jaringan,
kamu dapat memperbarui definisi di atas menggunakan kubectl edit agar terlihat seperti ini:
Kemudian, HorizontalPodAutoscaler kamu akan mencoba memastikan bahwa setiap Pod mengonsumsi kira-kira
50% dari CPU yang diminta, melayani 1000 paket per detik, dan semua Pod berada di belakang Ingress
rute utama melayani total 10.000 permintaan per detik.
Penyekalaan otomatis pada metrik yang lebih spesifik
Banyak pipeline metrik memungkinkan kamu mendeskripsikan metrik baik berdasarkan nama atau kumpulan tambahan
deskriptor yang disebut labels. Untuk semua jenis metrik non-sumber daya (Pod, objek, dan eksternal,
dijelaskan seperti dibawah), kamu dapat menentukan pemilih label tambahan yang diteruskan ke pipa metrik kamu. Misalnya, jika kamu mengumpulkan metrik http_requests dengan label verb
, kamu dapat menentukan blok metrik berikut untuk diskalakan hanya pada permintaan GET:
Selector ini menggunakan sintaksis yang sama dengan selector lengkap label Kubernetes. Pipa pemantauan
menentukan cara mengecilkan beberapa seri menjadi satu nilai, jika nama dan pemilih cocok dengan
beberapa seri. Selektor bersifat aditif, dan tidak dapat memilih metrik yang mendeskripsikan objek
yang bukan objek target (target pod dalam kasus tipe Pod, dan objek yang dijelaskan dalam kasus tipe Objek).
Penyekalaan otomatis pada metrik yang tidak terkait dengan objek Kubernetes
Aplikasi yang berjalan di Kubernetes mungkin perlu melakukan penyekalaan otomatis berdasarkan metrik yang tidak
memiliki hubungan yang jelas dengan objek apa pun di klaster Kubernetes, seperti metrik yang mendeskripsikan
layanan yang dihosting tanpa korelasi langsung dengan namespace Kubernetes. Di Kubernetes 1.10 dan yang lebih baru, kamu dapat menangani kasus penggunaan ini dengan metrik eksternal.
Menggunakan metrik eksternal membutuhkan pengetahuan tentang sistem pemantauanmu; penyiapannya mirip dengan yang diperlukan saat menggunakan metrik khusus. Metrik eksternal memungkinkan kamu menskalakan klaster kamu secara otomatis berdasarkan metrik apa pun yang tersedia di sistem pemantauanmu. Cukup berikan blok metric dengan name dan selector (pemilih), seperti di atas, dan gunakan jenis metrik External, bukan Object.
Jika beberapa series cocok dengan metricSelector, jumlah dari nilai mereka akan digunakan oleh HorizontalPodAutoscaler.
Metrik eksternal mendukung jenis target Value dan AverageValue, yang berfungsi persis sama seperti saat kamu menggunakan tipe Object.
Misalnya, jika aplikasi kamu memproses tugas dari layanan antrian yang dihosting, kamu dapat menambahkan bagian berikut ke manifes HorizontalPodAutoscaler untuk menentukan bahwa kamu memerlukan satu pekerja per 30 tugas yang belum diselesaikan.
Jika memungkinkan, lebih baik menggunakan target metrik khusus daripada metrik eksternal, karena lebih mudah bagi administrator klaster untuk mengamankan API metrik khusus. API metrik eksternal berpotensi memungkinkan akses ke metrik apa pun, jadi administrator klaster harus berhati-hati saat mengeksposnya.
Lampiran: Kondisi Status Horizontal Pod Autoscaler
Saat menggunakan bentuk autoscaling/v2beta2 dari HorizontalPodAutoscaler, kamu akan dapat melihat
status condition yang ditetapkan oleh Kubernetes pada HorizontalPodAutoscaler. Status condition ini menunjukkan apakah HorizontalPodAutoscaler dapat melakukan penyekalaan atau tidak, dan apakah saat ini dibatasi atau tidak.
Kondisi muncul pada fieldstatus.conditions. Untuk melihat kondisi yang memengaruhi HorizontalPodAutoscaler, kita bisa menggunakan kubectl description hpa:
kubectl describe hpa cm-test
Name: cm-test
Namespace: prom
Labels: <none>
Annotations: <none>
CreationTimestamp: Fri, 16 Jun 2017 18:09:22 +0000
Reference: ReplicationController/cm-test
Metrics: ( current / target )"http_requests" on pods: 66m / 500m
Min replicas: 1
Max replicas: 4
ReplicationController pods: 1 current / 1 desired
Conditions:
Type Status Reason Message
---- ------ ------ -------
AbleToScale True ReadyForNewScale the last scale time was sufficiently old as to warrant a new scale
ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_requests
ScalingLimited False DesiredWithinRange the desired replica count is within the acceptable range
Events:
Untuk HorizontalPodAutoscaler ini, kita dapat melihat beberapa kondisi yang menandakan dalam keadaan sehat. Yang pertama, AbleToScale, menunjukkan apakah HPA dapat mengambil dan memperbarui skala atau tidak, serta apakah kondisi terkait backoff akan mencegah penyekalaan atau tidak. Yang kedua, ScalingActive, menunjukkan apakah HPA diaktifkan atau tidak (yaitu jumlah replika target bukan nol) dan mampu menghitung skala yang diinginkan. Jika False, biasanya menunjukkan masalah dengan
pengambilan metrik. Terakhir, kondisi terakhir, ScalingLimited, menunjukkan bahwa skala yang diinginkan telah dibatasi oleh maksimum atau minimum HorizontalPodAutoscaler. Ini adalah indikasi bahwa kamu mungkin ingin menaikkan atau menurunkan batasan jumlah replika minimum atau maksimum pada HorizontalPodAutoscaler kamu.
Lampiran: Kuantitas
Semua metrik di HorizontalPodAutoscaler dan metrik API ditentukan menggunakan notasi bilangan bulat khusus yang dikenal di Kubernetes sebagai kuantitas. Misalnya, kuantitas 10500m akan ditulis sebagai 10.5 dalam notasi desimal. Metrik API akan menampilkan bilangan bulat tanpa sufiks jika memungkinkan, dan secara umum akan mengembalikan kuantitas dalam satuan mili. Ini berarti kamu mungkin melihat nilai metrik berfluktuasi antara 1 dan 1500m, atau 1 dan 1,5 ketika ditulis dalam notasi desimal.
Lampiran: Skenario lain yang memungkinkan
Membuat autoscaler secara deklaratif
Daripada menggunakan perintah kubectl autoscale untuk membuat HorizontalPodAutoscaler secara imperatif, kita dapat menggunakan berkas berikut untuk membuatnya secara deklaratif:
horizontalpodautoscaler.autoscaling/php-apache created
8 - Mengakes Aplikasi-aplikasi di sebuah Klaster
8.1 - Antarmuka Pengguna Berbasis Web (Dashboard)
Dashboard adalah antarmuka pengguna Kubernetes. Kamu dapat menggunakan Dashboard untuk men-deploy aplikasi yang sudah dikontainerisasi ke klaster Kubernetes, memecahkan masalah pada aplikasi kamu, dan mengatur sumber daya klaster. Kamu dapat menggunakan Dashboard untuk melihat ringkasan dari aplikasi yang sedang berjalan di klaster kamu, dan juga membuat atau mengedit objek individu sumber daya Kubernetes (seperti Deployment, Job, DaemonSet, dll.). Sebagai contoh, kamu dapat mengembangkan sebuah Deployment, menginisiasi sebuah pembaruan bertahap (rolling update), memulai kembali sebuah Pod atau men-deploy aplikasi baru menggunakan sebuah deploy wizard.
Dashboard juga menyediakan informasi tentang status dari sumber daya Kubernetes di klaster kamu dan kesalahan apapun yang mungkin telah terjadi..
Men-deploy Antarmuka Pengguna Dashboard
Antarmuka Dashboard tidak ter-deploy secara bawaan. Untuk men-deploy-nya, kamu dapat menjalankan perintah berikut:
Untuk melindungi data klaster kamu, pen-deploy-an Dashboard menggunakan sebuah konfigurasi RBAC yang minimal secara bawaan. Saat ini, Dashboard hanya mendukung otentikasi dengan Bearer Token. Untuk membuat token untuk demo, kamu dapat mengikuti petunjuk kita untuk membuat sebuah contoh pengguna.
Peringatan: Contoh pengguna yang telah dibuat di tutorial tersebut akan memiliki hak istimewa sebagai administrator dan hanyalah untuk tujuan pembelajaran.
Proksi antarmuka baris perintah (CLI)
Kamu dapat mengakses Dashboard menggunakan perkakas CLI kubectl dengan menjalankan perintah berikut:
kubectl proxy
Kubectl akan membuat Dashboard tersedia di http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/.
Antarmuka pengguna berbasis web tersebut hanya dapat di akses dari mesin dimana perintah tersebut dijalankan. Lihat kubectl proxy --help untuk lebih lanjut.
Catatan: Metode otentikasi Kubeconfig tidak mendukung penyedia identitas eksternal atau otentikasi berbasis sertifikat elektronik x509.
Tampilan selamat datang
Ketika kamu mengakses Dashboard di klaster yang kosong, kamu akan melihat laman selamat datang. Laman ini berisi tautan ke dokumen ini serta tombol untuk men-deploy aplikasi pertama kamu. Selain itu, kamu dapat melihat aplikasi-aplikasi sistem mana saja yang berjalan secara bawaan di Namespacekube-system dari klaster kamu, misalnya Dashboard itu sendiri.
Men-deploy aplikasi yang sudah dikontainerisasi
Dashboard memungkinkan kamu untuk membuat dan men-deploy aplikasi yang sudah dikontainerisasi sebagai Deployment dan Service opsional dengan sebuah wizard sederhana. Kamu secara manual dapat menentukan detail aplikasi, atau mengunggah sebuah berkas YAML atau JSON yang berisi konfigurasi aplikasi.
Tekan tombol CREATE di pojok kanan atas di laman apapun untuk memulai.
Menentukan detail aplikasi
Deploy wizard meminta kamu untuk menyediakan informasi sebagai berikut:
App name (wajib): Nama dari aplikasi kamu. Sebuah label dengan nama tersebut akan ditambahkan ke Deployment dan Service, jika ada, akan di-deploy.
Nama aplikasi harus unik di dalam Namespace Kubernetes yang kamu pilih. Nama tersebut harus dimulai dengan huruf kecil, dan diakhiri dengan huruf kecil atau angka, dan hanya berisi huruf kecil, angka dan tanda hubung (-). Nama tersebut juga dibatasi hanya 24 karakter. Spasi di depan dan belakang nama tersebut diabaikan.
Container image (wajib): Tautan publik dari sebuah image kontainer Docker pada registry apapun, atau sebuah image privat (biasanya di-hosting di Google Container Registry atau Docker Hub). Spesifikasi image kontainer tersebut harus diakhiri dengan titik dua.
Number of pods (wajib): Berapa banyak Pod yang kamu inginkan untuk men-deploy aplikasimu. Nilainya haruslah sebuah bilangan bulat positif.
Sebuah Deployment akan terbuat untuk mempertahankan jumlah Pod di klaster kamu.
Service (opsional): Untuk beberapa aplikasi (misalnya aplikasi frontend) kamu mungkin akan mengekspos sebuah Service ke alamat IP publik yang mungkin berada diluar klaster kamu(Service eksternal). Untuk Service eksternal, kamu mungkin perlu membuka lebih dari satu porta jaringan untuk mengeksposnya. Lihat lebih lanjut di sini.
Service lainnya yang hanya dapat diakses dari dalam klaster disebut Service internal.
Terlepas dari jenis Service, jika kamu memilih untuk membuat sebuah Service dan Container kamu berjalan di sebuah porta(arah masuk), kamu perlu menentukan dua porta. Service akan memetakan porta(arah masuk) ke porta target yang ada di sisi Container. Service akan mengarahkan ke Pod-Pod kamu yang sudah di-deploy. Protokol yang didukung adalah TCP dan UDP. Nama DNS internal untuk Service ini akan sesuai dengan nama aplikasi yang telah kamu tentukan diatas.
Jika membutuhkan, kamu dapat membuka bagian Advanced options di mana kamu dapat menyetel lebih banyak pengaturan:
Description: Tels yang kamu masukkan ke sini akan ditambahkan sebagai sebuah anotasi ke Deployment dan akan ditampilkan di detail aplikasi.
Labels: Label-label bawaan yang akan digunakan untuk aplikasi kamu adalah name dan version aplikasi. Kamu dapat menentukan label lain untuk diterapkan ke Deployment, Service (jika ada), dan Pod, seperti release, environment, tier, partition, dan track rilis.
Namespace: Kubernetes mendukung beberapa klaster virtual yang berjalan di atas klaster fisik yang sama. Klaster virtual ini disebut Namespace. Mereka mengizinkan kamu untuk mempartisi sumber daya ke beberapa grup yang diberi nama secara logis.
Dashboard menampilkan semua Namespace yang tersedia dalam sebuah daftar dropdown, dan mengizinkan kamu untuk membuat Namespace baru. Nama yang diizinkan untuk Namespace terdiri dari maksimal 63 karakter alfanumerik dan tanda hubung (-), dan tidak boleh ada huruf kapital.
Nama dari Namespace tidak boleh terdiri dari angka saja. Jika nama Namespace disetel menjadi sebuah angka, misalnya 10, maka Pod tersebut akan ditaruh di Namespace default.
Jika pembuatan Namespace berhasil, Namespace tersebut akan dipilih secara bawaan. Jika pembuatannya gagal, maka Namespace yang pertama akan terpilih.
Image Pull Secret: Jika kamu menggunakan image kontainer Docker yang privat, mungkin diperlukan kredensial pull secret.
Dashboard menampilkan semua secret yang tersedia dengan daftar dropdown, dan mengizinkan kamu untuk membuat secret baru. Nama secret tersebut harus mengikuti aturan Nama DNS, misalnya new.image-pull.secret. Isi dari sebuah secret harus dienkode dalam bentuk base64 dan ditentukan dalam sebuah berkas .dockercfg. Nama kredensial dapat berisi maksimal 253 karakter.
Jika pembuatan image pull secret berhasil, image pull secret tersebut akan terpilih secara bawaan. Jika gagal, maka tidak ada secret yang dipilih.
CPU requirement (cores) dan Memory requirement (MiB): Kamu dapat menentukan batasan sumber daya minimal untuk Container. Secara bawaan, Pod-Pod berjalan dengan CPU dan memori yang tak dibatasi.
Run command dan Run command arguments: Secara bawaan, Container-Container kamu akan menjalankan perintah entrypoint bawaan dari image Docker yang ditentukan. Kamu dapat menggunakan opsi Run command dan Run command arguments untuk mengganti bawaannya.
Run as priveleged: Pengaturan ini untuk menentukan sebuah proses yang berjalan dalam privileged container sepadan dengan proses yang berjalan sebagai root pada host-nya. Priveleged container dapat menggunakan kemampuan seperti memanipulasi stack jaringan dan mengakses perangkat-perangkat.
Environment variables: Kubernetes mengekspos Service melalui environment variable. Kamu dapat membuat environment variable atau meneruskan argumen ke perintah-perintah untuk menjalankan Container dengan nilai dari environment variable. Environment Variable dapat digunakan pada aplikasi-aplikasi untuk menemukan sebuah Service. Nilai environment variable dapat merujuk ke variabel lain menggunakan sintaksis $(VAR_NAME).
Menggungah berkas YAML atau JSON
Kubernetes mendukung pengaturan deklaratif. Dengan cara ini, semua pengaturan disimpan dalam bentuk berkas YAML atau JSON menggunakan skema sumber daya [API.
Sebagai alternatif untuk menentukan detail aplikasi di deploy wizard, kamu dapat menentukan sendiri detail aplikasi kamu dalam berkas YAML atau JSON, dan mengunggah berkas tersebut menggunakan Dashboard.
Menggunakan Dashboard
Bagian ini akan menjelaskan bagian-bagian yang ada pada Antarmuka Dashboard Kubernetes; apa saja yang mereka sediakan dan bagaimana cara menggunakanya.
Navigation
Ketika ada objek Kubernetes yang sudah didefinisikan di dalam klaster, Dashboard akan menampilkanya di tampilan awalnya. Secara bawaan hanya objek-objek dalam Namespace default saja yang ditampilkan di sini dan kamu dapat menggantinya dengan selektor Namespace yang berada di menu navigasi.
Dashboard menampilkan jenis objek Kubernetes dan mengelompokanya dalam beberapa kategori menu.
Admin Overview
Untuk administrasi klaster dan Namespace, Dashboard menampilkan Node, Namespace dan PresistentVolume dan memiliki tampilan yang detail untuk objek-objek tersebut. Daftar Node berisi metrik penggunaan CPU dan memori yang dikumpulkan dari semua Node. Tampilan detail menampilkan metrik-metrik untuk sebuah Node, spesifikasinya, status, sumber daya yang dialokasikan, event-event, dan Pod-Pod yang sedang berjalan di Node tersebut.
Workloads
Menampilkan semua aplikasi yang sedang berjalan di Namespace yang dipilih. Tampilan ini menampilkan aplikasi berdasarkan jenis beban kerja (misalnya, Deployment, Replica Set, Stateful Set, dll.) dan setiap jenis beban kerja memiliki tampilanya sendiri. Daftar ini merangkum informasi yang dapat ditindaklanjuti, seperti berapa banyak Pod yang siap untuk setiap Replica Set atau penggunaan memori pada sebuah Pod.
Tampilan detail dari beban kerja menampilkan status dan informasi spesifik serta hubungan antara objek. Misalnya, Pod-Pod yang diatur oleh ReplicaSet atau, ReplicaSet-ReplicaSet baru, dan HorizontalPodAutoscaler untuk Deployment.
Services
Menampilkan sumber daya Kubernetes yang mengizinkan untuk mengekspos Service-Service ke jaringan luar dan menemukannya (service discovery) di dalam klaster. Untuk itu, tampilan dari Service dan Ingress menunjukan Pod-Pod yang ditarget oleh mereka, endpoint-endpoint internal untuk koneksi klaster, dan endpoint-endpoint eksternal untuk pengguna eksternal.
Storage
Tampilan Storage menampilkan sumber-sumber daya PersistentVolumeClaim yang digunakan oleh aplikasi untuk menyimpan data.
Config Maps dan Secrets
Menampilkan semua sumber daya Kubernetes yang digunakan untuk pengaturan aplikasi yang sedang berjalan di klaster. Pada tampilan ini kamu dapat mengedit dan mengelola objek-objek konfigurasi dan menampilkan kredensial yang tersembunyi secara bawaan.
Logs Viewer
Laman daftar dan detail Pod tertaut dengan laman penampil log (log viewer). Kamu dapat menelusuri log yang berasal dari Container-Container pada sebuah Pod.
Topik ini membahas tentang berbagai cara untuk berinteraksi dengan klaster.
Mengakses untuk pertama kalinya dengan kubectl
Saat mengakses API Kubernetes untuk pertama kalinya, kami sarankan untuk menggunakan
CLI Kubernetes, kubectl.
Untuk mengakses sebuah klaster, kamu perlu mengetahui lokasi klaster dan mempunyai kredensial untuk mengaksesnya.
Biasanya, ini secara otomatis diatur saat kamu mengikuti Panduan persiapan,
atau orang lain yang mengatur klaster dan memberikan kredensial dan lokasi kepadamu.
Periksa lokasi dan kredensial yang ada pada konfigurasi kubectl-mu melalui perintah ini:
kubectl config view
Beragam contoh menyediakan pengantar penggunaan kubectl, dan dokumentasi lengkap dapat ditemukan di kubectl manual.
Mengakses REST API secara langsung
Kubectl menangani pencarian dan autentikasi ke apiserver.
Jika kamu ingin secara langsung mengakses REST API dengan klien HTTP seperti curl atau wget, atau peramban, ada beberapa cara untuk pencarian dan autentikasi:
Jalankan kubectl dalam mode proksi.
Pendekatan yang disarankan.
Menggunakan lokasi apiserver yang tersimpan.
Melakukan verifikasi identitas apiserver menggunakan sertifikat elektronik yang ditandatangani sendiri. Tidak memungkinkan adanya MITM.
Melakukan autentikasi ke apiserver.
Di masa depan, dimungkinkan dapat melakukan load-balancing dan failover yang cerdas dari sisi klien.
Penyediaan lokasi dan kredensial langsung ke klien http.
Pendekatan alternatif.
Bekerja dengan beberapa jenis kode klien dengan menggunakan proksi.
Perlu mengimpor sertifikat elektronik root ke peramban kamu untuk melindungi dari MITM.
Menggunakan kubectl proxy
Perintah berikut akan menjalankan kubectl dalam mode di mana ia bertindak sebagai proksi terbalik (reverse proxy).
Hal ini menangani pencarian dan autentikasi apiserver.
Jalankan seperti ini:
Contoh di atas menggunakan flag--insecure. Hal ini membuatnya rentan terhadap serangan MITM.
Ketika kubectl mengakses klaster, kubectl menggunakan sertifikat elektronik root yang tersimpan dan sertifikat elektronik klien untuk mengakses server.
(Sertifikat-sertifikat elektronik tersebut diinstal di direktori ~/.kube). Karena sertifikat elektronik klaster biasanya ditandatangani sendiri,
mungkin diperlukan konfigurasi khusus untuk membuat klien HTTP kamu menggunakan sertifikat elektronik root.
Pada beberapa klaster, apiserver tidak memerlukan autentikasi; mungkin apiserver tersebut meladen (serve) di localhost, atau dilindungi oleh sebuah dinding api (firewall).
Tidak ada standar untuk ini. Mengonfigurasi Akses ke API menjelaskan bagaimana admin klaster dapat mengonfigurasi hal ini.
Pendekatan semacam itu dapat bertentangan dengan dukungan ketersediaan tinggi (high-availability) pada masa depan.
Akses terprogram ke API
Kubernetes secara resmi mendukung pustaka (library) klien Go dan Python.
Klien Go
Untuk mendapatkan pustakanya, jalankan perintah berikut: go get k8s.io/client-go@kubernetes-<kubernetes-version-number>, lihat INSTALL.md untuk instruksi instalasi yang lebih detail. Lihat https://github.com/kubernetes/client-go untuk melihat versi yang didukung.
Tulis aplikasi dengan menggunakan klien client-go. Perhatikan bahwa client-go mendefinisikan objek APInya sendiri, jadi jika perlu, silakan impor definisi API dari client-go daripada dari repositori utama, misalnya, import "k8s.io/client-go/kubernetes".
Klien Go dapat menggunakan berkas kubeconfig yang sama dengan yang digunakan oleh CLI kubectl untuk mencari dan mengautentikasi ke apiserver. Lihat contoh ini.
Jika aplikasi ini digunakan sebagai Pod di klaster, silakan lihat bagian selanjutnya.
Klien Python dapat menggunakan berkas kubeconfig yang sama dengan yang digunakan oleh CLI kubectl untuk mencari dan mengautentikasi ke apiserver. Lihat contoh.
Bahasa lainnya
Ada pustaka klien untuk mengakses API dari bahasa lain.
Lihat dokumentasi pustaka lain untuk melihat bagaimana mereka melakukan autentikasi.
Mengakses API dari Pod
Saat mengakses API dari Pod, pencarian dan autentikasi ke apiserver agak berbeda.
Cara yang disarankan untuk menemukan apiserver di dalam Pod adalah dengan nama DNS kubernetes.default.svc,
yang akan mengubah kedalam bentuk Service IP yang pada gilirannya akan dialihkan ke apiserver.
Cara yang disarankan untuk mengautentikasi ke apiserver adalah dengan kredensial akun servis.
Oleh kube-system, Pod dikaitkan dengan sebuah akun servis (service account), dan sebuah kredensial (token) untuk akun servis (service account) tersebut ditempatkan ke pohon sistem berkas (file system tree) dari setiap Container di dalam Pod tersebut,
di /var/run/secrets/kubernetes.io/serviceaccount/token.
Jika tersedia, bundel sertifikat elektronik ditempatkan ke pohon sistem berkas dari setiap Container di /var/run/secrets/kubernetes.io/serviceaccount/ca.crt,
dan itu akan digunakan untuk memverifikasi sertifikat elektronik yang digunakan apiserver untuk meladen.
Terakhir, Namespace default yang akan digunakan untuk operasi API namespaced ditempatkan di dalam berkas /var/run/secrets/kubernetes.io/serviceaccount/namespace di dalam setiap Container.
Dari dalam Pod, cara yang disarankan untuk menghubungi API adalah:
Jalankan kubectl proxy pada Container sidecar di dalam Pod, atau sebagai proses background di dalam Container.
Perintah tersebut memproksi API Kubernetes pada antarmuka localhost Pod tersebut, sehingga proses lain dalam Container apa pun milik Pod dapat mengaksesnya.
Gunakan pustaka klien Go, dan buatlah sebuah klien menggunakan fungsi rest.InClusterConfig() dan kubernetes.NewForConfig().
Mereka menangani pencarian dan autentikasi ke apiserver. contoh
Pada setiap kasus, kredensial Pod digunakan untuk berkomunikasi secara aman dengan apiserver.
Mengakses servis yang berjalan di klaster
Bagian sebelumnya menjelaskan tentang menghubungi server API Kubernetes. Bagian ini menjelaskan tentang menghubungi servis lain yang berjalan di klaster Kubernetes.
Di Kubernetes, semua Node, Pod, dan Service memiliki IP sendiri.
Dalam banyak kasus, IP Node, IP Pod, dan beberapa IP Service pada sebuah klaster tidak dapat dirutekan, sehingga mereka tidak terjangkau dari mesin di luar klaster, seperti mesin desktop kamu.
Cara untuk terhubung
Kamu memiliki beberapa opsi untuk menghubungi Node, Pod, dan Service dari luar klaster:
Mengakses Service melalui IP publik.
Gunakan Service dengan tipe NodePort atau LoadBalancer untuk membuat Service dapat dijangkau di luar klaster. Lihat dokumentasi Service dan perintah kubectl expose.
Bergantung pada lingkungan klaster kamu, hal ini mungkin hanya mengekspos Service ke jaringan perusahaan kamu, atau mungkin mengeksposnya ke internet. Pikirkan apakah Service yang diekspos aman atau tidak. Apakah layanan di balik Service tersebut melakukan autentikasinya sendiri?
Tempatkan Pod di belakang Service. Untuk mengakses satu Pod tertentu dari sekumpulan replika, misalnya untuk pengawakutuan (debugging), letakkan label unik di Pod dan buat Service baru yang memilih label ini.
Pada kebanyakan kasus, pengembang aplikasi tidak perlu langsung mengakses Node melalui IP Node mereka.
Akses Service, Node, atau Pod menggunakan Verb Proxy.
Apakah autentikasi dan otorisasi apiserver dilakukan sebelum mengakses Service jarak jauh. Gunakan ini jika Service tersebut tidak cukup aman untuk diekspos ke internet, atau untuk mendapatkan akses ke porta (port) pada IP Node, atau untuk pengawakutuan.
Proksi dapat menyebabkan masalah untuk beberapa aplikasi web.
Jalankan Pod, kemudian hubungkan ke sebuah shell di dalamnya menggunakan kubectl exec. Hubungi Node, Pod, dan Service lain dari shell itu.
Beberapa klaster memungkinkan kamu untuk melakukan SSH ke sebuah Node di dalam klaster. Dari sana, kamu mungkin dapat mengakses Service-Service klaster. Hal ini merupakan metode yang tidak standar, dan akan bekerja pada beberapa klaster tetapi tidak pada yang lain. Peramban dan perkakas lain mungkin diinstal atau tidak. DNS Klaster mungkin tidak berfungsi.
Menemukan Service bawaan (builtin)
Biasanya, ada beberapa Service yang dimulai pada sebuah klaster oleh kube-system. Dapatkan daftarnya dengan perintah kubectl cluster-info:
kubectl cluster-info
Keluarannya mirip seperti ini:
Kubernetes master is running at https://104.197.5.247
elasticsearch-logging is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy
kibana-logging is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/kibana-logging/proxy
kube-dns is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/kube-dns/proxy
grafana is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
heapster is running at https://104.197.5.247/api/v1/namespaces/kube-system/services/monitoring-heapster/proxy
Ini menunjukkan URL proxy-verb untuk mengakses setiap Service.
Misalnya, klaster ini mempunyai pencatatan log pada level klaster (cluster-level logging) yang aktif (menggunakan Elasticsearch), yang dapat dicapai di https://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/ jika kredensial yang sesuai diberikan.
Pencatatan log dapat pula dicapai dengan sebuah proksi kubectl, misalnya di:
http://localhost:8080/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/.
(Lihat di atas untuk panduan bagaimana cara meneruskan kredensial atau menggunakan kubectl proxy.)
Membuat URL proksi apiserver secara manual
Seperti disebutkan di atas, kamu menggunakan perintah kubectl cluster-info untuk mendapatkan URL proksi suatu Service.
Untuk membuat URL proksi yang memuat endpoint-endpoint Service, sufiks, dan parameter, kamu cukup menambahkan ke URL proksi Service:
http://alamat_kubernetes_master/api/v1/namespaces/nama_namespace/services/nama_servis[:nama_porta]/proxy
Jika kamu belum menentukan nama untuk porta kamu, kamu tidak perlu memasukan nama_porta di URL.
Secara bawaan, server API memproksi ke Service kamu menggunakan HTTP. Untuk menggunakan HTTPS, awali nama Service dengan https::
http://alamat_kubernetes_master/api/v1/namespaces/nama_namespace/services/https:nama_servis:[nama_porta]/proxy
Format yang didukung untuk segmen nama URL adalah:
<nama_servis> - Memproksi ke porta bawaan atau porta tanpa nama menggunakan HTTP
<nama_servis>:<nama_porta> - Memproksi ke porta yang telah ditentukan menggunakan HTTP
https:<nama_servis>: - Memproksi ke porta bawaan atau porta tanpa nama menggunakan HTTPS (perhatikan tanda adanya titik dua)
https:<nama_servis>:<nama_porta> - proksi ke porta yang telah ditentukan menggunakan https
Contoh
Untuk mengakses endpoint Service Elasticsearch _search?q=user:kimchy, kamu dapat menggunakan: http://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_search?q=user:kimchy
Untuk mengakses informasi kesehatan klaster Elasticsearch _cluster/health?pretty=true, kamu dapat menggunakan: https://104.197.5.247/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy/_cluster/health?pretty=true
Menggunakan peramban web untuk mengakses Service yang berjalan di klaster
Kamu mungkin dapat memasukkan URL proksi apiserver ke bilah alamat peramban. Namun:
Peramban web biasanya tidak dapat menerima token, jadi kamu mungkin perlu menggunakan autentikasi dasar/basic auth (kata sandi). Apiserver dapat dikonfigurasi untuk menerima autentikasi dasar, tetapi klaster kamu mungkin belum dikonfigurasi untuk menerima autentikasi dasar.
Beberapa aplikasi web mungkin tidak berfungsi, terutama yang memiliki javascript pada sisi klien yang digunakan untuk membuat URL sedemikian sehingga ia tidak mengetahui adanya prefiks jalur (path) proksi (/proxy).
Meminta pengalihan
Kemampuan pengalihan telah usang (deprecated) dan dihapus. Silakan gunakan proksi (lihat di bawah) sebagai gantinya.
Begitu Banyaknya Proksi
Ada beberapa proksi berbeda yang mungkin kamu temui saat menggunakan Kubernetes:
keberadaan dan implementasi bervariasi dari satu klaster ke klaster lainnya (mis. nginx)
terletak di antara semua klien dan satu atau lebih apiserver
bertindak sebagai load balancer jika terdapat beberapa apiserver.
Cloud Load Balancer pada Service eksternal:
disediakan oleh beberapa penyedia layanan cloud (mis. AWS ELB, Google Cloud Load Balancer)
dibuat secara otomatis ketika Service Kubernetes memiliki tipe LoadBalancer
hanya menggunakan UDP/TCP
implementasi bervariasi berdasarkan penyedia layanan cloud.
Pengguna Kubernetes biasanya tidak perlu khawatir tentang apa pun selain dua jenis pertama. Admin klaster biasanya akan memastikan bahwa tipe yang terakhir telah diatur dengan benar.
8.3 - Mengkonfigurasi Akses ke Banyak Klaster
Halaman ini menunjukkan bagaimana mengkonfigurasi akses ke banyak klaster dengan menggunakan
berkas (file) konfigurasi. Setelah semua klaster, pengguna, dan konteks didefinisikan di
satu atau lebih berkas konfigurasi, kamu akan dengan cepat berpindah antar klaster dengan menggunakan
perintah kubectl config use-context.
Catatan: Berkas yang digunakan untuk mengkonfigurasi akses ke sebuah klaster terkadang disebut
berkas kubeconfig. Ini adalah cara umum untuk merujuk ke berkas konfigurasi.
Itu tidak berarti bahwa selalu ada berkas bernama kubeconfig.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Misalkan kamu memiliki dua klaster, satu untuk pekerjaan pengembangan dan satu untuk pekerjaan eksperimen (scratch).
Di klaster pengembangan, pengembang frontend kamu bekerja di sebuah Namespace bernama frontend,
dan pengembang penyimpanan kamu bekerja di sebuah Namespace bernama storage. Di klaster scratch kamu,
pengembang bekerja di Namespace default, atau mereka membuat Namespace tambahan sesuai keinginan mereka.
Akses ke klaster development membutuhkan autentikasi dengan sertifikat.
Akses ke klaster scratch membutuhkan autentikasi dengan nama pengguna dan kata sandi.
Buat sebuah direktori bernama config-exercise. Di direktori config-exercise kamu,
buat sebuah berkas bernama config-demo dengan konten ini:
Berkas konfigurasi di atas mendeskripsikan semua klaster, pengguna, dan konteks.
Berkas config-demo kamu memiliki kerangka kerja untuk mendeskripsikan dua klaster, dua pengguna, dan tiga konteks.
Buka direktori config-exercise kamu. Masukkan perintah-perintah berikut untuk menambahkan detail ke
berkas konfigurasi kamu:
Buka berkas config-demo kamu untuk melihat detail-detail yang telah ditambah. Sebagai alternatif dari membuka
berkas config-demo, kamu bisa menggunakan perintah config view.
kubectl config --kubeconfig=config-demo view
Keluaran akan menampilkan dua klaster, dua pengguna, dan tiga konteks:
fake-ca-file, fake-cert-file, dan fake-key-file di atas adalah placeholder
untuk nama jalur (pathname) dari berkas-berkas sertifikat. Kamu harus menggantinya menjadi nama jalur
sebenarnya dari berkas-berkas sertifikat di dalam lingkungan (environment) kamu.
Terkadang kamu mungkin ingin menggunakan data yang disandikan Base64 yang langsung dimasukkan di berkas konfigurasi
daripada menggunakan berkas sertifikat yang terpisah. Dalam kasus ini, kamu perlu menambahkan akhiran -data ke kunci. Contoh, certificate-authority-data, client-certificate-data, dan client-key-data.
Setiap konteks memiliki tiga bagian: klaster, pengguna, dan Namespace.
Sebagai contoh, konteks dev-frontend menyatakan, "Gunakan kredensial dari pengguna developer
untuk mengakses Namespace frontend di klaster development.
Sekarang kapanpun kamu memasukkan perintah kubectl, aksi tersebut akan diterapkan untuk klaster,
dan Namespace yang terdaftar pada konteks dev-frontend. Dan perintah tersebut akan menggunakan
kredensial dari pengguna yang terdaftar pada konteks dev-frontend.
Untuk melihat hanya informasi konfigurasi yang berkaitan dengan konteks saat ini,
gunakan --minify flag.
Sekarang, setiap perintah kubectl yang diberikan akan berlaku untuk Namespace default
dari klaster scratch. Dan perintah akan menggunakan kredensial dari pengguna yang
terdaftar di konteks exp-scratch.
Untuk melihat konfigurasi yang berkaitan dengan konteks saat ini, exp-scratch.
Berkas konfigurasi di atas mendefinisikan sebuah konteks baru bernama dev-ramp-up.
Mengatur variabel lingkungan KUBECONFIG
Lihat apakah kamu sudah memiliki sebuah variabel lingkungan bernama KUBECONFIG.
Jika iya, simpan nilai saat ini dari variabel lingkungan KUBECONFIG kamu, sehingga kamu dapat mengembalikannya nanti.
Sebagai contohL
Linux
exportKUBECONFIG_SAVED=$KUBECONFIG
Windows PowerShell
$Env:KUBECONFIG_SAVED=$ENV:KUBECONFIG
Variabel lingkungan KUBECONFIG adalah sebuah daftar dari jalur-jalur (beragam path) menuju berkas konfigurasi.
Daftar ini dibatasi oleh tanda titik dua untuk Linux dan Mac, dan tanda titik koma untuk Windows. Jika kamu
memiliki sebuah variabel lingkungan KUBECONFIG, biasakan diri kamu dengan berkas-berkas konfigurasi
yang ada pada daftar.
Tambahkan sementara dua jalur ke variabel lingkungan KUBECONFIG kamu. Sebagai contoh:
Di direktori config-exercise kamu, masukan perintah ini:
kubectl config view
Keluaran menunjukkan informasi gabungan dari semua berkas yang terdaftar dalam variabel lingkungan KUBECONFIG kamu.
Secara khusus, perhatikan bahwa informasi gabungan tersebut memiliki konteks dev-ramp-up, konteks dari berkas
config-demo-2, dan tiga konteks dari berkas config-demo:
Jika kamu sudah memiliki sebuah klaster, dan kamu bisa menggunakan kubectl untuk berinteraksi dengan
klaster kamu, kemudian kamu mungkin memiliki sebuah berkas bernama config di
direktori $HOME/.kube.
Buka $HOME/.kube, dan lihat berkas-berkas apa saja yang ada. Biasanya ada berkas bernama
config. Mungkin juga ada berkas-berkas konfigurasi lain di direktori ini.
Biasakan diri anda dengan konten-konten yang ada di berkas-berkas tersebut.
Tambahkan $HOME/.kube/config ke variabel lingkungan KUBECONFIG kamu
Jika kamu memiliki sebuah berkas $HOME/.kube/config, dan belum terdaftar dalam variabel lingungan
KUBECONFIG kamu, tambahkan berkas tersebut ke variabel lingkungan KUBECONFIG kamu sekarang.
Sebagai contoh:
Lihat gabungan informasi konfigurasi dari semua berkas yang sekarang tergabung
dalam variabel lingkungan KUBECONFIG kamu. Di direktori config-exercise kamu, masukkan perintah:
kubectl config view
Membersihkan
Kembalikan variabel lingkungan KUBECONFIG kamu ke nilai asilnya. Sebagai contoh:
8.4 - Menggunakan Port Forwarding untuk Mengakses Aplikasi di sebuah Klaster
Halaman ini menunjukkan bagaimana menggunakan kubectl port-forward untuk menghubungkan sebuah server Redis yang sedang berjalan di sebuah klaster Kubernetes. Tipe dari koneksi ini dapat berguna untuk melakukan debugging basis data.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Keluaran dari perintah yang sukses akan memverifikasi bahwa Service telah terbuat:
service/redis-master created
Lihat Service yang telah terbuat menggunakan:
kubectl get service redis-master
Keluaran menampilkan service yang telah terbuat:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis-master ClusterIP 10.0.0.213 <none> 6379/TCP 27s
Periksa apakah server Redis berjalan di Pod, dan mendengarkan porta 6379:
# Ubah redis-master-765d459796-258hz menjadi nama Pod
kubectl get pod redis-master-765d459796-258hz --template='{{(index (index .spec.containers 0).ports 0).containerPort}}{{"\n"}}'
Keluaran akan menampilkan porta dari Redis di Pod tersebut:
6379
(ini adalah porta TCP yang dialokasi untuk Redis di internet)
Meneruskan sebuah porta lokal ke sebuah porta pada Pod
kubectl port-forward memungkinkan penggunaan nama sumber daya, seperti sebuah nama Pod, untuk memilih Pod yang sesuai untuk melakukan penerusan porta.
# Ubah redis-master-765d459796-258hz menjadi nama Pod
kubectl port-forward redis-master-765d459796-258hz 7000:6379
Semua perintah di atas berfungsi. Keluarannya mirip dengan ini:
I0710 14:43:38.274550 3655 portforward.go:225] Forwarding from 127.0.0.1:7000 -> 6379
I0710 14:43:38.274797 3655 portforward.go:225] Forwarding from [::1]:7000 -> 6379
Memulai antarmuka baris perintah (command line) Redis:
redis-cli -p 7000
Pada baris perintah di Redis, masukkan perintah ping:
ping
Sebuah permintaan ping yang sukses akan mengembalikan:
PONG
Diskusi
Koneksi-koneksi yang dibuat ke porta lokal 7000 diteruskan ke porta 6379 dari Pod yang menjalankan server Redis.
Dengan koneksi ini, kamu dapat menggunakan workstation lokal untuk melakukan debug basis data yang berjalan di Pod.
Catatan:kubectl port-forward hanya bisa diimplementasikan untuk porta TCP saja.
Dukungan untuk protokol UDP bisa dilihat di
issue 47862.
Laman ini menjelaskan bagaimana membuat Load Balancer Eksternal.
Catatan: Fitur ini hanya tersedia untuk penyedia cloud atau lingkungan yang mendukung load balancer eksternal.
Ketika membuat Service, kamu mempunyai opsi untuk tersambung dengan jaringan cloud load balancer secara otomatis.
Hal ini menyediakan akses eksternal alamat IP yang dapat mengirim lalu lintas melalui porta yang tepat pada klaster Node kamu
asalkan klaster kamu beroperasi pada lingkungan yang mendukung dan terkonfigurasi dengan paket penyedia cloud load balancer yang benar.
Untuk informasi mengenai penyediaan dan penggunaan sumber daya Ingress yang dapat memberikan
servis URL yang dapat dijangkau secara eksternal, penyeimbang beban lalu lintas, terminasi SSL, dll.,
silahkan cek dokumentasi Ingress
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Kamu dapat membuat Service dengan perintah kubectl expose dan
flag--type=LoadBalancer:
kubectl expose rc example --port=8765 --target-port=9376\
--name=example-service --type=LoadBalancer
Perintah ini membuat Service baru dengan menggunakan pemilih yang sama dengan
sumber daya yang dirujuk (dalam hal contoh di atas, ReplicationController bernama example).
Alamat IP tercantum di sebelah LoadBalancer Ingress.
Catatan: Jika kamu menjalankan Service dari Minikube, kamu dapat menemukan alamat IP dan porta yang ditetapkan dengan:
minikube service example-service --url
Preservasi IP sumber klien
Implementasi dari fitur ini menyebabkan sumber IP yang terlihat pada Container
target bukan sebagai sumber IP asli dari klien. Untuk mengaktifkan
preservasi IP klien, bidang berikut dapat dikonfigurasikan di dalam
spek Service (mendukung lingkungan GCE/Google Kubernetes Engine):
service.spec.externalTrafficPolicy - menunjukkan jika Service menginginkan rute lalu lintas
eksternal ke titik akhir node-local atau cluster-wide. Terdapat dua opsi yang tersedia:
Cluster (bawaan) dan Local. Cluster mengaburkan sumber IP klien dan mungkin menyebabkan
hop kedua ke Node berbeda, namun harus mempunyai penyebaran beban (load-spreading) yang baik secara keseluruhan.
Local mempreservasi sumber IP client dan menghindari hop kedua LoadBalancer dan Service dengan tipe NodePort, namun
resiko berpotensi penyebaran lalu lintas yang tidak merata.
service.spec.healthCheckNodePort - menentukan pemeriksaan kesehatan porta dari sebuah Node (angka porta numerik) untuk Service.
Jika healthCheckNodePort tidak ditentukan, pengendali Service mengalokasi
porta dari rentang NodePort dari klaster kamu. Kamu dapat mengonfigurasi
rentangan tersebut dari pengaturan opsi barisan perintah API server,
--service-node-port-range. Hal itu menggunakan nilai healthCheckNodePort pengguna spesifik
jika ditentukan oleh klien. Hal itu dapat berefek hanya ketika type diset ke LoadBalancer dan
externalTrafficPolicy diset ke Local.
Pengaturan externalTrafficPolicy ke Local pada berkas konfigurasi Service mengaktifkan
fitur ini.
Pada kasus biasa, sumber daya load balancer yang berkorelasi pada penyedia cloud perlu
dibersihkan segera setelah Service bertipe LoadBalancer dihapus. Namun perlu diketahui
bahwa terdapat kasus tepi dimana sumber daya cloud yatim piatu (orphaned) setelah
Service yang berkaitan dihapus. Finalizer Protection untuk Service LoadBalancer
diperkenalkan untuk mencegah hal ini terjadi. Dengan menggunakan finalizers, sebuah sumber daya Service
tidak akan pernah dihapus hingga sumber daya load balancer yang berkorelasi juga dihapus.
Secara khusus, jika Service mempunyai type LoadBalancer, pengendali Service akan melekatkan
finalizer bernama service.kubernetes.io/load-balancer-cleanup.
Finalizer hanya akan dihapus setelah sumber daya load balancer dibersihkan.
Hal ini mencegah sumber daya load balancer yang teruntai bahkan setelah kasus tepi seperti
pengendali Service berhenti.
Penyedia Load Balancer Eksternal
Penting untuk dicatat bahwa jalur data untuk fungsionalitas ini disediakan oleh load balancer eksternal ke klaster Kubernetes.
Ketika Service type diset LoadBalancer, Kubernetes menyediakan fungsionalitas yang ekuivalen dengan type sebanding ClusterIP
ke berbagai Pod di dalam klaster dan mengekstensinya dengan pemrograman (eksternal dari Kubernetes) load balancer dengan entri pada Pod
Kubernetes. Pengendali Service Kubernetes mengotomasi pembuatan load balancer eksternal, cek kesehatan (jika dibutuhkan),
dinding api (firewall) (jika dibutuhkan), dan mengambil IP eksternal yang dialokasikan oleh penyedia cloud dan mengisinya pada objek Service.
Peringatan dan and Limitasi ketika preservasi sumber IP
Load balancers GCE/AWS tidak menyediakan bobot pada kolam targetnya (target pools). Hal ini bukan merupakan isu dengan aturan kube-proxy
Load balancer lama yang akan menyeimbangkan semua titik akhir dengan benar.
Dengan fungsionalitas yang baru, lalu lintas eksternal tidak menyeimbangkan beban secara merata pada seluruh Pod, namun
sebaliknya menyeimbangkan secara merata pada level Node (karena GCE/AWS dan implementasi load balancer eksternal lainnya tidak mempunyai
kemampuan untuk menentukan bobot setiap Node, mereka menyeimbangkan secara merata pada semua Node target, mengabaikan jumlah
Pod pada tiap Node).
Namun demikian, kita dapat menyatakan bahwa NumServicePods << NumNodes atau NumServicePods >> NumNodes, distribusi yang cukup mendekati
sama akan terlihat, meski tanpa bobot.
Sekali load balancer eksternal menyediakan bobot, fungsionalitas ini dapat ditambahkan pada jalur pemrograman load balancer.
Pekerjaan Masa Depan: Tidak adanya dukungan untuk bobot yang disediakan untuk rilis 1.4, namun dapat ditambahkan di masa mendatang
Pod internal ke lalu lintas Pod harus berperilaku sama seperti Service ClusterIP, dengan probabilitas yang sama pada seluruh Pod.
8.6 - Membuat Daftar Semua Image Container yang Berjalan dalam Klaster
Laman ini menunjukkan cara menggunakan kubectl untuk membuat daftar semua image Container
untuk Pod yang berjalan dalam sebuah klaster.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Dalam latihan ini kamu akan menggunakan kubectl untuk mengambil semua Pod yang
berjalan dalam sebuah klaster, dan mengubah format keluarannya untuk melihat daftar
Container untuk masing-masing Pod.
Membuat daftar semua image Container pada semua Namespace
Silakan ambil semua Pod dalam Namespace dengan menggunakan perintah kubectl get pods --all-namespaces
Silakan format keluarannya agar hanya menyertakan daftar nama image dari Container
dengan menggunakan perintah -o jsonpath={.items[*].spec.containers[*].image}. Perintah ini akan mem-parsing fieldimage dari keluaran json yang dihasilkan.
Silakan lihat referensi jsonpath
untuk informasi lebih lanjut tentang cara menggunakan jsonpath.
Silakan format keluaran dengan menggunakan peralatan standar: tr, sort, uniq
Gunakan tr untuk mengganti spasi dengan garis baru
Perintah di atas secara berulang akan mengembalikan semua field bernama image
dari semua poin yang dikembalikan.
Sebagai pilihan, dimungkinkan juga untuk menggunakan jalur (path) absolut ke field image
di dalam Pod. Hal ini memastikan field yang diambil benar
bahkan ketika nama field tersebut diulangi,
misalnya banyak field disebut dengan name dalam sebuah poin yang diberikan:
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}"
Jsonpath dapat diartikan sebagai berikut:
.items[*]: untuk setiap nilai yang dihasilkan
.spec: untuk mendapatkan spesifikasi
.containers[*]: untuk setiap Container
.image: untuk mendapatkan image
Catatan: Pada saat mengambil sebuah Pod berdasarkan namanya, misalnya kubectl get pod nginx,
bagian .items[*] dari jalur harus dihilangkan karena hanya akan menghasilkan sebuah Pod
sebagai keluarannya, bukan daftar dari semua Pod.
Membuat daftar image Container berdasarkan Pod
Format dapat dikontrol lebih lanjut dengan menggunakan operasi range untuk
melakukan iterasi untuk setiap elemen secara individual.
Membuat daftar image yang difilter berdasarkan label dari Pod
Untuk menargetkan hanya Pod yang cocok dengan label tertentu saja, gunakan tanda -l. Filter
dibawah ini akan menghasilkan Pod dengan label yang cocok dengan app=nginx.
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" -l app=nginx
Membuat daftar image Container yang difilter berdasarkan Namespace Pod
Untuk hanya menargetkan Pod pada Namespace tertentu, gunakankan tanda Namespace. Filter
dibawah ini hanya menyaring Pod pada Namespace kube-system.
kubectl get pods --namespace kube-system -o jsonpath="{.items[*].spec.containers[*].image}"
Membuat daftar image Container dengan menggunakan go-template sebagai alternatif dari jsonpath
Sebagai alternatif untuk jsonpath, kubectl mendukung penggunaan go-template
untuk memformat keluaran seperti berikut:
kubectl get pods --all-namespaces -o go-template --template="{{range .items}}{{range .spec.containers}}{{.image}} {{end}}{{end}}"
Mengatur pemantauan dan pencatatan untuk memecahkan masalah klaster, atau men-debug aplikasi yang terkontainerisasi.
9.1 - Introspeksi dan _Debugging_ Aplikasi
Setelah aplikasi kamu berjalan, kamu pasti perlu untuk men-debug masalah yang ada di dalamnya.
Sebelumnya telah dijelaskan bagaimana kamu dapat menggunakan kubectl get pods untuk mengambil informasi status sederhana tentang
Pod kamu. Namun ada sejumlah cara untuk mendapatkan lebih banyak informasi tentang aplikasi kamu.
Menggunakan kubectl describe pod untuk mengambil detil informasi Pod
Dalam contoh ini, kamu menggunakan Deployment untuk membuat dua buah Pod, yang hampir sama dengan contoh sebelumnya.
NAME READY STATUS RESTARTS AGE
nginx-deployment-1006230814-6winp 1/1 Running 0 11s
nginx-deployment-1006230814-fmgu3 1/1 Running 0 11s
Kamu dapat memperoleh lebih banyak informasi tentang masing-masing Pod ini dengan menggunakan perintah kubectl describe pod. Sebagai contoh:
kubectl describe pod nginx-deployment-1006230814-6winp
Name: nginx-deployment-1006230814-6winp
Namespace: default
Node: kubernetes-node-wul5/10.240.0.9
Start Time: Thu, 24 Mar 2016 01:39:49 +0000
Labels: app=nginx,pod-template-hash=1006230814
Annotations: kubernetes.io/created-by={"kind":"SerializedReference","apiVersion":"v1","reference":{"kind":"ReplicaSet","namespace":"default","name":"nginx-deployment-1956810328","uid":"14e607e7-8ba1-11e7-b5cb-fa16" ...
Status: Running
IP: 10.244.0.6
Controllers: ReplicaSet/nginx-deployment-1006230814
Containers:
nginx:
Container ID: docker://90315cc9f513c724e9957a4788d3e625a078de84750f244a40f97ae355eb1149
Image: nginx
Image ID: docker://6f62f48c4e55d700cf3eb1b5e33fa051802986b77b874cc351cce539e5163707
Port: 80/TCP
QoS Tier:
cpu: Guaranteed
memory: Guaranteed
Limits:
cpu: 500m
memory: 128Mi
Requests:
memory: 128Mi
cpu: 500m
State: Running
Started: Thu, 24 Mar 2016 01:39:51 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-5kdvl (ro)
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
default-token-4bcbi:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4bcbi
Optional: false
QoS Class: Guaranteed
Node-Selectors: <none>
Tolerations: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
54s 54s 1 {default-scheduler } Normal Scheduled Successfully assigned nginx-deployment-1006230814-6winp to kubernetes-node-wul5
54s 54s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Pulling pulling image "nginx"
53s 53s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Pulled Successfully pulled image "nginx"
53s 53s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Created Created container with docker id 90315cc9f513
53s 53s 1 {kubelet kubernetes-node-wul5} spec.containers{nginx} Normal Started Started container with docker id 90315cc9f513
Di sini kamu dapat melihat informasi konfigurasi tentang Container dan Pod (label, kebutuhan resource, dll.), serta informasi status tentang Container dan Pod (status, kesiapan, berapa kali restart, event, dll.) .
Keadaan (state) Container merupakan salah satu dari keadaan Waiting, Running, atau Terminated. Tergantung dari keadaannya, informasi tambahan akan diberikan - di sini kamu dapat melihat bahwa untuk Container dalam keadaan running, sistem memberi tahu kamu kapan Container tersebut mulai dijalankan.
Ready memberi tahu kepada kamu apakah Container berhasil melewati pemeriksaan kesiapan terakhir. (Dalam kasus ini, Container tidak memiliki pemeriksaan kesiapan yang dikonfigurasi; Container dianggap selalu siap jika tidak ada pemeriksaan kesiapan yang dikonfigurasi.)
Jumlah restart memberi tahu kamu berapa kali Container telah dimulai ulang; informasi ini dapat berguna untuk mendeteksi kemacetan tertutup (crash loop) dalam Container yang dikonfigurasi dengan nilai restart policy 'always.'.
Saat ini, satu-satunya kondisi yang terkait dengan Pod adalah kondisi Binary Ready, yang menunjukkan bahwa Pod tersebut dapat melayani permintaan dan harus ditambahkan ke kumpulan penyeimbang beban (load balancing) dari semua Service yang sesuai.
Terakhir, kamu melihat catatan (log) peristiwa terbaru yang terkait dengan Pod kamu. Sistem mengompresi beberapa peristiwa yang identik dengan menunjukkan kapan pertama dan terakhir kali peristiwa itu dilihat dan berapa kali peristiwa itu dilihat. "From" menunjukkan komponen yang mencatat peristiwa, "SubobjectPath" memberi tahu kamu objek mana (mis. Container dalam pod) yang dimaksud, dan "Reason" dan "Message" memberi tahu kamu apa yang sudah terjadi.
Contoh: Men-debug Pod yang Pending
Skenario umum yang bisa kamu deteksi menggunakan peristiwa (event) adalah saat kamu telah membuat Pod yang tidak muat di Node mana pun. Misalnya, karena Pod mungkin meminta lebih banyak sumber daya yang tersedia dalam Node mana pun, atau mungkin Pod menentukan label selector yang tidak sesuai dengan Node mana pun. Katakanlah kamu sebelumnya membuat Deployment dengan 5 replika (bukan 2) dan meminta 600 millicore, bukan 500, pada klaster dengan empat Node di mana setiap mesin (virtual) memiliki 1 CPU. Sehingga salah satu Pod tidak akan bisa dijadwalkan. (Perhatikan bahwa Pod addon seperti fluentd, skydns, dll., yang berjalan di setiap Node pada klaster, tidak bisa dijadwalkan jika kamu meminta sebanyak 1000 millicore.)
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-1006230814-6winp 1/1 Running 0 7m
nginx-deployment-1006230814-fmgu3 1/1 Running 0 7m
nginx-deployment-1370807587-6ekbw 1/1 Running 0 1m
nginx-deployment-1370807587-fg172 0/1 Pending 0 1m
nginx-deployment-1370807587-fz9sd 0/1 Pending 0 1m
Untuk mencari sebab kenapa Pod nginx-deployment-1370807587-fz9sd tidak berjalan, kamu dapat menggunakan kubectl describe pod pada Pod yang pending dan melihat setiap peristiwa yang terjadi di dalamnya:
kubectl describe pod nginx-deployment-1370807587-fz9sd
Name: nginx-deployment-1370807587-fz9sd
Namespace: default
Node: /
Labels: app=nginx,pod-template-hash=1370807587
Status: Pending
IP:
Controllers: ReplicaSet/nginx-deployment-1370807587
Containers:
nginx:
Image: nginx
Port: 80/TCP
QoS Tier:
memory: Guaranteed
cpu: Guaranteed
Limits:
cpu: 1
memory: 128Mi
Requests:
cpu: 1
memory: 128Mi
Environment Variables:
Volumes:
default-token-4bcbi:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-4bcbi
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 48s 7 {default-scheduler } Warning FailedScheduling pod (nginx-deployment-1370807587-fz9sd) failed to fit in any node
fit failure on node (kubernetes-node-6ta5): Node didn't have enough resource: CPU, requested: 1000, used: 1420, capacity: 2000
fit failure on node (kubernetes-node-wul5): Node didn't have enough resource: CPU, requested: 1000, used: 1100, capacity: 2000
Di sini kamu dapat melihat peristiwa yang dibuat oleh penjadwal yang mengatakan bahwa Pod gagal dijadwalkan karena alasan FailedScheduling (dan mungkin karena sebab yang lainnya). Pesan tersebut memberi tahu kamu bahwa tidak ada cukup sumber daya untuk Pod pada salah satu Node.
Untuk memperbaiki situasi ini, kamu dapat menggunakan kubectl scale untuk memperbarui Deployment kamu untuk menentukan empat replika atau yang lebih kecil. (Atau kamu bisa membiarkan satu Pod tertunda, dimana hal ini tidak berbahaya.)
Peristiwa seperti yang kamu lihat di bagian akhir keluaran dari perintah kubectl description pod akan tetap ada dalam etcd dan memberikan informasi tingkat tinggi tentang apa yang terjadi pada klaster. Untuk melihat daftar semua peristiwa kamu dapat menggunakan perintah
kubectl get events
tetapi kamu harus ingat bahwa peristiwa bersifat Namespace. Artinya, jika kamu tertarik dengan peristiwa untuk beberapa objek dalam Namespace (misalnya, apa yang terjadi dengan Pod pada Namespace my-namespace), kamu perlu secara eksplisit menyebutkan Namespace tersebut pada perintah:
kubectl get events --namespace=my-namespace
Untuk melihat peristiwa dari semua Namespace, kamu dapat menggunakan argumen --all-namespaces.
Sebagai tambahan dari perintah kubectl describe pod, cara lain untuk mendapatkan informasi tambahan tentang sebuah Pod (selain yang disediakan oleh kubectl get pod) adalah dengan meneruskan flag format keluaran -o yaml ke perintah kubectl get pod. Ini akan memberikan kamu lebih banyak informasi dalam format YAML daripada kubectl describe pod--semua informasi dasar yang dimiliki sistem tentang Pod. Di sini kamu akan melihat hal-hal seperti anotasi (yang merupakan metadata nilai kunci tanpa batasan label, yang digunakan secara internal oleh komponen sistem Kubernetes), kebijakan mulai ulang, porta, dan volume.
kubectl get pod nginx-deployment-1006230814-6winp -o yaml
Contoh: Men-debug Node yang mati/tidak terjangkau (down/unreachable)
Terkadang saat men-debug melihat status sebuah Node akan sangat berguna - misalnya, karena kamu telah melihat perilaku aneh dari sebuah Pod yang sedang berjalan pada Node tersebut, atau untuk mencari tahu mengapa sebuah Pod tidak dapat dijadwalkan ke dalam Node tersebut. Seperti pada Pod, kamu dapat menggunakan perintah kubectl description node dan kubectl get node -o yaml untuk mengambil informasi mendetil tentang Node. Misalnya, disini kamu akan melihat jika sebuah Node sedang mati (terputus dari jaringan, atau kubelet mati dan tidak mau restart, dll.). Perhatikan peristiwa yang menunjukkan Node tersebut NotReady, dan juga perhatikan bahwa Pod tidak lagi berjalan (mereka akan dikeluarkan setelah lima menit berstatus NotReady).
kubectl get nodes
NAME STATUS ROLES AGE VERSION
kubernetes-node-861h NotReady <none> 1h v1.13.0
kubernetes-node-bols Ready <none> 1h v1.13.0
kubernetes-node-st6x Ready <none> 1h v1.13.0
kubernetes-node-unaj Ready <none> 1h v1.13.0
9.2 - Mendapatkan Shell Untuk Masuk ke Container yang Sedang Berjalan
Laman ini menunjukkan bagaimana cara menggunakan kubectl exec untuk
mendapatkan shell untuk masuk ke dalam Container yang sedang berjalan.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Mendapatkan sebuah shell untuk masuk ke sebuah Container
Dalam latihan ini, kamu perlu membuat Pod yang hanya memiliki satu Container saja. Container
tersebut menjalankan image nginx. Berikut ini adalah berkas konfigurasi untuk Pod tersebut:
Catatan: Simbol tanda hubung ganda "--" digunakan untuk memisahkan antara argumen perintah yang ingin kamu eksekusi pada Container dan argumen dari kubectl itu sendiri.
Di dalam shell kamu, perlihatkan isi dari direktori root:
root@shell-demo:/# ls /
Di dalam shell kamu, cobalah perintah-perintah yang lainnya. Berikut beberapa contohnya:
Lihat kembali berkas konfigurasi untuk Pod kamu. Pod
memiliki volume emptyDir, dan Container melakukan pemasangan (mounting) untuk volume tersebut
pada /usr/share/nginx/html.
Pada shell kamu, buatlah berkas index.html dalam direktori /usr/share/nginx/html:
Keluarannya akan menunjukkan teks yang kamu tulis pada berkas index.html.
Hello shell demo
Setelah kamu selesai dengan shell kamu, ketiklah exit.
Menjalankan perintah individu di dalam sebuah Container
Pada jendela (window) perintah biasa, bukan pada shell kamu di dalam Container,
lihatlah daftar variabel lingkungan (environment variable) pada Container yang sedang berjalan:
kubectl exec shell-demo env
Cobalah dengan menjalankan perintah lainnya. Berikut beberapa contohnya:
kubectl exec shell-demo ps aux
kubectl exec shell-demo ls /
kubectl exec shell-demo cat /proc/1/mounts
Membuka sebuah shell ketika sebuah Pod memiliki lebih dari satu Container
Jika sebuah Pod memiliki lebih dari satu Container, gunakanlah --container atau -c untuk
menentukan Container yang dimaksud pada perintah kubectl exec. Sebagai contoh,
misalkan kamu memiliki Pod yang bernama my-pod, dan Pod tersebut memiliki dua Container
yang bernama main-app dan helper-app. Perintah berikut ini akan membuka sebuah
shell ke Container dengan nama main-app.
Untuk melukan penyekalaan aplikasi dan memberikan Service yang handal, kamu perlu
memahami bagaimana aplikasi berperilaku ketika aplikasi tersebut digelar (deploy). Kamu bisa memeriksa
kinerja aplikasi dalam klaster Kubernetes dengan memeriksa Container,
Pod, Service, dan
karakteristik klaster secara keseluruhan. Kubernetes memberikan detail
informasi tentang penggunaan sumber daya dari aplikasi pada setiap level ini.
Informasi ini memungkinkan kamu untuk mengevaluasi kinerja aplikasi kamu dan
mengevaluasi di mana kemacetan dapat dihilangkan untuk meningkatkan kinerja secara keseluruhan.
Di Kubernetes, pemantauan aplikasi tidak bergantung pada satu solusi pemantauan saja. Pada klaster baru, kamu bisa menggunakan pipelinemetrik sumber daya atau pipelinemetrik penuh untuk mengumpulkan statistik pemantauan.
Pipeline Metrik Sumber Daya
Pipeline metrik sumber daya menyediakan sekumpulan metrik terbatas yang terkait dengan
komponen-komponen klaster seperti controllerHorizontalPodAutoscaler, begitu juga dengan utilitas kubectl top.
Metrik ini dikumpulkan oleh memori yang ringan, jangka pendek, dalam
metrics-server dan
diekspos ke API metrics.k8s.io.
Metrics-server menemukan semua Node dalam klaster dan
bertanya ke setiap
kubelet dari Node tentang penggunaan CPU dan
memori. Kubelet bertindak sebagai jembatan antara control plane Kubernetes dan
Node, mengelola Pod dan Container yang berjalan pada sebuah mesin. Kubelet
menerjemahkan setiap Pod ke Container yang menyusunnya dan mengambil masing-masing
statistik penggunaan untuk setiap Container dari runtime Container melalui
antarmuka runtime Container. Kubelet mengambil informasi ini dari cAdvisor yang terintegrasi
untuk pengintegrasian Docker yang lama. Hal ini yang kemudian memperlihatkan
statistik penggunaan sumber daya dari kumpulan Pod melalui API sumber daya metrics-server.
API ini disediakan pada /metrics/resource/v1beta1 pada kubelet yang terautentikasi dan
porta read-only.
Pipeline Metrik Penuh
Pipeline metrik penuh memberi kamu akses ke metrik yang lebih banyak. Kubernetes bisa
menanggapi metrik ini secara otomatis dengan mengubah skala atau mengadaptasi klaster
berdasarkan kondisi saat ini, dengan menggunakan mekanisme seperti HorizontalPodAutoscaler.
Pipeline pemantauan mengambil metrik dari kubelet dan
kemudian memgekspos ke Kubernetes melalui adaptor dengan mengimplementasikan salah satu dari API
custom.metrics.k8s.io atau API external.metrics.k8s.io.
Prometheus, sebuah proyek CNCF, yang dapat secara alami memonitor Kubernetes, Node, dan Prometheus itu sendiri.
Proyek pipeline metrik penuh yang bukan merupakan bagian dari CNCF berada di luar ruang lingkup dari dokumentasi Kubernetes.
10 - TLS
10.1 - Kelola Sertifikat TLS Pada Klaster
Kubernetes menyediakan API certificates.k8s.io yang memungkinkan kamu membuat sertifikat
TLS yang ditandatangani oleh Otoritas Sertifikat (CA) yang kamu kendalikan. CA dan sertifikat ini
bisa digunakan oleh workload untuk membangun kepercayaan.
API certificates.k8s.io menggunakan protokol yang mirip dengan konsep ACME.
Catatan: Sertifikat yang dibuat menggunakan API certificates.k8s.io ditandatangani oleh CA
khusus. Ini memungkinkan untuk mengkonfigurasi klaster kamu agar menggunakan CA root klaster untuk tujuan ini,
namun jangan pernah mengandalkan ini. Jangan berasumsi bahwa sertifikat ini akan melakukan validasi
dengan CA root klaster
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Mempercayai CA khusus dari aplikasi yang berjalan sebagai Pod biasanya memerlukan
beberapa tambahan konfigurasi aplikasi. Kamu harus menambahkan bundel sertifikat CA
ke daftar sertifikat CA yang dipercaya klien atau server TLS.
Misalnya, kamu akan melakukan ini dengan konfigurasi TLS golang dengan mengurai rantai sertifikat
dan menambahkan sertifikat yang diurai ke RootCAs di structtls.Config.
Kamu bisa mendistribusikan sertifikat CA sebagai sebuah
ConfigMap yang bisa diakses oleh Pod kamu.
Meminta Sertifikat
Bagian berikut mendemonstrasikan cara membuat sertifikat TLS untuk sebuah
Service kubernetes yang diakses melalui DNS.
Catatan: Tutorial ini menggunakan CFSSL: PKI dan peralatan TLS dari Cloudflare klik disini untuk mengetahui lebih jauh.
192.0.2.24 adalah klaster IP Service,
my-svc.my-namespace.svc.cluster.local adalah nama DNS Service,
10.0.34.2 adalah IP Pod dan my-pod.my-namespace.pod.cluster.local
adalah nama DNS Pod. Kamu akan melihat keluaran berikut:
Perintah ini menghasilkan dua berkas; Ini menghasilkan server.csr yang berisi permintaan sertifikasi PEM
tersandi pkcs#10,
dan server-key.pem yang berisi PEM kunci yang tersandi untuk sertifikat yang
masih harus dibuat.
Membuat objek CertificateSigningRequest untuk dikirim ke API Kubernetes
Buat sebuah yaml CSR dan kirim ke API Server dengan menggunakan perintah berikut:
Perhatikan bahwa berkas server.csr yang dibuat pada langkah 1 merupakan base64 tersandi
dan disimpan di field.spec.request. Kami juga meminta
sertifikat dengan penggunaan kunci "digital signature", "key enchiperment", dan "server
auth". Kami mendukung semua penggunaan kunci dan penggunaan kunci yang diperpanjang yang terdaftar
di sini
sehingga kamu dapat meminta sertifikat klien dan sertifikat lain menggunakan
API yang sama.
CSR semestinya bisa dilihat dari API pada status Pending. Kamu bisa melihatnya dengan menjalankan:
kubectl describe csr my-svc.my-namespace
Name: my-svc.my-namespace
Labels: <none>
Annotations: <none>
CreationTimestamp: Tue, 21 Mar 2017 07:03:51 -0700
Requesting User: yourname@example.com
Status: Pending
Subject:
Common Name: my-svc.my-namespace.svc.cluster.local
Serial Number:
Subject Alternative Names:
DNS Names: my-svc.my-namespace.svc.cluster.local
IP Addresses: 192.0.2.24
10.0.34.2
Events: <none>
Mendapatkan Persetujuan CertificateSigningRequest
Penyetujuan CertificateSigningRequest dapat dilakukan dengan otomatis
atau dilakukan sekali oleh administrator klaster. Informasi lebih lanjut tentang
apa yang terjadi dibahas dibawah ini.
Unduh dan Gunakan Sertifikat
Setelah CSR ditandatangani dan disetujui, kamu akan melihat:
kubectl get csr
NAME AGE REQUESTOR CONDITION
my-svc.my-namespace 10m yourname@example.com Approved,Issued
Kamu bisa mengundur sertifikat yang telah diterbitkan dan menyimpannya ke berkas
server.crt dengan menggunakan perintah berikut:
Sekarang kamu bisa menggunakan server.crt dan server-key.pem sebagai pasangan
kunci untuk memulai server HTTPS kamu.
Penyetujuan CertificateSigningRequest
Administrator Kubernetes (dengan izin yang cukup) dapat menyetujui secara manual
(atau menolak) Certificate Signing Requests dengan menggunakan perintah kubectl certificate approve dan kubectl certificate deny. Namun jika kamu bermaksud
untuk menggunakan API ini secara sering, kamu dapat mempertimbangkan untuk menulis
Certificate controller otomatis.
Baik itu mesin atau manusia yang menggunakan kubectl seperti di atas, peran pemberi persetujuan adalah
untuk memverifikasi bahwa CSR memenuhi dua persyaratan:
Subjek CSR mengontrol kunci pribadi yang digunakan untuk menandatangani CSR. Ini
mengatasi ancaman pihak ketiga yang menyamar sebagai subjek resmi.
Pada contoh di atas, langkah ini adalah untuk memverifikasi bahwa Pod mengontrol
kunci pribadi yang digunakan untuk menghasilkan CSR.
Subjek CSR berwenang untuk bertindak dalam konteks yang diminta. Ini
mengatasi ancaman subjek yang tidak diinginkan bergabung dengan klaster. Dalam
contoh di atas, langkah ini untuk memverifikasi bahwa Pod diizinkan
berpartisipasi dalam Service yang diminta.
Jika dan hanya jika kedua persyaratan ini dipenuhi, pemberi persetujuan harus menyetujui
CSR dan sebaliknya harus menolak CSR.
Peringatan tentang Izin Persetujuan
Kemampuan untuk menyetujui CSR menentukan siapa yang mempercayai siapa di dalam lingkungan kamu.
Kemampuan untuk menyetujui CSR tersebut seharusnya tidak diberikan secara luas.
Persyaratan tantangan yang disebutkan di bagian sebelumnya dan
dampak dari mengeluarkan sertifikat khusus, harus sepenuhnya dipahami
sebelum memberikan izin ini.
Catatan Untuk Administrator Klaster
Tutorial ini mengasumsikan bahwa penanda tangan diatur untuk melayani API sertifikat.
Kubernetes controller manager menyediakan implementasi bawaan dari penanda tangan. Untuk
mengaktifkan, berikan parameter --cluster-signed-cert-file dan
--cluster-signed-key-file ke controller manager dengan path ke
pasangan kunci CA kamu.
11 - Mengelola Daemon Klaster
Melakukan tugas-tugas umum untuk mengelola sebuah DaemonSet, misalnya rolling update.
11.1 - Melakukan Rollback pada DaemonSet
Laman ini memperlihatkan bagaimana caranya untuk melakukan rollback pada sebuah DaemonSet.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl
juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu
belum memiliki klaster, kamu dapat membuatnya dengan menggunakan
minikube,
atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Alasan perubahan (change cause) kolom di atas merupakan salinan dari anotasi kubernetes.io/change-cause yang berkaitan dengan revisi pada DaemonSet. Kamu boleh menyetel flag--record=true melalui kubectl untuk merekam perintah yang dijalankan akibat dari anotasi alasan perubahan.
Untuk melihat detail dari revisi tertentu, jalankan perintah di bawah ini:
kubectl rollout history daemonset <daemonset-name> --revision=1
Perintah tersebut memberikan detail soal nomor revisi tertentu:
# Tentukan nomor revisi yang kamu dapatkan dari Langkah 1 melalui --to-revision
kubectl rollout undo daemonset <nama-daemonset> --to-revision=<nomor-revisi>
Jika telah berhasil, perintah tersebut akan memberikan keluaran berikut:
daemonset "<nama-daemonset>" rolled back
Catatan: Jika flag--to-revision tidak diberikan, maka kubectl akan memilihkan revisi yang terakhir.
Langkah 3: Lihat progres pada saat rollback DaemonSet
Perintah kubectl rollout undo daemonset memberitahu server untuk memulai rollback DaemonSet.
Rollback sebenarnya terjadi secara asynchronous di dalam klaster _control plane_.
Perintah di bawah ini dilakukan untuk melihat progres dari rollback:
kubectl rollout status ds/<nama-daemonset>
Ketika rollback telah selesai dilakukan, keluaran di bawah akan ditampilkan:
daemonset "<nama-daemonset>" successfully rolled out
Memahami revisi DaemonSet
Pada langkah kubectl rollout history sebelumnya, kamu telah mendapatkan
daftar revisi DaemonSet. Setiap revisi disimpan di dalam sumber daya bernama ControllerRevision.
Untuk melihat apa yang disimpan pada setiap revisi, dapatkan sumber daya mentah (raw) dari
revisi DaemonSet:
kubectl get controllerrevision -l <kunci-selektor-daemonset>=<nilai-selektor-daemonset>
Perintah di atas akan mengembalikan daftar ControllerRevision:
NAME CONTROLLER REVISION AGE
<nama-daemonset>-<hash-revisi> DaemonSet/<nama-daemonset> 1 1h
<nama-daemonset>-<hash-revisi> DaemonSet/<nama-daemonset> 2 1h
Setiap ControllerRevision menyimpan anotasi dan templat dari sebuah revisi DaemonSet.
Perintah kubectl rollout undo mengambil ControllerRevision yang spesifik dan mengganti templat
DaemonSet dengan templat yang tersimpan pada ControllerRevision.
Perintah kubectl rollout undo sama seperti untuk memperbarui templat
DaemonSet ke revisi sebelumnya dengan menggunakan perintah lainnya, seperti kubectl edit atau kubectl apply.
Catatan: Revisi DaemonSet hanya bisa roll ke depan. Artinya, setelah rollback selesai dilakukan,
nomor revisi dari ControllerRevision (field.revision) yang sedang di-rollback akan maju ke depan.
Misalnya, jika kamu memiliki revisi 1 dan 2 pada sistem, lalu rollback dari revisi 2 ke revisi 1,
ControllerRevision dengan .revision: 1 akan menjadi .revision: 3.